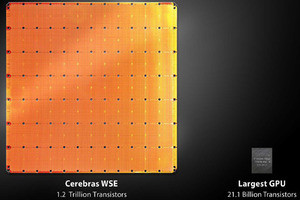
Ascend 310は電力効率の高いエッジ用のSoCである。FP16で8TFlops、INT8では16Topsのピーク性能を持つ。それに16チャネルのH.264/265のデコード、1チャネルのH.264/265のエンコードができる。製造プロセスは12nmで、消費電力は8Wである。
Ascend 910はFP16で256TFlops、INT8では512Topsのピーク性能を持つ。そして、128チャネルのH.264/265のデコードができる。製造プロセスはEUVを使う7nm+プロセスを使い、消費電力は350Wである。
-

Ascend 310はINT8では15Topsの性能で、消費電力は8W。Ascend910は最先端の7nm+プロセスを使いFP16で256TFlopsの性能を持つ。しかし、消費電力は350Wである

次の図は、業界を代表するNVIDIAのV100 GPUとGoogleのTPU v3とAscent 910を比較したものである。FP16でのピーク演算性能で見ると、Tesla V100が120TFlops、TPU v3が105TFlopsであるのに対して、Ascend 910は256TFlopsと2倍以上の性能である。
-

業界を代表するNVIDIAのTesla V100、GoogleのTPU v3とAscend 910のFP16のピーク演算性能の比較。256GFlopsのAscend 910はV100 GPUやTPU v3より2倍以上高いFP16演算性能を持っている

Ascend 910 AIサーバは、上段のシャシーに8個のAscend 910を搭載し、下段に2ソケットのXeonサーバを置いた構造になっている。メモリは24DIMMで、最大1.5TBのメモリを搭載できる。
-

Ascend 910 AIサーバは、上段のシャシーに8個のAscend 910 を載せ、下段のシャシーにXeon 2ソケットのサーバを載せた構造になっている。搭載できるメモリは最大1.5TB

Ascend 910クラスタは、256TFlopsのAscend 910を使い、クラスタ全体では512PFlops(FP16の場合)の性能を持つクラスタである。8個のAscend 910を搭載するサーバ内部はNVIDIAのDGX-1と同じ接続で、その上位レベルはFat Tree接続になっている。
しかし、これはAscend 910サーバを使ってこのようなシステムを作ることができるという話で、実際にこのようなクラスタシステムが作られたかどうかは分からない。
-

Ascend 910を2048個使う512PFlops(FP16の場合)のクラスタ。8ノードはTwisted Hypercube、その上位はFat Tree接続になっている

次の図はAscend 910のMCMの写真で、Vitruvianという456mm2のチップに4個のHBMメモリが付き、外部接続用のNimbusチップが付いている。そして全体を長方形に整えるための2個のダミーダイがついており、MCMには全部で8個のダイが搭載されている。
-

Ascend 910のMCMの写真とチップの配置図。配置図の方は90度回転している。2個のダミーダイを含めて8個のチップが搭載されている

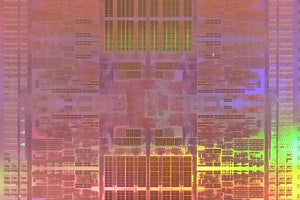
次の図はAscend910チップのダイ写真と1個のコアの拡大写真である。Ascend 910の32個のコアはRead、Writeともに128GB/sのバンド幅のメッシュネットワークで接続されている。チップ間の接続は他のAscend910とのNUMA接続用の3×240GbpsのHCCSというポートとネットワーク接続用の2×100GbpsのRoCEポートを持っている。
-

Ascend 910チップのダイ写真と1個のコアの拡大写真。Ascend 910の32個のコアはメッシュネットワークで接続されており、ネットワークはRead、Writeともに128GB/sのバンド幅を持つ。それに加え他のDaVinciコアと接続する3×240GbpsのHCCSポートと2本の100GbpsのRoCEでネットワークに接続できる

チップ上のメッシュネットワークは1024bit幅で2GHzで動作している。32個のコアの一部は上下、左右に隣接する2つのコアを纏めて6行4列のメッシュネットワークで接続されている。オンチップのL2キャッシュのアクセスバンド幅は4TB/s、オフチップの4個のHBM2のアクセスバンド幅は1.2TBとなっている。
-

Ascend 910のオンチップネットワーク。一部の隣接するコアを纏めて6行4列のメッシュで32コアを接続している。L2キャッシュへのバンド幅は4TB/s、HBMへのアクセスは1.2TB/s

今後の改良であるが、現在は持っていないキャッシュSRAMを3Dパッケージでロジックチップの下に抱き込んで取り付け、MCMを大きくして6個のHBMを接続することを目指す。これによりHBMの部分のメモリバンド幅の不足が緩和される。
-

性能向上のアイデアとしては、ロジックチップの下にSRAMのキャッシュを搭載し、HBMの数を6個に増加する

さらに将来のチャレンジとしては、汎用の自動走行MLの開発、自己対戦学習の効率の改善。データ/モデル、パイプラインの並列性を使用するための汎用的な方法、データの精度を統一する方法、アーキテクチャの最適点(スイートスポット)を見つける方法を見つけることなどがある。
-

さらに将来のチャレンジとしては汎用の自動車用のML、自己学習の効率の改善などがあげられる

NVIDIAのV100 GPUは2017年6月の発表であり、それと比べればAscend 910は約2年後の発表であるので性能が高くて当然と言える。それでもV100の120TFlopsの2倍の256TFlopsを実現したのは大したものであり、中国メーカーの動きからは目が離せない。
(次回は9月17日の掲載となります)