ユニファイドメモリの改善
NVIDIAのユニファイドメモリは、CPUのメモリとGPUのメモリの間でページのマイグレーションを自動的に行い、あたかも、CPUとGPUのどちらからもアクセスできる共通メモリ領域があるように使えるという技術である。
この機能はPascalでもサポートされているが、VoltaではGPU間の接続にNVLink2を使うことで、CoherentなアクセスやAtomicなアクセスができるようになった。また、Voltaではアクセスカウンタを備えたことにより、より適切なタイミングでマイグレーションが行えるようになった。
-

ユニファイドメモリは、あるページをアクセスするとデマンドページングでCPUとGPUの間でページを移動することで、単一のメモリのように使えるようにするとい技術である。VoltaではGPU間の接続にNVLinkを使うことにより、コヒーレントなアクセスなどができるようになった

現在のユニファイドメモリは、CPUとGPUの両方からアクセスできるメモリの割り付けには、cudaMallocという関数を呼び出す必要がある。これをSystem Allocatorという機能を使ってCPUのメモリと同様に、mallocとfreeで獲得、解放を扱えるようにする計画であるという。この機能を実現するためにはOSのサポートが必要となるが、この機能はLinux Kernel 4.14でマージされる予定になっているという。
-

CPUとGPUの両方からアクセスできるメモリを作るには、現在はcudaMalloc関数を使う必要がある。これを普通のCプログラムと同じmallocでアロケートし、freeで解放できるという改善を行う。この変更にはOSの変更が必要であり、その機能はLinux Kernel 4.14でマージされる予定である

スループットを大きく改善するマルチ・プロセスサービス
時分割スケジューリングは、、実行するプロセスを順次切り替えていくが、一時には1つのプロセスがGPU全体を占有するという実行形態である。これに対してマルチ・プロセスサービスは、1つのGPUで複数のプロセスを並列に動かすという実行形態で、合計のスループットはこちらの方が高い。
-

時分割スケジューリングでは、多数のプロセスを切り替えながら実行を行うが、一時には1つのプロセスしか実行しない。これに対してマルチ・プロセスサービスでは複数のプロセスを並列に実行してスループットを上げられる

時分割スケジューリングの場合のGPUの使用状況は次の図のようになり、各プロセスのGPU使用率が低い場合は、時分割スケジューリングを行っても使用率は改善しない。
-

時分割スケジューリングでは、タイムスライス1ではプロセスA、タイムスライス2ではプロセスB、タイムスライス3ではプロセスCというように、タイムスライスごとに1つのプロセスだけを実行する。複数のプロセスを並行して実行できるが、GPUの使用率は改善しない

マルチ・プロセスサービス(MPS)の場合は、1つのGPUで複数のプロセスを並列に実行し、各プロセスのGPU使用率は低くても、同時に複数のプロセスを実行するので、トータルのGPU使用率を高めることができる。
ただし、Pascalではメモリ保護機能に制限があり、デフォルトでは、MPSをオフにしていた。
-

複数のプロセスを同時に実行するMPSは、GPUの利用率を高められるが、Pascalではメモリ保護に制限があり、デフォルトではMPSは使っていなかった

これに対して、Voltaではハードウェアによるメモリ保護で安全が確保できるようになり、加えて、カーネル起動遅延の短縮、カーネル起動スループットの改善、スケジューラ分割による性能安定、さらにPascalでは最大16プロセスであったがVoltaでは最大48プロセスを並列に処理できるようになった。
-

Voltaではメモリ保護が改善されて安全性が確保され、MPSが使えるようになった。また、カーネル起動時間が短縮され、カーネル起動スループットが改善し、MPSが使い易くなった

次の図はResnet50での画像認識の例であるが、1つの入力画像ごとに認識だけを行わせた場合は400画像/秒程度の性能であるが、MPSを使って多数のプロセスを並列処理させた場合は7倍の3000画像/秒まで性能が上がっている。右端の棒グラフは複数画像をバッチにまとめて処理した場合で、さらに60%程度性能が向上している。
-

MPSを使うことで、インファレンス性能は7倍に向上した。入力をバッチにして処理すると、さらに60%認識性能を上げることができる

以上、説明してきたように、Voltaはかなり野心的なGPUである。また、SIMT実行の改善やユニファイドメモリの改良、MPSの改善など、地道な改良が数多く詰め込まれている。さすが、GPUコンピューティングの先頭を走るNVIDIAと思わせるGPUである。
Tensorコアは独立のアクセラレータの方が良かった?
筆者の個人的な意見であるが、Tensorユニットの命令は32スレッドのワープを同期させてから実行するものであり、従来のSIMT実行とは異質のものである。また、256個のFP16の値を格納する4つのレジスタとメモリ上の16×16要素の行列要素との対応は公開されておらず、Tensorコアを利用する場合は、メモリからのロード命令で入力データを与え、演算結果はストア命令でメモリ経由で受け渡される。
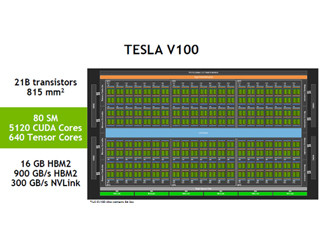
このようにTensorコアの処理は、SMで実行されるSIMTのワープとは異質の処理であり、かつ、入出力が常にメモリ経由となっている。したがって、無理をしてTensor演算をSIMT実行とくっつけるよりも、GoogleのTPUのように独立のアクセラレータとして切り出した方がアーキテクチャ的にすっきりしているのではないかと思う。また、815mm2という製造限界ギリギリの巨大チップを作る必要もなかったのではないかと思うのである。