



SX-Auroraの性能を他のプロセサと比較
次の図は、SX-AuroraのVEとIntelのSkylake、Knights Landing、NVIDIAのV100のSTREAM性能とHPL性能を比較したものである。いずれも、Skylakeの性能を1.0として正規化している。STREAMはメモリバンド幅が効くベンチマークで、Skylakeの1.0に対して、VEは4.8、V100は3.4程度となっている。完全に公称メモリバンド幅に比例しているわけではないが、メモリバンド幅が最大のVEがトップになっている。
HPLではVEとSkylakeは同じで、V100は2.3倍の性能となっている。こちらは演算性能が効くベンチマークであり、V100が高性能であるのは理解できる。しかし、高性能をうたうVEのHPL性能がSkylakeと同じというのは解せないところがある。
-
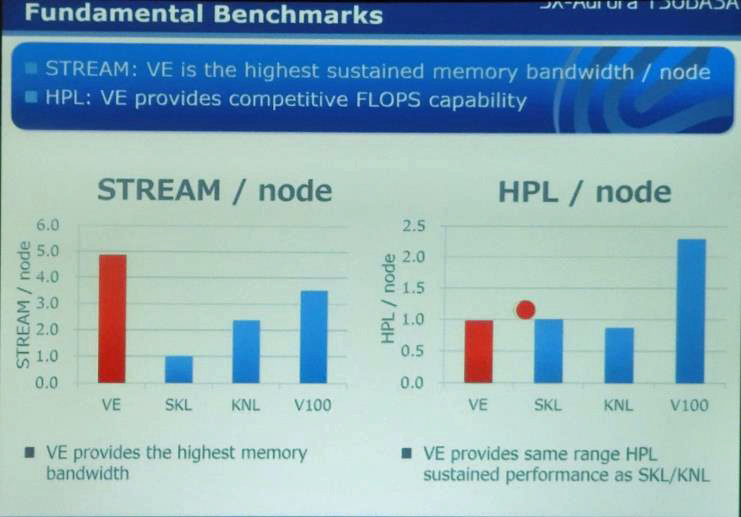
Aurora VEとIntelのSkylake、Knights LandingとNVIDIAのV100のSTREAMベンチマークとHPL性能の比較。STREAMではVEが最高性能。HPLではVEはSkylake、Knights Landingと同程度。V100は2倍以上高性能

次の図は価格を考慮した比較である。STREAM/Priceでは、VEが圧倒的にプライスパフォーマンスが高く、HPL/PriceではV100が若干高いものの、どのプロセサも大差がないという結果になっている。したがって、Aurora VEが良いという比較になっている。
この図は価格を比較しているものではないが、VEの性能が4.8倍程度で、STREAM性能/価格が5.0倍となっており、VEの価格とSkylakeの価格はほぼ同じということになる。一方、V100はSTREAM性能は3.4倍程度であるがSTREAM/Priceは1.9程度であり、V100はVEやSkylakeと比べて1.8倍くらい高いことになる。
ただし、これはSTREAMとHPLの性能/価格での比較であり、ディープラーニングなどを考えると、半精度浮動小数点演算をサポートしていないAurora VEに比べて、Tensorコアを追加したV100 GPUは圧倒的に高い性能を持つと考えられるので、性能/価格は、どのような処理を実行するかに依存する。
-
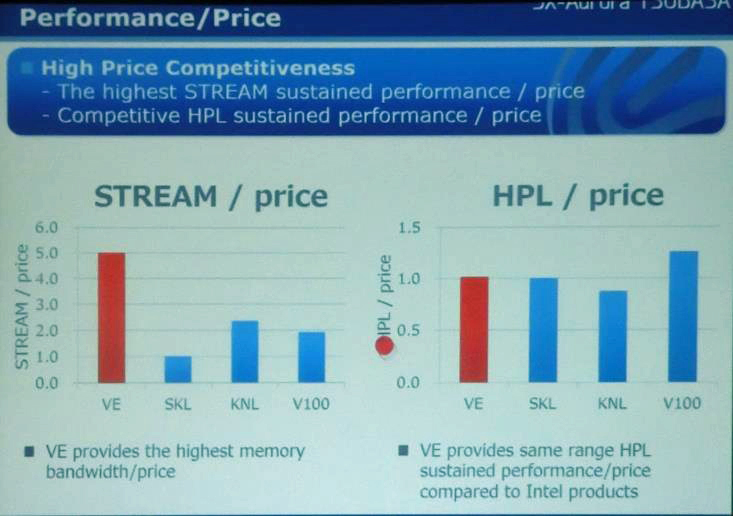
4種のプロセサのSTREAM性能/価格とHPL/価格の比較。VEはSTREAM/価格では圧倒的に性能/価格が高く。HPL/価格は4種のプロセサで大差ない

製品としては、1個のVEのデスクサイドタワー型のA100-1から64VEのA500-64までを提供する予定である。この図には製品ごとに、左端に使えるVEのタイプ、下端に使用できる冷却テクノロジが示されている。
-

5つの製品とそれぞれの製品で使用できるVEのタイプと冷却テクノロジを示す

次の図は、最上位のA500-64の前面ドアを除いた写真と諸元を示すものである。8段の4Uサーバが重ねられているようであり、A300-8サーバ8台で構成されているのではないかと思われる。
この筐体1つで、ピーク演算性能は157TFlops、諸費電力は<30kWである。ベクトルプロセサであるので、HPL性能はピーク性能からあまり下がらないと考えると、157TFlops/30kWで5.2GFlops/W程度ということになる。NVIDIAのSaturn V Voltaや暁光スパコンが15GFlops/w程度のGreen500スコアを出しているのと比較すると、あまり効率が良いとは言えない。また、サイズ的にもPEZYのShoubu System Bなどと比較して大きい。
-

ラインアップの最上位のA500-64。A300-8を8台組み合わせているように見える。ピーク性能は157TFlops、消費電力は<30KW

次の図は、8VEのA300-8サーバを多数台使用しInfiniBandで接続することにより、大規模システムを作る例として示された図であるが、A500-64もこの図のような構成になっていると推測される。
-
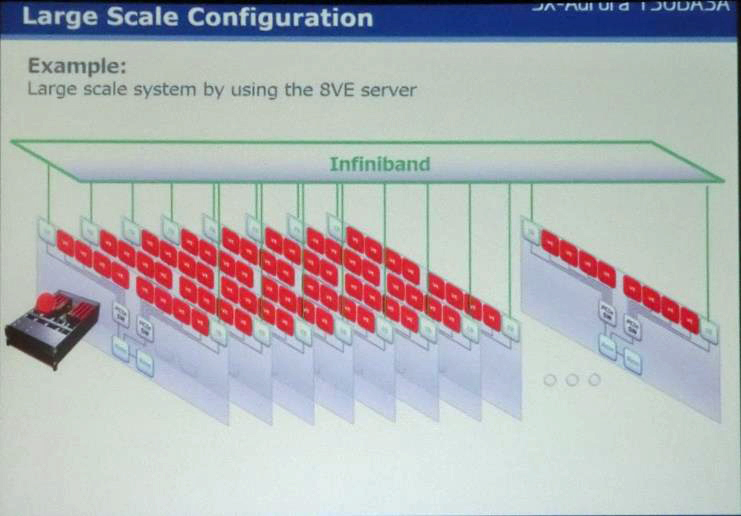
多数台のA300-8サーバをInfiniBandで接続して、大規模なシステムを構成する例。A500-64もこのように構成されていると推測される

1ノードあたりの価格をXeonサーバ並みに引き下げ、これまでのSXスパコンと同様の使い勝手を実現しており、SXスパコンのユーザにとっては喜ばれるシステムとなっている。しかし、InfiniBandを使わないA300だけのシステムでは、VEをPCIeだけでつなぐことになり、NVLinkを持つVoltaを使うシステムと比較するとバンド幅に懸念が残る。
この図のように4VEごとにInfiniBand接続がある構成では、約10TFlopsのノードがInfiniBandで接続されているシステムとなっており、ノード間通信の性能はInfiniBandで決まることになると思われる。














