最近では、よっぽど大きなファイルでも、Excelで読み込んで処理できるので、わざわざプログラムを組むことも少なくなっていますが、稀に巨大ファイルを細かく操作したい場面があります。Rustを使うと効率の良いツールが手軽に作成できます。プログラムの見やすさ、実行速度、メモリ使用量の3点を軸にプログラムを作ってみましょう。
-

12万行のテキストファイルをソートしよう

郵便番号CSVでテストしてみよう
比較的サイズの大きなテキストファイルの例には、郵便番号のCSVファイルがあります。郵便局WebサイトからCSVファイルがダウンロードできます。
-

郵便番号CSVのダウンロード

いろいろなCSVファイルが用意されていますが、こちらからZIPファイル「utf_ken_all.zip」をダウンロードしましょう。
ZIPファイルを解凍すると「utf_ken_all.csv」が出てきます。データを確認するため、表計算ソフトでCSVをインポートすると、次のようなデータが表示されます。
-

「utf_ken_all.csv」を表計算ソフトで開いたところ

このCSVファイルを確認してみると、3列目が「郵便番号(7桁)」、7列目が「都道府県名」、8列目が「市区町村名」、9列目が「町域名」、5列目が「市区町村名のカナ」、6列目が「町域名のカナ」となっています。
市区町村名のカナでソートしてみよう
今回は、この5列目と6列目を結合してソートしてみましょう。つまり、次の動作を行うプログラムを作ります。
1. CSVファイル「utf_ken_all.csv」を開く
2. 住所カナ(5列目と6列目を結合したもの)を昇順でソート
3. 郵便番号(3列目)と住所(8列目と9列目)の最初の5件を表示
これを実現するプログラムは次のようになるでしょう。こちらにもプログラムをアップしています。
// file: sort_simple.rs
use std::fs::File;
use std::io::{BufRead, BufReader};
use std::error::Error;
fn main() -> Result<(), Box<dyn Error>> {
// 対象CSVファイルを開いてBufReaderで読む --- (*1)
let file = File::open("utf_ken_all.csv")?;
let reader = BufReader::new(file);
// 住所カナや郵便番号・住所を一時保存する構造体を初期化 --- (*2)
let mut entries = Vec::new();
// 1行ずつ読み込んでCSVフィールドを抽出 --- (*3)
for line in reader.lines() {
let line = line?;
if line.is_empty() {
continue;
}
// フィールドを分割してトリムし、必要な情報を抽出 --- (*4)
let fields: Vec<String> = line
.split(',')
.map(|s| s.trim_matches('"').to_string())
.collect();
// 住所カナ(5と6列)、郵便番号(3列目)、住所(8と9列目)を取得 --- (*5)
let kana_key = format!("{}{}",
fields.get(4).map(String::as_str).unwrap_or(""),
fields.get(5).map(String::as_str).unwrap_or(""));
let postal = fields.get(2).map(String::as_str).unwrap_or("").to_string();
let address = format!("{}{}",
fields.get(7).map(String::as_str).unwrap_or(""),
fields.get(8).map(String::as_str).unwrap_or(""));
// 抽出した情報をタプルとしてベクタに追加 --- (*6)
entries.push((kana_key, postal, address));
}
// 住所カナをキーに昇順ソートし、先頭5件を出力 --- (*7)
entries.sort_by(|a, b| a.0.cmp(&b.0));
for (_, postal, address) in entries.iter().take(5) {
println!("{} {}", postal, address);
}
Ok(())
}
上記のプログラムを「sort_simple.rs」という名前で保存します。そして、プログラムを実行するには、ターミナルで次のコマンドを実行します。
# コンパイル
rustc sort_simple.rs
# 実行
./sort_simple
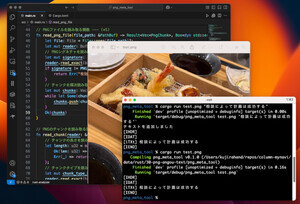
すると、次のように表示されます。都道府県関係なく市区町村でソートすると兵庫県の「相生市(アイオイシ)」の郵便番号が上位に出てきます。
-

コマンドを実行したところ

プログラムを確認しましょう。(*1) では、CSVファイルを開いて、BufReaderを使ってデータを読み出します。「File::open」はファイルを開くメソッドで、「?」を使うことでエラー処理を簡潔に記述します。
(*2)では、住所カナや郵便番号・住所を一時保存する構造体を初期化します。(*3)では、1行ずつ読み込んでCSVフィールドを抽出します。
(*4)では、1行の文字列をカンマ区切りで分割し、CSVの各フィールドを取り出しています。 CSVでは値が "文字列" のようにダブルクォートで囲まれていることが多いため、フィールド前後のダブルクォート「"」を取り除いて、Stringに変換します。
(*5)では、CSVの特定の列から必要な情報を組み立てます。(*6)では、タプルとしてVec型のentriesに追加します。タプルは(住所カナ, 郵便番号, 住所)となっています。
最後に(*7)で、データを住所カナをキーにして昇順ソートして、先頭の5件を表示します。ポイントは、Vec型のentriesを、sort_byメソッドでソートしている部分です。sort_byの引数にはクロージャ(匿名関数)を指定しています。ここでは、Vec型のentriesにはタプルが入っているので、タプルの先頭の要素(a.0とb.0)を比較することで、カナ順に並び替えできます。