前回と前々回の連載で紹介した関数UNIQUEは、他の関数と組み合わせて使用するケースが多いといえる。ということで今回は、合計値のリストを作成する方法(SUMIF)、重複データを除外したリストを並べ替える方法(SORT)、指定した項目についてのみ重複データを除外したリストを作成する方法(FILTER)について紹介していこう。
組み合わせることで便利になる関数
関数UNIQUEを使うと、重複データを除外したリスト(配列)を手軽に作成できる。ただし、関数UNIQUEを単体で使用するケースは滅多にない。実際にデータを処理するときは、関数UNIQUEにより出力されたリストをもとに、さらに別の処理を施すケースが多いといえる。
そこで今回は、UNIQUEを他の関数と組み合わせて使用した例をいくつか紹介してみよう。ここではSUMIF、SORT、FILTERといった関数と組わせる方法を紹介していくが、これら以外にも便利な使い方は沢山あると思われる。「UNIQUEにより出力されるデータは配列になる」ということを理解していれば色々な用途に応用できるはずだ。
-

UNIQUEをSUMIFやSORT、FILTERと組み合わせて活用



関数SUMIFとの組み合わせ
まずは、関数SUMIFと組み合わせた例から紹介していこう。以下の図は、あるネットショップにおける1ヶ月間の販売状況を記録したものだ(第65回の連載で紹介した表と同じデータ)。
-
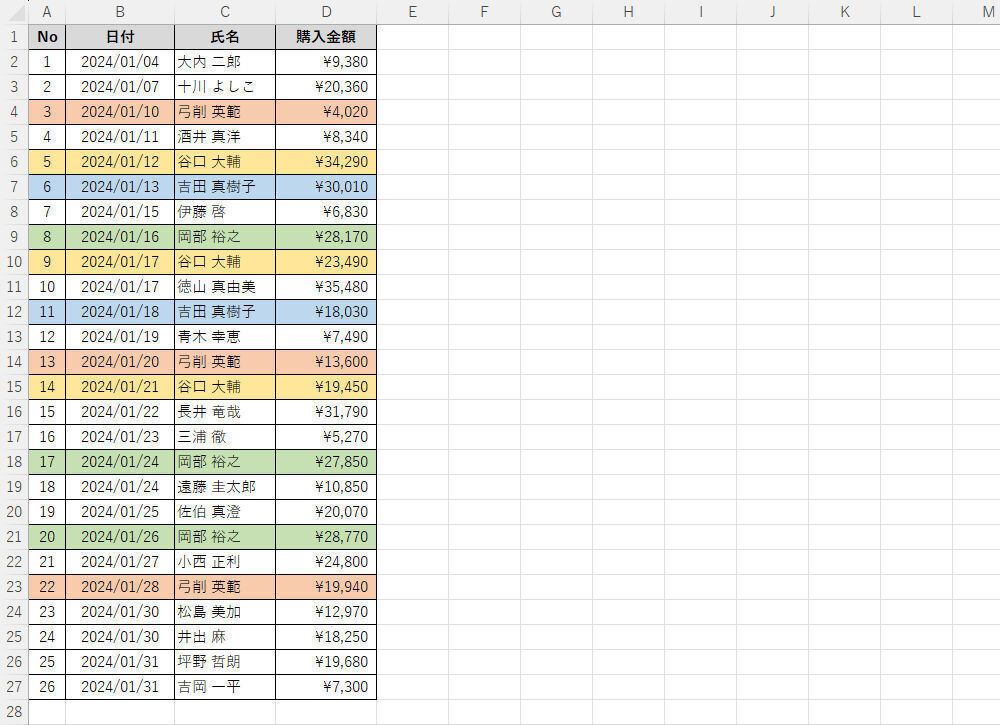
販売状況を記録した表

上図で色を付けた部分を見ると分かるように、この1ヶ月間に「何回も購入してくれたユーザー」がいることを確認できる。つまり、「氏名」が重複しているデータが何件か含まれている訳だ。このような場合にUNIQUEとSUMIFを組わせると、「各ユーザーの購入金額の合計」を手軽に求めることができる。
順番に解説していこう。最初に、関数UNIQUEを使って重複データを除外した「氏名」のリストを作成する。
-
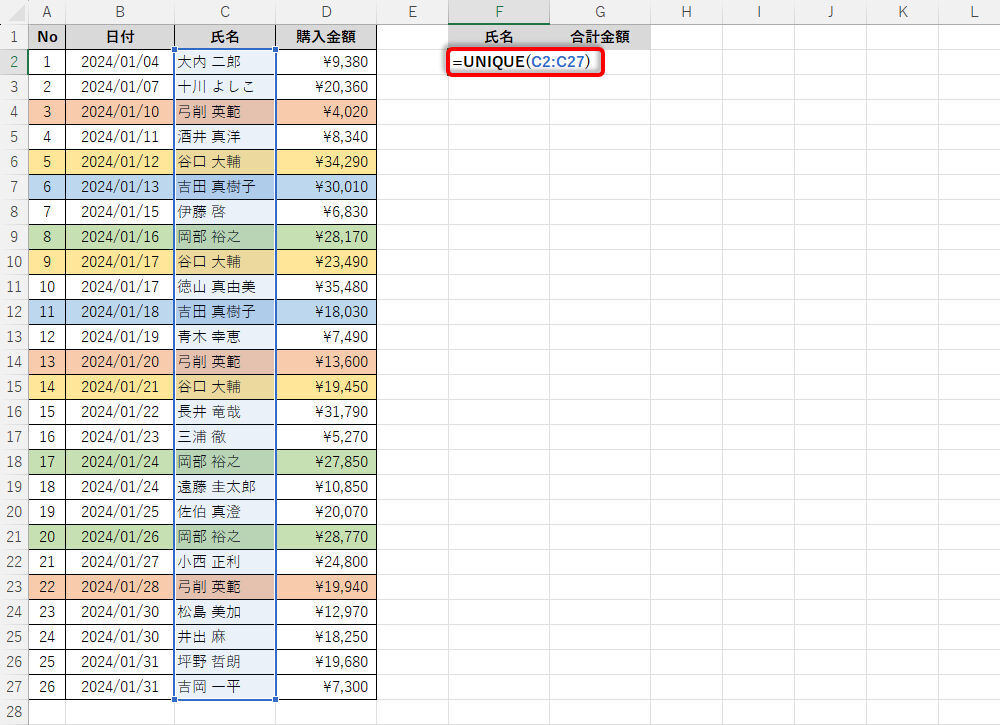
関数UNIQUEの入力

今回の例では、以下の図のようなリストが取得された。これが「この1ヵ月間に商品を購入してくれたユーザー」の一覧となる。
-
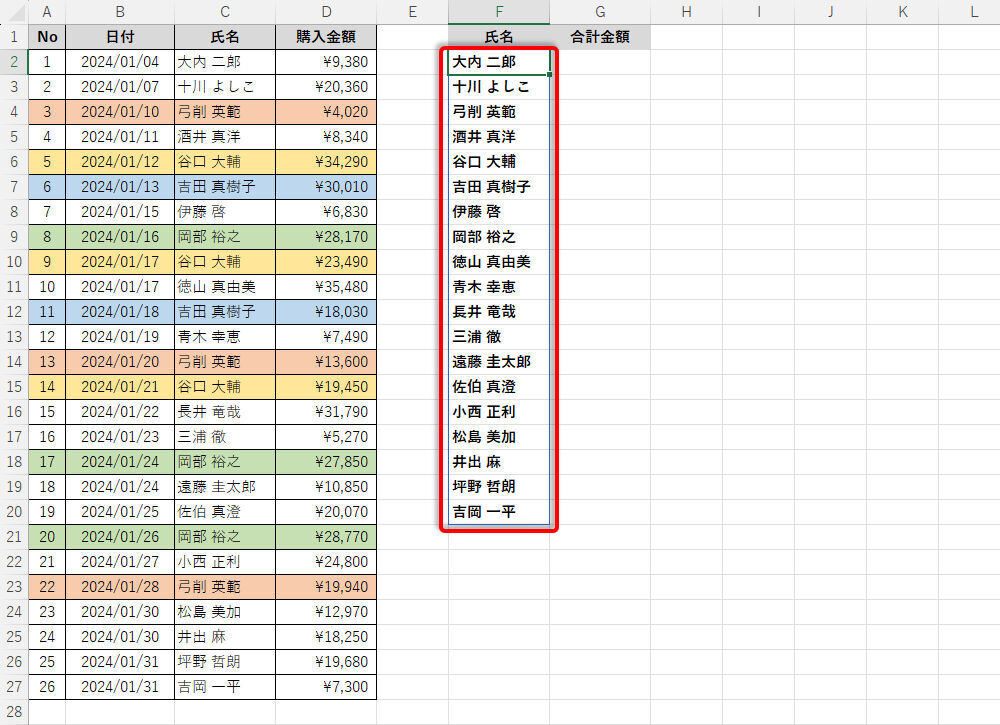
関数UNIQUEにより取得されたデータ

この一覧をもとに「各ユーザーの購入金額の合計」を求めていこう。具体的には、それぞれの「氏名」を条件に「購入金額の合計」を求める関数SUMIFを入力すればよい。なお、関数SUMIFをオートフィルでコピーできるように、「検索するセル範囲」と「合計するセル範囲」は絶対参照で指定している。
-
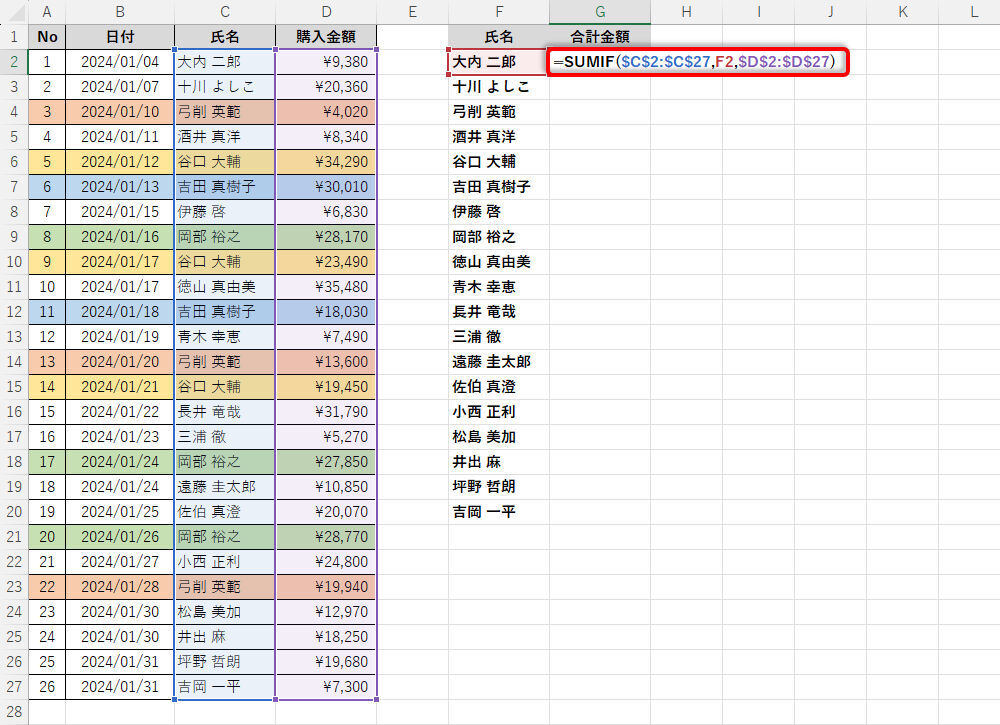
関数SUMIFの入力

上図の場合、氏名がF2セル(大内 二郎)のデータに限定して「購入金額の合計」が算出される。あとは、この関数SUMIFをオートフィルでコピーするだけ。相対参照と絶対参照を正しく使い分けていれば、「検索条件」(F2セル)だけが変化していくように関数SUMIFをコピーできるはずだ。
-
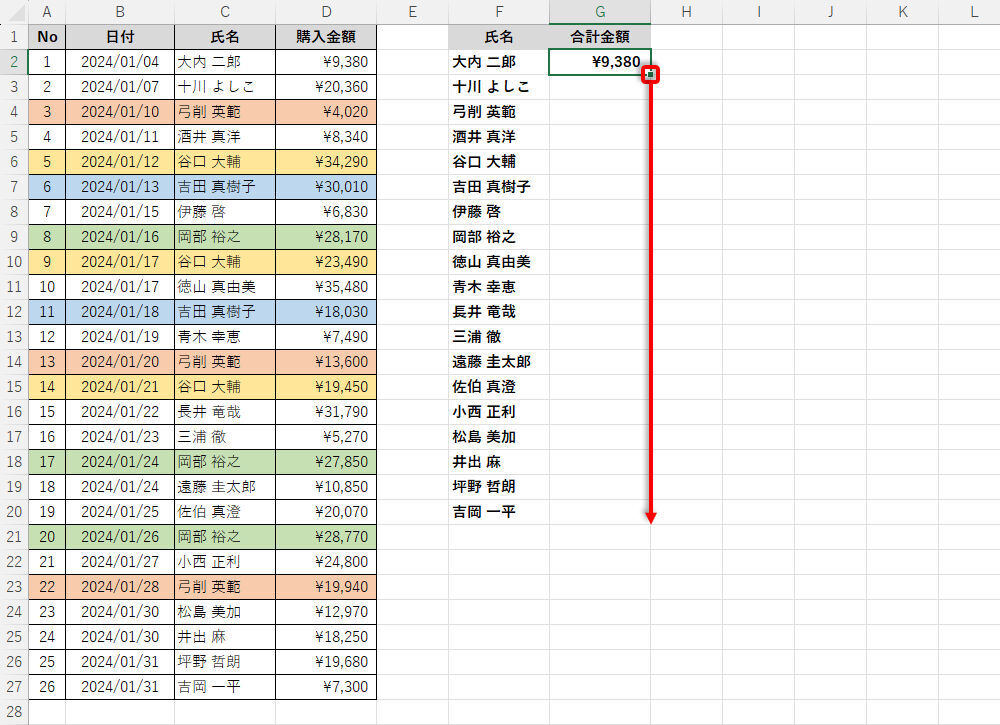
関数SUMIFをオートフィルでコピー

これで、各ユーザーの「購入金額の合計」を求められる。購入データが複数ある「弓削 英範」や「谷口 大輔」、「吉田 真樹子」、「岡部 裕之」といったユーザーも「合計金額」が正しく算出されていることを確認できるだろう。
-

各ユーザーの購入金額の合計

そのほか、以下の図のように関数SUMIFを入力して計算結果を一括出力することも可能となっている。
-
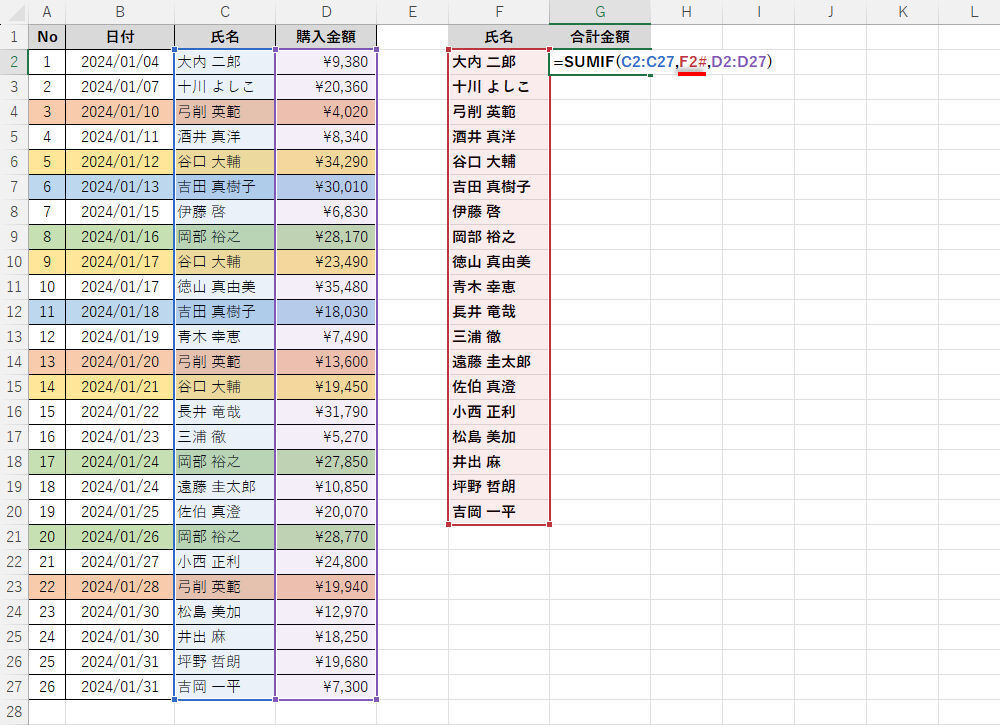
スピル範囲演算子を利用した関数SUMIF

関数SUMIFの第2引数にある「#」はスピル範囲演算子と呼ばれるもので、「スピル出力されたデータ範囲」を自動指定するものとなる。「F2#」と記述した場合、「F2セルにスピル出力されたデータ範囲」、すなわち「F2:F20」が指定されたとみなされる。
この場合は関数SUMIFをコピーする必要がなくなるため、「検索するセル範囲」と「合計するセル範囲」を相対参照で記述しても構わない。
結果は以下の図のとおり。関数SUMIFをオートフィルでコピーしなくても、先ほどと同じ結果を得られることを確認できるだろう。
-
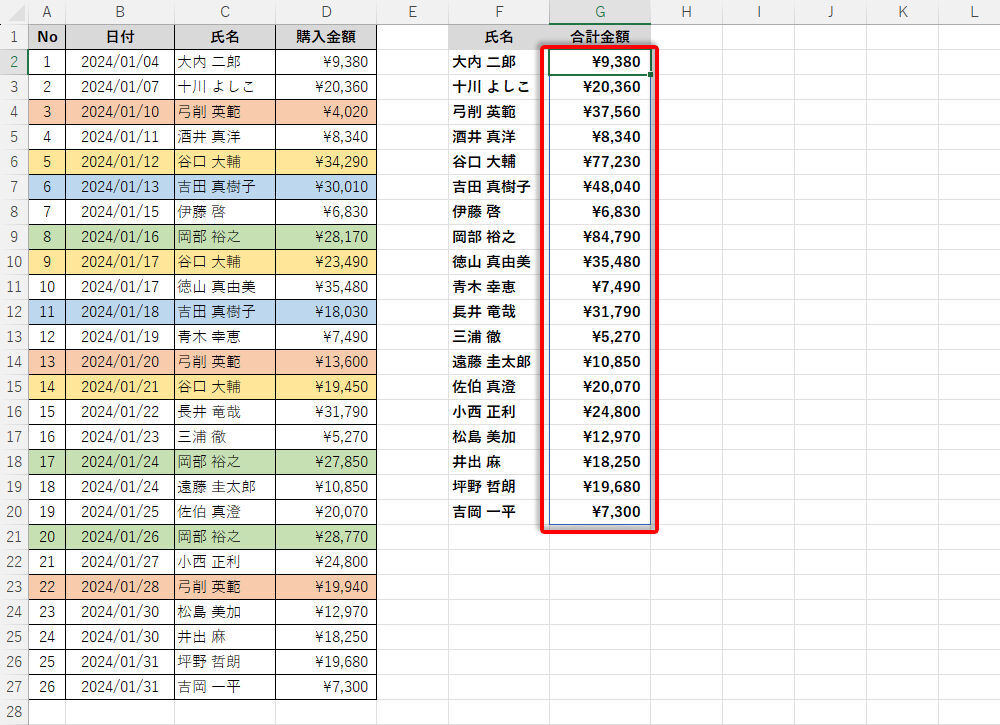
各ユーザーの購入金額の合計

関数SORTとの組み合わせ
続いては、関数SORTと組み合わせた例を紹介していこう。前回の連載で「重複を除外した連絡先の一覧」を作成する方法を紹介したが、この表は「社名」がバラバラに並んでいるため、お世辞にも「見やすい」とは言えない表になっている。
-
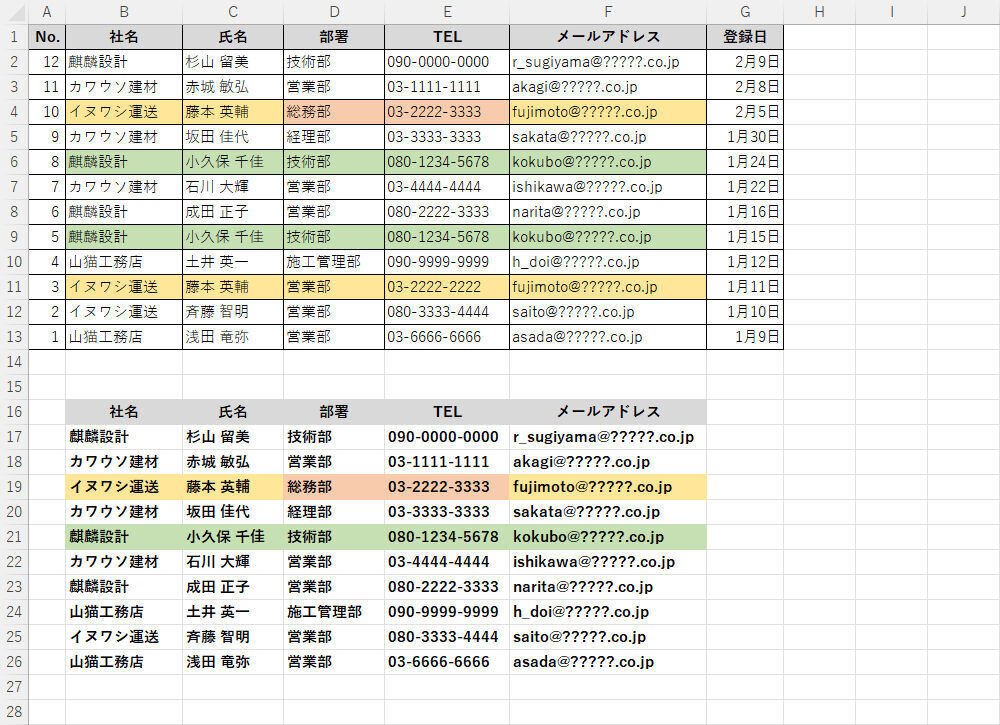
重複を除外した連絡先の一覧

これを見やすくするために「社名でデータを並べ替えればよい」と思う方もいるだろう。しかし、この方法は上手くいかない。というのも、スピル出力されたデータは「並べ替え不可」になっているからだ。試しに「並べ替え」の操作を行ってみると、以下の図のように警告画面が表示され、操作が却下されてしまう。
-

並べ替え不可を示す警告画面

このような場合は、あらかじめ関数SORTでデータを並べ替えておくとよい。たとえば、以下の図のように関数SORTで「UNIQUEの記述」を囲むと……、
-
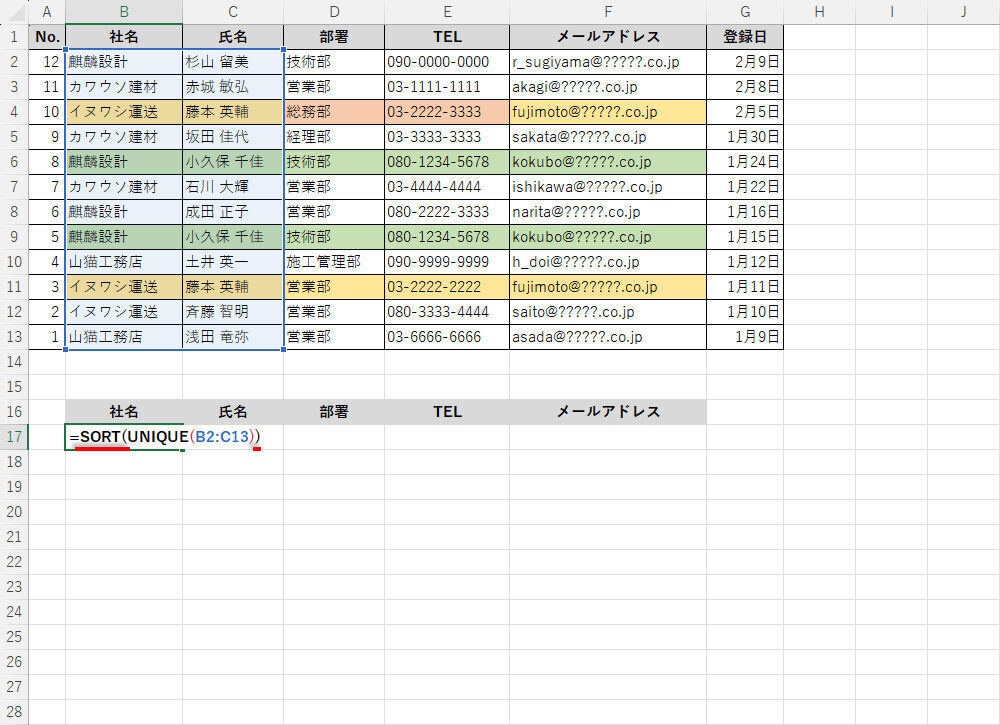
SORTとUNIQUEを組み合わせて入力

関数UNIQUEにより「重複データを除外した配列」が作成され、それを「昇順に並べ替えた状態」でデータが出力されるようになる。
-

関数により取得されたデータ

以降の操作手順は、前回の連載で説明した手順と同じだ。「部署」、「TEL」、「メールアドレス」のデータを関数XLOOKUPで補完してあげればよい。
-
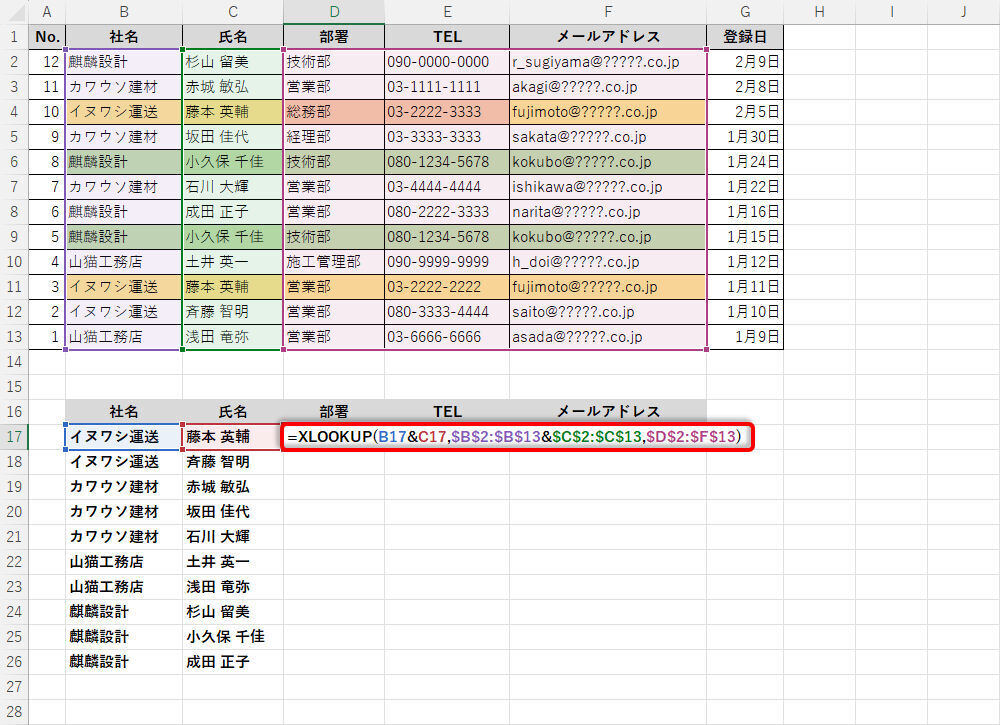
関数XLOOKUPの入力

続いて、関数XLOOKUPをオートフィルでコピーすると、「社名」で並べ替えた“重複なし"の連絡先を作成できる。
-
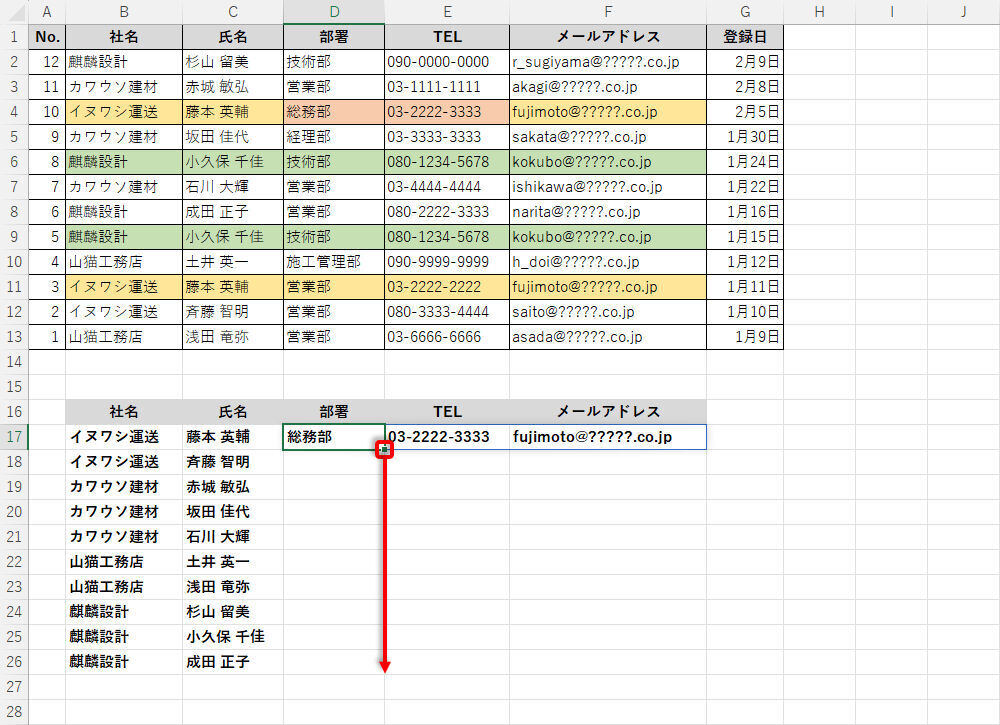
関数XLOOKUPをオートフィルでコピー

データの重複が解消されていることを一目で確認できるように、セルに色を付けた結果を示しておこう。
-
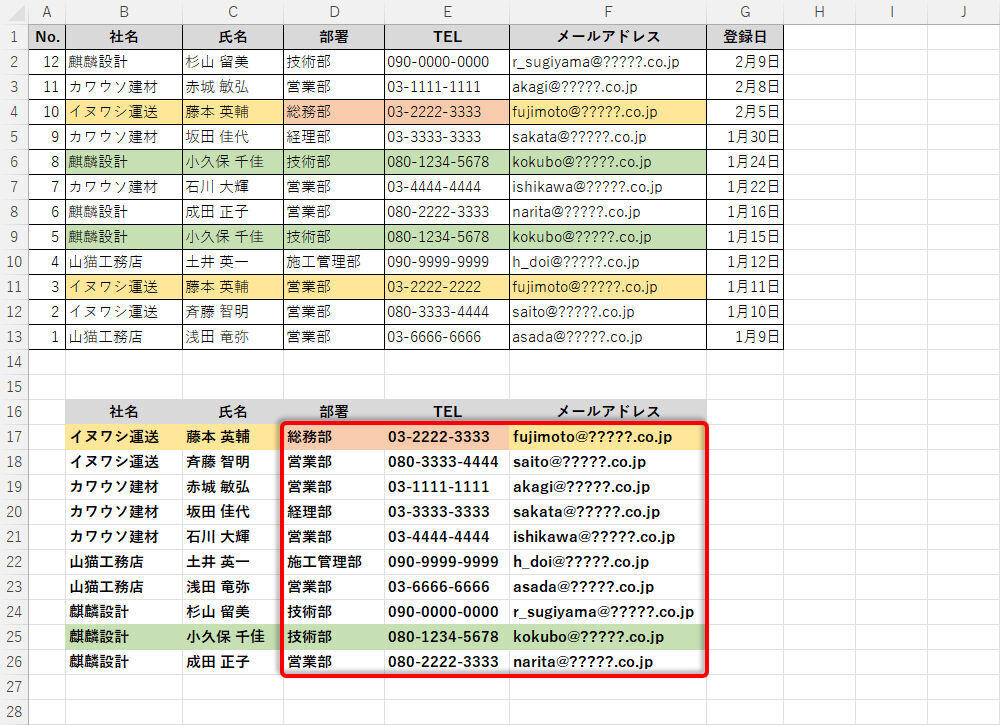
「社名」で並べ替えた“重複なし"の連絡先

「これで見やすい連絡先に改善できた」と言いたいところだが、よく見ると正しい50音順になっていないことに気付くと思う。「社名」の50音順に並べ替えたのなら「麒麟設計」(キリンセッケイ)は「山猫工務店」(ヤマネココウムテン)よりも前に位置しているはずだ。しかし、実際にはそうなっていない……。
このような結果になってしまうのは“ふりがな"のデータが引き継がれていないことが原因だ。関数SORTは“ふりがな"ではなく、文字コードでデータを並べ替える仕様になっている。このため、漢字を含む日本語は正しい50音順にならない。
この問題の対処方法については、関数SORTの使い方を含めて、次回の連載で詳しく紹介していこう。
関数FILTERとの組み合わせ
最後に紹介するのは、UNIQUEとFILTERを組み合わせた例だ。こちらは特定のデータだけを“重複なし"の状態で取得したい場合に活用できる。
たとえば、社名が「麒麟設計」のデータに限定して、“重複なし"の状態で連絡先を取得したいときは、以下の図のように関数を記述すればよい。
-
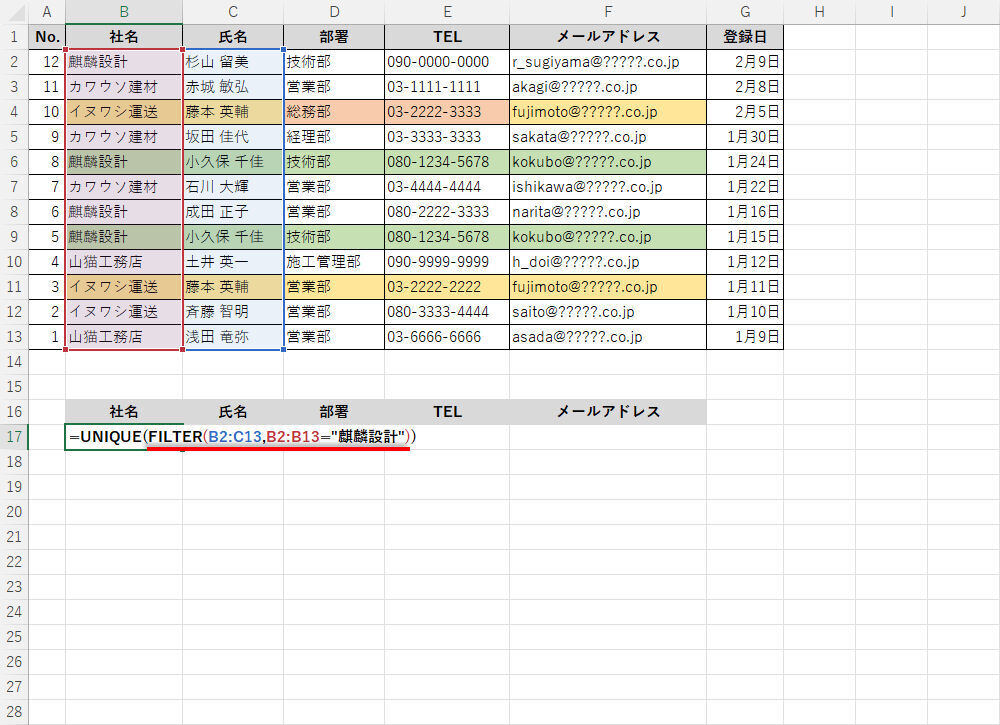
UNIQUEとFILTERを組み合わせて入力

内側の記述から順番に見ていこう。まず、関数FILTERにより社名が「麒麟設計」のデータだけが一括取得される。今回の例では、取得する範囲に「B2:C13」を指定しているため、「社名」と「氏名」のデータが“配列"として取得されることになる。その後、関数UNIQUEにより“配列"から重複データが除外する、という処理が行われる。
結果として、以下の図に示したようなデータが取得されることになる。
-
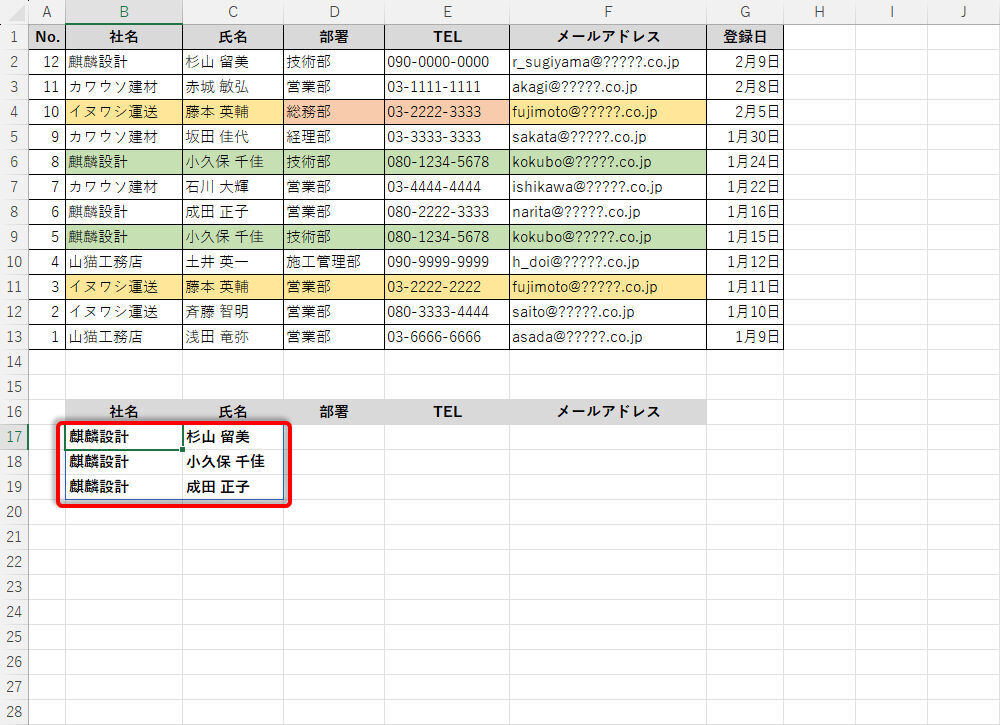
関数により取得されたデータ

以降の手順は先ほどの例と同じ。「部署」、「TEL」、「メールアドレス」のデータを関数XLOOKUPで補完してあげればよい。なお、今回は社名がすべて「麒麟設計」になるため、「社名&氏名」で検索しても意味がない。検索値の指定は「氏名」だけで十分だ。よって、以下の図のように関数XLOOKUPを入力しても構わない。
-
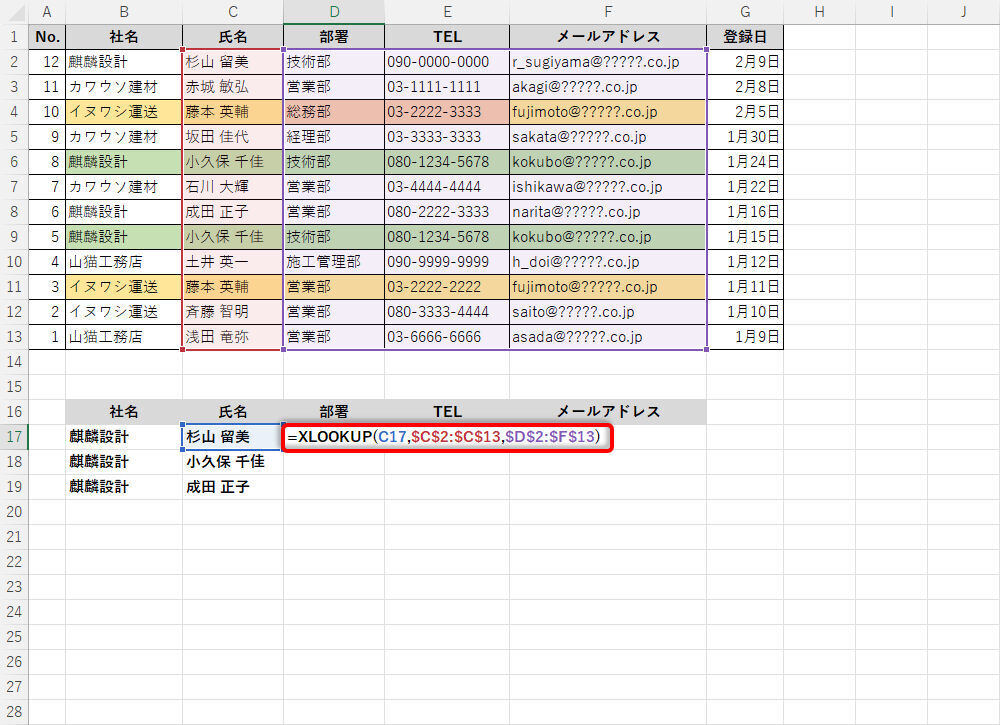
関数XLOOKUPの入力

この関数XLOOKUPをオートフィルでコピーすると、「麒麟設計」に限定した“重複なし"の連絡先を取得できる。
-
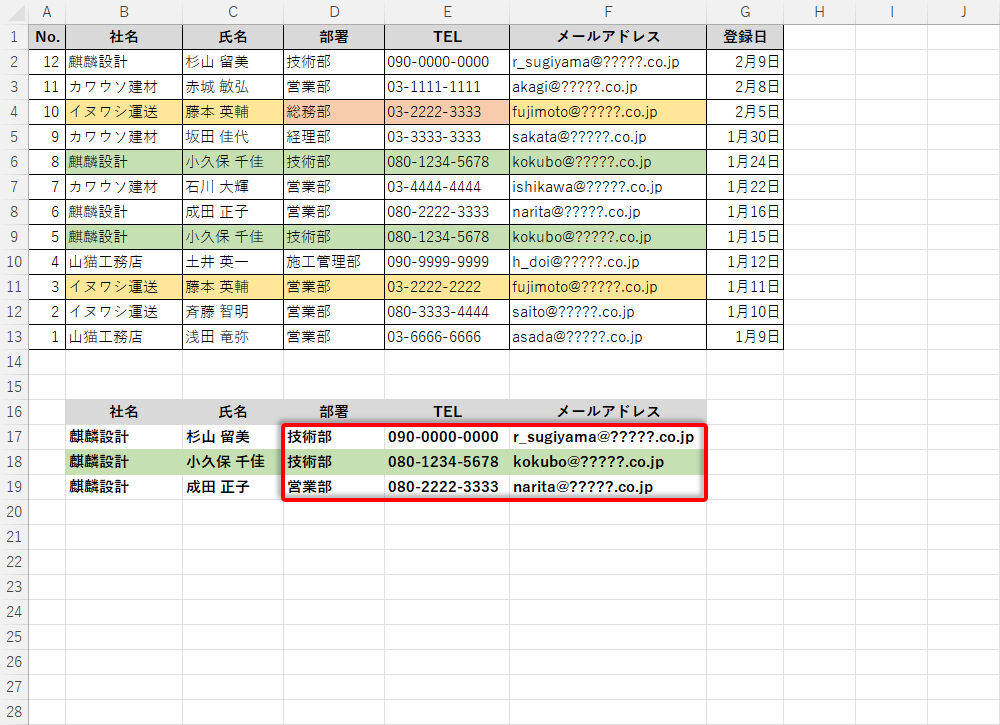
「麒麟設計」に限定した“重複なし"の連絡先

上記の例は全部で12件しかデータがないため、さほどメリットを感じないかもしれないが、「実際には何百件、何千件という規模のデータがある」と考えると、このテクニックの重要性を実感できるだろう。乱雑に管理されている表から“必要なデータ"だけをピックアップする手法の一つとして参考にして頂ければ幸いだ。
ということで、次回は説明が中途半端になっていた関数SORTについて詳しく紹介していこう。スピル出力されたデータを並べ替えたいときに活用できる関数なので、SORTの使い方もあわせて覚えておくとよい。