GTC Japan 2017でVoltaアーキテクチャについて講演するNVIDIAの成瀬氏
2017年12月に開催されたGTC Japan 2017において、NVIDIAのシニアデベロッパーテクノロジーエンジニアである成瀬彰氏が、「VOLTA ARCHITECTURE DEEP DIVE」と題する講演を行った。成瀬氏によると、Voltaの開発に当たっては、多くの新しい機能を盛り込むため、GPUの命令アーキテクチャを全面的に見直し一新したという。
次の図に示すように、Voltaは最も生産性の高いGPUであり、NVLinkとHBM2で高いバンド幅を備えている。そして、複数の処理を並列して実行するMPS(Multi-Process Service)で推論演算のGPU利用率を高め、ワープ内のスレッド同期ができるようになり、Tensorコアによりディープラーニングでは125TFlopsという高い性能を持つ。結果として、ディープラーニングとHPCのどちらにも最適なGPUになっているという。
これらのVoltaの開発で強化された機能について、これから詳しく見て行こう。
-

Voltaでは、生産性の向上、バンド幅の向上、MPS、SIMTモデルの改善、125TFlopsのTensorコアの追加が主要な強化項目である (この連載の図は、GTC Japan 2017におけるNVIDIAの成瀬氏の発表スライドを撮影したものである)

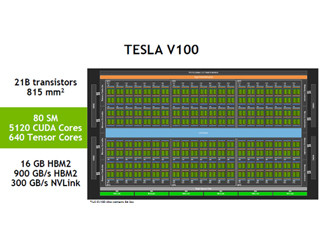
Tesla V100 GPUの概要
Tensorコアの追加で、Tesla V100 GPUのディープラーニングのトレーニング(学習)性能は、P100 GPUの2.4倍、インファレンス(推論)性能は3.7倍となった。
-

Tensorコアの追加で、ディープラーニングのトレーニング性能は2.4倍、インファレンス性能は3.7倍に向上した

また、次の図に見られるように、各種のHPCプログラムの性能は1.4~1.8倍に向上している。なお、次の図の右側は、米国の次期フラグシップスパコンのSummitの筐体の写真である。SummitはPOWER9 CPU 2個に6個のV100 GPUを接続したノードを約3400ノード持ち、200PFlopsを超えるピーク演算性能を持つ。そして、消費電力は10MWである。
-

DGEMM、FFTなどの6種のHPCベンチマークのV100での性能。P100に比べて1.4~1.8倍の性能になっている

次の図はV100 GPUのブロック図である。V100 GPUは、TSMCの12nmプロセスで作られており、総トランジスタ数は211億、チップサイズは815mm2と現在の半導体プロセスで作れる最大級の巨大チップである。それに容量16GBでバンド幅900GB/sというHBM2メモリと300GB/sのNVLinkを備えている。
なお、この図には84個のSM(Streaming Multi-processor)が描かれているが、4個は歩留まり向上のための冗長SMとしており、使用できるSMは80個となっている。この80SMに含まれるCUDAコアは5120コア、ディープラーニングに威力を発揮するTensorコアは640コアである。
-

V100 GPUのブロック図。211億トランジスタ、815mm2という巨大チップである。5120CUDAコアと640 Tensorコアを集積し、900GB/sのHBM2メモリを搭載する

次の図は、P100 GPUとV100 GPUの各種性能や諸元の一覧表で、右端の列は、V100の性能、諸元がP100の何倍となっているかを示している。
FP64/FP32の演算性能やメモリバンド幅などは1.2倍から1.9倍であるが、トレーニング性能は12倍、インファレンス性能は6倍と大きな性能向上となっている。これはTensorコアの追加の効果である。
また、 L1キャッシュの容量が7.7倍となっているが、VoltaではL1キャッシュとシェアードメモリの構造を見直しメモリアレイを一体化しており、その合計の容量までL1キャッシュに割り当て共有メモリをゼロにした場合の値で、L1キャッシュと共有メモリの合計としてはPascalと比較してそれほど大きな増加にはなっていない。
-

P100 GPUとV100 GPUの性能、諸元の比較。Tensorコアでのディープラーニング性能の改善が目立っている

P100 GPUもHBM2メモリを使っているが、メモリバンド幅は720GB/sであった。これに対してV100 GPUのメモリバンド幅は900GB/sと20%上回っている。HBM2の規格では、4個のHBM2の場合、最大メモリバンド幅は1024GB/sとなるが、実際にDRAMメーカーが出荷している製品はこの性能を満たしておらず、Pascal時代に入手できたHBM2メモリでは720GB/sでしか動かせなかったが、Voltaの時代には改善されて900GB/sで動かせるメモリが入手できるようになってきたのではないかと思われる。
-

4個のHBM2メモリのバンド幅は、P100 GPUの720GB/sからV100 GPUでは900GB/sに改善した。左はHBM2メモリとその下のインタポーザの断面写真

P100と比べて、V100では、GPU間を接続するNVLinkのバンド幅は1.9倍に向上している。これは、NVLinkの本数が4本から6本に増加したことと、リンクのバンド幅が40GB/sから50GB/sに向上したことで実現されている。
そして、GPU当たりのリンク本数が6本になったため、GPU間の接続がより密になり、トータルバンド幅は300GB/sに増加している。
-

2個のCPUに8個のV100 GPUを接続する構成例。リンク本数の増加とリンクバンド幅の向上で、GPU間の伝送バンド幅は300GB/sとなった

次の図はV100の1個のSMのブロック図である。1個のSMには、32bitの単精度の浮動小数点演算器が64個、64bitの倍精度の浮動小数点演算器が32個、32bitの整数演算器が64個、Tensorコアが8個入っている。それに加えて、256KBのレジスタファイル、128KBの統合L1・共有メモリを持っている。
そして、1つのSMが同時扱えるスレッドの数は最大2048と、Pascalから変わっていない。
-

Volta GPUのSMの構成。FP32ユニットが64個、FP64ユニットが32個、INT32ユニットが64個、Tensorコアが8個含まれている。そして、256KBのレジスタファイル、128KBのL1・共有メモリを持ち、最大2048スレッドを並列に動かせる

V100 GPUは、それ以前のGPUから命令セットを一新し、スケジュールできる命令数を2倍に拡大している。また、命令発行機構をシンプルな構成とし、L1キャッシュを大容量・高速化し、SIMTモデルを改善している。それに加えてTensorコアの追加でテンソル計算を大幅に高速化している。
なお、スカラも階数0のテンソル、ベクトルは階数1のテンソル、行列は階数2のテンソルで、みんなテンソルであるが、Tensorコアは階数2のテンソル計算(端的に言えば、行列の積の計算)を加速するハードウェアである。
これらの改良の結果として、これまでのGPUよりもプログラミング上の制約が減り、プログラミングが簡単になっているという。
(次回は2月1日に掲載します)