前回、「敵対的生成ネットワーク(GAN:Generative Adversarial Network)」を紹介しました。今回は紹介する「DCGAN(Deep Convolutional Generative Adversarial Networks)」は、GANに対して畳み込みニューラルネットワーク(CNN)を適用し、かつネットワークを深くした手法です。DCGANの登場によってより写真と見分けがつかない画像を生成することが可能となり、注目を集めました。
DCGAN
DCGANの論文[1] では、畳み込みニューラルネットワーク(CNN)を適用し、かつネットワークを深くした場合であっても安定して学習を進めることができる構成を実証しました。
DCGANの特徴は、以下の通りです。
- 隠れ層に全結合を用いず、畳込みとする。
- プーリングの代わりにストライドの畳み込みを用いる。
プーリングとは、例えば3×3の領域から最大値や平均値を求め1つの値を生成する処理です。これによりプーリング前のデータと比較して、プーリングはサイズの小さいデータが得られます。
一方、ストライドは、3×3の領域をスライドさせていく処理です。2画素飛ばしで処理することで、この処理でもサイズの小さいデータを得ることになります。
- バッチ正規化をすべての層に対して行う。
バッチ正則化では、各層の入力は常に平均が0、分散が1となるようにデータを変換します。これにより学習がより容易に進むようになると言われています。
- Generatorの活性化関数は出力層はtanh、それ以外はReLuを用いる。
- Discriminatorのすべての層の活性関数にLeakyReLuを用いる。
プーリング、ストライド、畳み込み、全結合、活性化関数、tanh、ReLu、LeakyReLuなどの詳細はディープラーニングの書籍やGoogle検索などで調べてみてください。Generator、Discriminatorはこの連載の第60回から読んでみて下さい。
DCGANでは、多層の畳み込み層(Deep Convolutional Network)を用い、かつ上手く学習が進むように工夫することで、良い結果が得られることに成功しました。
-
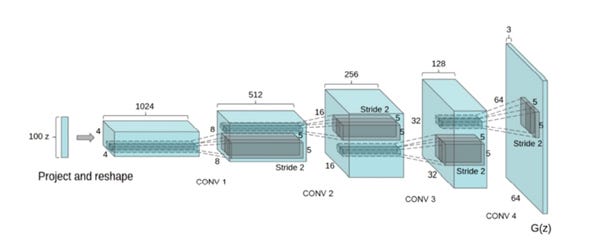
図1 DCGANのネットワーク

図2は手書き文字認識のデータセットであるMNISTを用いて、GANとDCGANを比較した結果です。左から正解値(Groundtruth)、GAN、DCGANとなります。GANでは線が二重っぽく見えるゼロ、6と区別が付きづらい5、7と区別が付き難い9、などが見られます。全体的に不明瞭なパターンが多く生成されています。一方、DCGANでは輪郭もクリアで実際の手書き文字で生じ得るパターンをより正確に生成できています。
-

図2 DCGANによる画像の生成結果

図3はDCGANにより顔画像を生成した結果です。少し歪んだ顔も中には含まれていますが、なかなかボケることなく明瞭な顔画像が生成できています。
-

図3 DCGANによる画像の生成結果

参考文献
[1] A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. In ICLR, 2016.
著者プロフィール
樋口未来(ひぐち・みらい)日立製作所 日立研究所に入社後、自動車向けステレオカメラ、監視カメラの研究開発に従事。2011年から1年間、米国カーネギーメロン大学にて客員研究員としてカメラキャリブレーション技術の研究に携わる。
日立製作所を退職後、2016年6月にグローバルウォーカーズ株式会社を設立し、CTOとして画像/映像コンテンツ×テクノロジーをテーマにコンピュータビジョン、機械学習の研究開発に従事している。また、東京大学大学院博士課程に在学し、一人称視点映像(First-person vision, Egocentric vision)の解析に関する研究を行っている。具体的には、頭部に装着したカメラで撮影した一人称視点映像を用いて、人と人のインタラクション時の非言語コミュニケーション(うなずき等)を観測し、機械学習の枠組みでカメラ装着者がどのような人物かを推定する技術の研究に取り組んでいる。
専門:コンピュータビジョン、機械学習