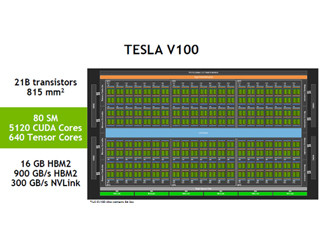
1個のSMには8個のTensorコアがあり、各Tensorコアが64個のFP16データをメモリから読み出すとすると、128B×8Tcore=1024B/cycleのメモリ読み出しが必要となる。クロックはおおよそ1.5GHzであるので、このためには1.5TB/sのL1/Sharedメモリのバンド幅が必要となる。
しかし、Voltaのシェアードメモリは32バンクであるので、ほとんどの場合はバンク競合は発生せず、8個のデータをアクセスできると考えられる。
データ量が多くL1/Sharedメモリには入りきれない場合は、L2キャッシュから読み出して共有メモリに入れる必要があるが、L2キャッシュのバンド幅の方が性能制約になり、125TFlopsは出せない恐れがある。しかし、後に掲げるcublasGemmExの行列積演算の性能のグラフをみると、連続アドレスで行列サイズが大きい場合は、100TFlopsを超える性能が得られており、かなりバランスしたメモリ系となっているようである。
次の図は、cuBLASでTensorコアを使って行列積を計算するものである。cublasSetMathModeでCUBLAS_TENSOR_OP_MATHを指定してTensorコアを利用することを指定する。そして、使用するアルゴリズムはデフォルトと指定し、cublasGemmExを呼び出して行列乗算を行わせる。
CUDA_R_16Fで入力がFP16形式であることを指定し、lda、ldbでストライドを指定する。そして、最後の行のCUDA_R_32Fで加算の計算精度を指定している。
-

cuBLASでTensorコアを使う例。入出力のデータ型や行列積の計算アルゴリズム、ストライドなどを指定できる

cuBLASでTensorコアを使う場合、入出力はFP16で、内部の加算だけはFP32で行うのが標準的(?)である。しかし、cuBLASでは加算をFP16で行ったり、FP32で結果を出力したり、入力をFP32としてそのままTensorコアを使うという使い方もできる。
-

FP16の行列A、Bの積を計算し、FP32の行列Cを加算するのが標準的な使い方であるが、この表に示されたように、いろいろな精度の組み合わせができる

次の図は、行列積をP100 GPUのFP32で計算した場合とV100 GPUでTensorコアを使って計算した場合の性能を、行列のサイズを変えて比較したものである。行列サイズが512の場合は、V100 Tensorコアを使った場合は4倍程度の性能であるが、行列サイズが4096になると9倍の性能向上が得られている。
-

V100 TensorコアとP100 FP32計算の性能比は、行列サイズが512の場合は4倍であるが、行列サイズが4096かそれ以上になると、性能比は9倍に増加する

次の図はV100同士の比較で、FP32を使った場合とTensorコアを使った場合の性能の比較である。オレンジがFP32での計算、黒がFP16での計算の場合で、性能の高い2本のグラフがTensorコアを使った場合の性能である。
Tensorコアを使わない場合は行列サイズが2048以上ではFP32では15TFlops程度、FP16では30TFlops程度である。これに対してTensorコアを使った場合は行列サイズが4096の場合で、TensorコアでFP32加算を使った場合は80TFlops強、FP16加算では100TFlopsを超える性能となっている。
基本的には加算はFP32で行っており、FP16出力の場合はFP32から変換しているという説明であったが、FP16で計算した方が性能が高いというのは、ちょっと驚きのデータである。
-

cuBLASでの行列積の計算性能。下の2本の折れ線はFP32での計算、上の2本の折れ線はTensorコアを使った計算の性能である。そして、黒線はFP16加算、オレンジはFP32加算を使った場合である。FP32加算の場合、V100 GPUのFP32での計算に比べて、Tensorコアを使うと6倍以上の性能が得られている

次の図は初めて見た貴重なデータで、内積をFP32とTensorコアの混合精度演算とFP16で計算した場合の誤差をエラーバーで示したグラフである。そして、それぞれのケースに対して、内積のベクトル長を32から1024まで変えている。
FP32での計算を正しいとして、Tensorコアの混合精度の計算では、誤差は+/-数%に収まっている。一方、FP16での計算は、内積長が1024の場合は10%の以上の誤差が出ている。入力はTensorコアの場合と同じであるが、FP16で加算を行うと誤差が大きく、FP32で加算することが誤差を減らすのに非常に有効であることを示している。
-

内積の計算をFP32で行った場合、TensorコアでFP16積とFP32加算で行った場合、FP16で行った場合の誤差の範囲をエラーバーで示している。入力は同じFP16であるが加算をFP32で行うTensorコアの演算は、すべてをFP16で行う計算より誤差が小さい

次の図は各種のニューラルネットのConvolution層の計算速度を、P100 GPUの積和演算で行った場合とV100 GPUでTensorコアを使った場合の性能を比較したものである。
性能比は、Resnet50の場合は3.7倍、VGG-Aの場合は5.5倍で、大体、4~5倍の性能となっている。前に掲げた行列乗算(GEMM)の場合の8~9倍という性能向上には及ばないが、Convolution層の計算のかなりの部分を行列積の計算が占めていると推測される。
ただし、これはConvolution層だけの性能比較であり、Inferenceの場合は比較的近いと思われるが、Trainingの場合はBack-Propagationなどが入るので、学習の場合には、この比率の性能アップは変わってくると思われる。
-

P100 GPUでの実行とV100 GPUでTensorコアを使った場合の各種ニューラルネットの性能比較。ただし、ここではConvolution層の処理だけを比較している。V100 TensorコアはP100に比べて3.7倍~5.5倍の性能となっている

(次回は2月15日に掲載します)