例1:単精度のa*X plus Yの計算
例1の単精度のa*X plus Yの計算は要素ごとにベクトルの和を計算する。CUDAでは10.1ライブラリのcublasSaxpyでは32bit、あるいは64bitのグローバルメモリのload/store命令を使っている。
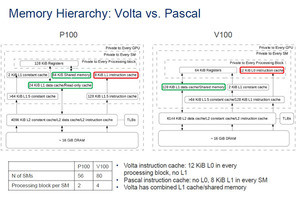
しかし、T4 GPUはスケジューラ当たり4個のLSUを持っている。なお、V100 GPUの場合はスケジューラ当たり8個のLSUと2倍のメモリバンド幅を持っている。そして、T4 GPUはSMあたり1024スレッドをサポートしている。これもVoltaは2048スレッドをサポートしている。
しかし、ブロック数やスレッド数を増やすだけでは、Turing GPUの持つメモリバンド幅を使い切ることは難しい。
-

T4 GPUの場合、スケジューラあたり4個のLSUがあり、1つのSMで1024スレッドを処理できる。32/64bitのload/store命令では、メモリバンド幅を使い切るのは難しい

これを128bitのベクタ化したメモリアクセス命令に替えると1命令でアクセスできるメモリ量を増やすことができる。
次の図の左側のコードではld.global.v4.f32という32bitのロード命令を使っているが、右側のコードではLDG.E.128.SYSで128bitのベクタのロード命令を使っている。このため、命令当たりのメモリバンド幅は4倍になっている。
-

左側のコードは1命令で32bitをロードするが、右側のコードは1命令で128bitをロードするベクタロード命令を使っている

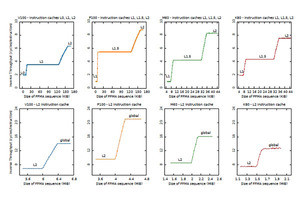
次の図は、Saxpyの実行時間を示すグラフで、横軸はアレイのサイズ(KiB)である。この図からわかるように、青線のベクタロード命令を使うと、20KiBから2000KiBの範囲サイズのアレイではほぼ2倍の性能となっている。なお、2000KiB以上では差が減少しているが、その原因についての考察は書かれていない。多分、TLBミスとそれに伴うテーブルウオークが影響していると思われる。
-

128Bのベクタロードを使うと、20KiBから2000KiBのアレイでは性能が2倍になっている

例2:マトリクスの積和の計算
例2は、C+=ABというマトリクスの積和の計算である。それぞれのスレッドは8×512のA_sliceと512×8のB_sliceを掛けてC_tileの値を計算する。この行列積和の計算は多くのワークロードで最も計算負荷の高い処理となっている。
-

マトリクスの積C+=ABは、A_sliceの列にB_sliceの行を掛けて和をとり、C_tileの1つの要素を計算する

レジスタファイルのアクセスのボトルネックを考えるとき重要なことは、
- 命令は入力オペランドを必要とし、それらはレジスタファイルのポートを通してアクセスされる
- ポートが不足するとその命令の実行はストール(停止)する
- ポートアクセスを緩和するにはレジスタ再利用キャッシュを活用すべき
- コンパイラはレジスタ再利用キャッシュを使おうとするが、必ずしも最適な使い方になっていない
- NVIDIAのライブラリは、最適になっていない場合は人手で最適化している。つまり、我々も同じことをやれば良い。
NVIDIAのドキュメントには書かれていないのであるが、2018年に公開されたCitadelの論文では、NVIDIAの(少なくともVolta)GPUはレジスタ再利用キャッシュという構造を持っている。レジスタ再利用キャッシュは、メインのレジスタファイルに比べて小さなレジスタファイルで、メインのレジスタファイルとは独立にアクセスできるポートを持っている。
メインのレジスタファイルをアクセスすると、そのデータはレジスタ再利用キャッシュに記憶され、その値は、メインのレジスタファイルのポートが使えなくてもレジスタ再利用キャッシュから読み出すことができる。つまり、メインのレジスタファイルのポート不足を補うことができるという仕掛けになっている。
-

NVIDIAのGPUはメインのレジスタファイルと並列にアクセスできる小容量のレジスタ再利用キャッシュがある。これをうまく使うとレジスタファイルのポート数の制約を緩和することができる

次の図の左側のコードで最初の命令は浮動小数点の積和演算で、入力はR12、R80、R16で積和の結果はR16に格納される。2番目の命令は同じ浮動小数点の積和演算で、入力はR80.reuse、R13、R17で積和の結果はR17に入れられる。この2番目の命令ではR80.reuseが指定されており、この場合はレジスタ再利用キャッシュから読まれ、メインのレジスタファイルの読み出しポートを使用しない。
メインのレジスタファイルの読み出しポート数が2つであるとすると、最初の命令は1サイクルでは全部の入力オペランドは読めず、オペランドの読み込みに少なくとも1サイクル余計に必要とする。一方、2番目の命令ではR80.reuseを入力に使っているので、メインのレジスタファイルから読むのはR13とR17の2つで、1サイクルで読むことができる。
右側のコードは、左側のコードをCitadelが最適化したもので、reuseと書かれた入力が多くなっている。結果として、Citadelのコードでは全部の命令が1サイクルで入力オペランドが読めるが、元の左側のコードでは4つの命令でオペランドの読み込みに追加のサイクルを必要とする。
このため、T4 GPUでの実行では、右のコードは左のコードと比べて12%高い性能が得られた。そして、この性能はNVIDIAが最適化したcuBLASの性能と一致したという。
-

左のコードはNVCCが出力したもので、reuseが使われていない部分がある。右のコードはCitadelが最適化したもので、reuseの数が増えている。レジスタファイルの読み出しサイクルが減り12%性能が向上した

GPUのメーカーは、このようなアーキテクチャを公表しないので、普通のGPUプログラムの開発者はこのような最適化を行うことはできない。GPUのアーキテクチャを理解するためには大変な努力を必要とするが、彼らがそれを行ったので、皆がその成果を利用できるようになる。この成果はarxive.orgに公開する準備を進めているという。
-

細部のアーキテクチャをGPUメーカーは公開しないので、普通のGPUプログラマはこのような最適化を行うことはできない。しかし、Citadelが、アーキテクチャを調査し公開したので、皆が利用できるようになった

(次回は4月10日に掲載します)