


VEカードの概要
SX-Aurora TSUBASAの実物はHot Chipsでは展示されていなかったが、次の写真は、今年6月にフランクフルトで開催されたISC 2018での展示を筆者が撮影したものである。8枚のVEがPCIeスロットに挿入されており、8VEのA300-8の中身であると考えられる。
-

6月のISCで展示された8VEのSX-Aurora TSUBASAシステム。電源ケーブルが接続された8個のPCIeモジュールがベクタエンジンである (ISC 2018にて筆者撮影)

VEカードはサーバの冷却ファンの風で冷却するパッシブ空冷タイプとハイエンドGPUのような外見で、PCIeカードに小型のファンを搭載するアクティブ空冷タイプがある。そして、A500では水冷のコールドプレートが付いたカードが使われる。
なお、水冷の場合の水温は40℃と書かれている。
-

VEカードは、サーバの冷却風を使うパッシブ空冷カード、ハイエンドGPUのように小型のファンをカードに搭載するアクティブ空冷タイプと、サーバ用の水冷タイプがある

次の図は、ヒートシンクを取り外したベクタエンジンを搭載したVEカードの写真である。VEプロセサモジュールには中央に縦長の大きなチップがあり、その左右に各3個の小さいチップがある。中央の大きいチップがVEのプロセサチップであり、両側の6個はHBM2 積層メモリチップである。なお、NVIDIAのV100 GPUや富士通のPost-K(ポスト「京」)などもHBM2を使っているが、4個の搭載であり、このVEは6個のHBM2メモリを搭載する世界初のプロセサである。
カードのサイズは標準のPCIeカードで、フルハイト、フルレングスである。インタフェースはPCIe3.0のx16レーンとなっている。消費電力は300W未満となっている。この消費電力はカードエッジコネクタだけでは供給できないので、右上に補助の電源コネクタが付いている。
図の左下にDGEMM、STREAM、HPCGという3種のベンチマークを実行している時の消費電力を示す棒グラフがあるが、いずれも160W~170W程度で300Wよりもかなり低い値となっている。ただし、棒グラフの電力が、カード全体の電力であるのか、VEモジュールだけの電力かははっきりしない。
-

VEカードは標準のデュアルスロットのPCIeカードである。インタフェースは16レーンのPCIe3.0であり、消費電力は300W未満となっている。この電力はカードエッジコネクタだけでは扱えないので、右上に補助コネクタが付いている

このVEのプロセサチップと6個のHBM2メモリチップは、シリコンの配線基板であるインタポーザに搭載され、相互接続される。VEプロセサチップは15mm×33mm、インタポーザ基盤は32.5mm×38mmで、VEモジュールのパッケージは60mm×60mmとなっている。
なお、HBM2としてはDRAMチップ4枚スタックのものと8枚スタックのものがあり、どちらも使えるようになっている。4HiのHBM2は4GB、8HiのHBM2は8GBであり、1つのVEのメモリ容量は24GBあるいは48GBとなる。
-

VEチップと6個のHBM2メモリチップは、32.5mm×38mmのシリコンインタポーザに搭載されて相互接続される。HBM2は4Hiのものでも8Hiのものでも使用できる

VEプロセサのコアクロックは1.6GHz
VEプロセサは8個のベクタコアを持ち、それらは2次元のメッシュインタコネクトで接続されている。そして、6個のHBM2コントローラとインタフェースを搭載している。それらに加えて、DMAエンジンと16レーンのPCIe3.0インタフェースを備えている。
コアクロックは1.6GHzであり、コアはFP64では307GFlops、FP32では614GFlopsの浮動小数点演算性能を持つ。
6個のHBM2メモリの合計のメモリバンド幅1.2TB/sであり、メモリ容量は4Hiの場合は24GB、8Hiの場合は48GBである。
-

VEプロセサは8個のコアを持ち、それらと合計16MBのLLCは2次元メッシュで接続される。さらに6個のHBM2インタフェースを持ち、4Hiスタックの場合は合計24GB、8Hiスタックの場は48Gとなる。VEチップはさらに、DMAエンジンと16レーンのPCIeインタフェースを持つ

次の図にベクタコアのブロックダイヤを示す。ベクタコアは、高速のSPU(Scaler Processing Unit)を備えている、このSPUは命令フェッチ、デコード、分岐、例外処理などプロセサの基本機能を実現している。また、ベクタコアのステートの管理も行っている。
ベクタコアのVPU(Vector Processing Unit)は256要素のベクタレジスタを64本持ち、FP64演算の場合は307.2GFlops、FP32演算の場合は、614.4GFlopsのピーク演算性能を持つ。
これらのSPUとVPUの下にAddress Generation and TranslationとRequest/Reply crossbarというブロックがある。Address Translationは、飛び飛びのアドレスのデータを順に並べるために1サイクルに16個の要素のアドレス変換を行うことができる。Data Forwarding crossbarはロード方向に409.6GB/s、ストア方向にも409.6GB/sのデータ転送能力を持っている。
-
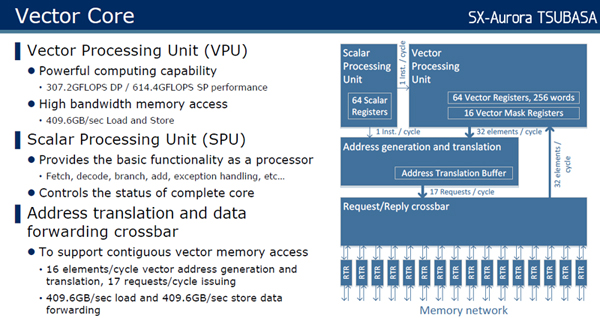
VPUはFP64演算では307.2GFlops、FP32演算では614.4GFlopsの演算性能を持つ。VPUはRequst/Reply crossbarを経由して、409.6GB/sのロードと409.6GB/sのストアができる

(次回は9月7日に掲載します)














