


ChatGPTが登場してから1年が経ち、再び新興企業によって大規模言語モデル(LLM)の可能性が広がろうとしている。今回はフランスの設立から1年も経っていない企業から始まっている。→過去の「シリコンバレー101」の回はこちらを参照。
Mixtralが注目される理由
下はHugging FaceのLMSYS Chatbot Arenaリーダーボード(1月26日更新)である。
-
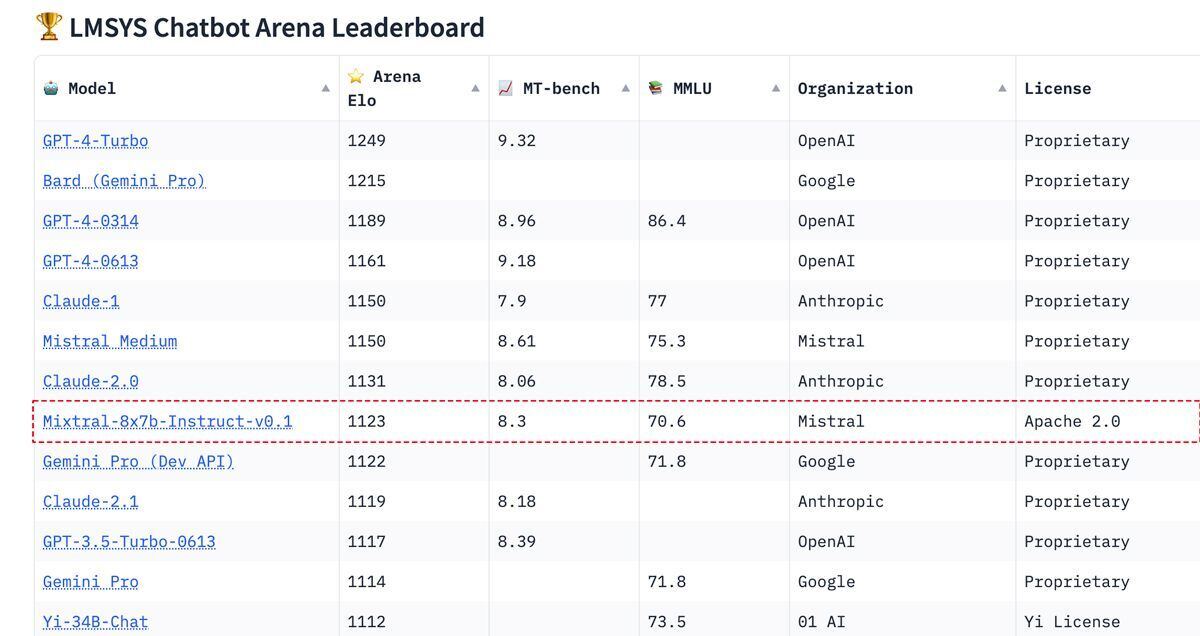
実力の評価にさまざまな要素がからむLLM、LMSYSリーダーボードではチェスのELOレーティングに似た投票システムを採用。相対評価でモデルを比較し、ポイントを割り当てている。

クローズド(プロプリエタリ)なモデルで占められているトップ10に、オープンソースのモデルで唯一、昨年12月にリリースされた「Mixtral 8x7B」が入っている。開発しているのは、Deepmind、Metaに在籍していた研究者3人が昨年4月に設立したMistral AIである。
LLMの開発競争は激化の一途であり、市場で頭角をあらわすためのアピール合戦も加熱している。そうした中で、Mistral AIは同社のLLMリリースのマーケティングに資金や労力をほとんど費やしていない。
Discordでコミュニティをサポートし、あとはブログ記事を公開した程度で、BitTorrentのマグネットリンクとHugging Faceを通じて最初の言語モデル「Mistral 7B」をリリースした。驚くことに、それだけで瞬く間に存在が広く知られ、Mistral 7Bのリリース成功で評価額が約20億ドルに上昇。Andreessen Horowitzが主導する最新の資金調達ラウンドで3億8,500万ユーロを調達した。


Mixtralが注目を集めているのは、その小さなサイズに比して強力なパフォーマンス、そしてオープンソース(Apache 2ライセンス)であることだ。GPT-3やGPT-4などは、1000億パラメータ以上の巨大なモデルであり、ホストするには大規模なサーバインフラを必要とする。
一方、Llama 2のような小さなモデルはさまざまなサイズでリリースされており、最大のもので700億パラメータだが、それでも実行にはかなりのハードウェアを必要とする。
昨年9月にMistral 7Bが登場した時に、LLMとしては小さなサイズから懐疑的な見方が多かったが、すぐにその価値が明らかになった。わずか70億パラメータで700億パラメータ・モデルと競い合えるパフォーマンスを発揮してトップ10にランクイン。Mistral-7Bのファインチューンである「Starling-LM-7B-alpha」は、GPT-3の亜種やLlama 2の700億パラメータ・モデルを上回った。
その小さなサイズのおかげで、Mistralは、Macや一部のiPhoneのようなデバイスでローカル実行できる。しかも、Apache 2.0ライセンスで利用しやすい。オープンソースのLLMをダウンロードして実験し、改良して知識を共有する、コミュニティの活発な活動に拍車をかけた。
そして12月に、Mixture of Experts (MoE)をとり入れたMixtral 8x7Bが登場した。ライセンスはApache 2.0。数学、コーディングなど、さまざまな領域に特化した専門的なニューラルネットワークを複数用意し、それらを切り替えながら学習・推論する。
複雑な問題を、より小さく管理しやすいサブ問題に分割することで単純化し、それぞれを専門化したサブモデルやエキスパートに対応させる。これは特定の業務を得意とするスペシャリストのチームを持つことに似ており、MoEモデルでは各エキスパートがデータやタスクの特定のサブセットに集中することで、幅広いタスクをより効率的かつ正確に処理できる。Mixtral 8x7Bは、推論が6倍速くなり、多くの標準的なベンチマークでGPT-3.5と同等か、上回っている。
可能性を広げる技術を手にできる魅力がMistralの躍進につながっている
昨年のChatGPTがそうであったように、可能性を広げる技術を手にできる魅力がMistralの躍進につながっている。Mixtral 8x7Bが登場した昨年12月に、Googleも新しいAIモデル「Gemini」を発表した。Geminiのマルチモーダル・ネイティブな進化も魅力的だが、扱いやすく、コスト/パフォーマンスに優れたLLMに大きなニーズが存在していることをMistralの躍進が示している。
2023年に多くの企業がChatGPTの可能性と急速な普及に驚かされた。ChatGPTの登場から1年以上が経った今、Fortun 500企業のほとんどが、生成AIのユースケースを探り、クローズドモデルAPIを使用した概念実証アプリケーションの構築を進めている。
しかし、コアテクノロジーの外部APIへの依存は、機密性の高い顧客データやソースコードの漏洩など大きなリスクをはらむ。データのプライバシーとセキュリティを優先する企業にとって、これは長期的に持続可能な戦略として疑問符が付く。
DX(デジタルトランスフォーメーション)を実現する他のテクノロジーと同様に、LLMも顧客情報や規制が要求するプライバシー、セキュリティ、コンプライアンスを完全な管理下に置く必要があり、過去の例に照らすと、オープンソースは有効なソリューションになる。
1年前に人々を驚かせたLLMが、オープンウェイトのAIモデルで利用できるインパクトはエンジニアにとっても大きい。LexicaArtの創設者、シャリフ・シャミーム氏が昨年12月に次のようにツイートした。
「Mixtral MoEモデルは、M1において30トークン/秒で動作する真のGPT-3.5レベルのモデルであり、本当に変曲点のように感じる。推論が100%無料になり、データがデバイスに残るようになって可能になるあらゆる製品を想像してみてほしい」
これに対し、OpenAIのアンドレイ・カルパシー氏が「同感だ。能力/推論力は大きく進歩したように感じる。遅れているのは、全体のUI/UX、ツールの使い方の微調整、RAG(Retrieval-Augmented Generation:検索で強化した文章生成)データベースなどだろう」とコメントした。今シリコンバレーではLLM人材の需要が高騰する一方で、企業のプロジェクトへの参画ではなく起業を選ぶ動きが活発になっている。








