データが一律に分布している乱数ではなく、平均値付近のデータ頻度が高く、そこから離れるほどデータ頻度が低くなっていく乱数を生成したい場合もあるだろう。このような場合は関数NORM.INVを使うと、中心部が山なりの「正規分布の乱数」を作成できる。ただし、そのためには「標準偏差」について理解を深めておく必要がある。
生成される乱数のヒストグラム
今回は「テストの点数」をランダムに生成する場合について考えていこう。「テストの点数」は、平均値付近のデータが多く、そこから離れる(高得点または低得点)になるほどデータの頻度が低くなっていくのが一般的だ。このような「正規分布の乱数」を作成したいときは関数NORM.INVを活用するとよい。
-

NORM.INVの使い方と標準偏差

第61回や第62回の連載でも紹介したように、Excelの使い方を学習するための「ダミーのデータ表」を作成するときなどに活用できるだろう。
まずは、普通に乱数を生成した例から紹介していこう。以下の図は、関数RANDBETWEENを使って「30~99の整数」をランダムに生成した例だ。
-
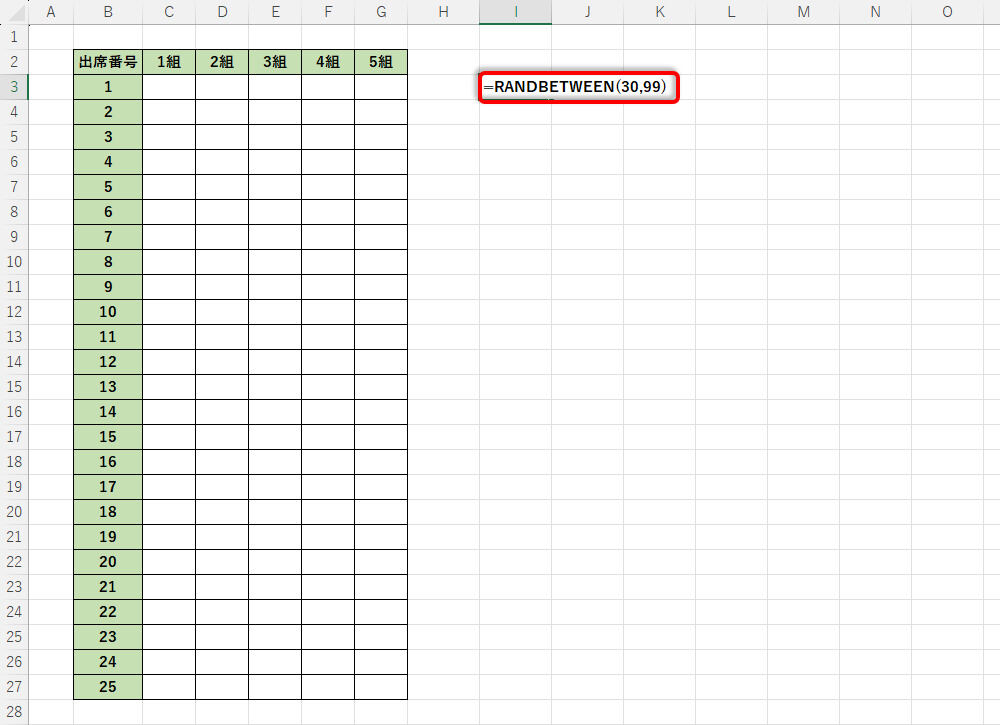
関数RANDBETWEENで30~99の乱数を生成

この関数を縦横にオートフィルでコピーすると、好きな数だけ「30~99の整数」をランダムに生成できる。
-
オートフィルで関数RANDBETWEENをコピーした様子

なお、第61回の連載でも紹介したように、RANDやRANDBETWEENといった関数は「何らかの操作」を行うたびに「新しい乱数」を生成しなおす仕様になっている。いちど生成した乱数を固定しておきたい場合は、コピー&ペーストの操作により「値」だけを表に貼り付けておく必要がある。
-
生成した乱数をコピー

-
「値」として貼り付け

続いては、この乱数が「どのようなデータ分布になっているか?」について調べていこう。データ分布を視覚的に確認したいときはヒストグラムを作成するとよい。Excelにはヒストグラムを作成する機能も用意されているが、あまり使い勝手がよくないので、自分でヒストグラムを作成してみよう。
最初に「30点台」、「40点台」、「50点台」・・・のデータがそれぞれ何個あるかを調べる。この作業は関数COUNTIFSを使うと実現できる。たとえば、「30点台」のデータの個数を調べるときは、
・30以上(I3セル以上)
・39以下(I3セル+9以下)
を条件にデータの個数をカウントすればよい。なお、関数をオートフィルでコピーできるようにセル範囲は「絶対参照」で指定してある。
-
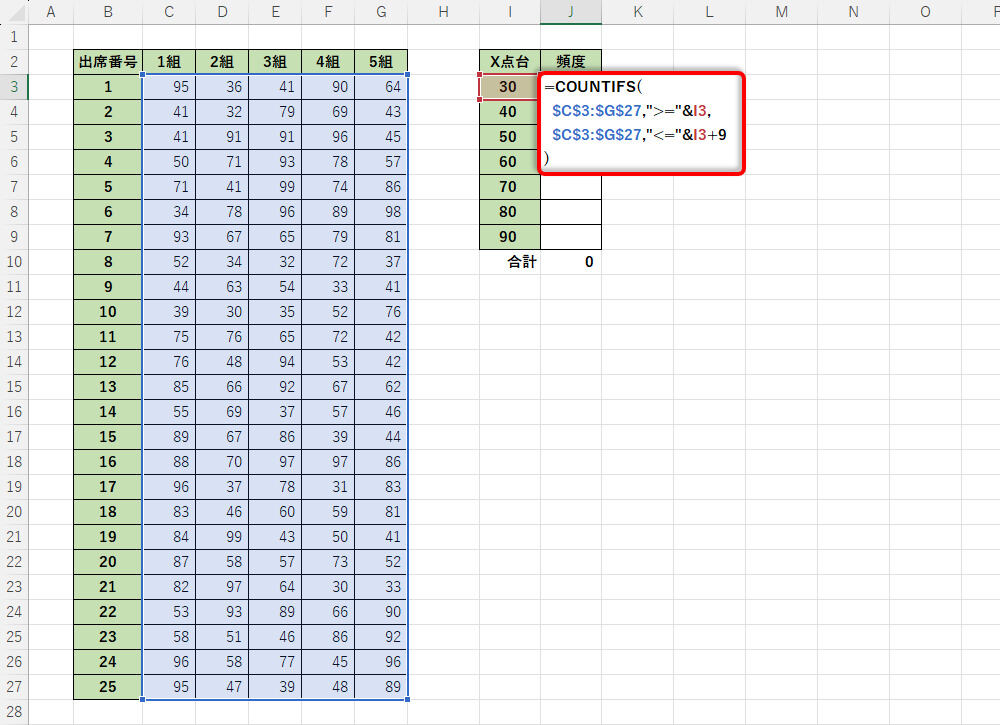
関数COUNTIFSで各階級の頻度をカウント

それぞれの階級(X点台)について「データの個数」をカウントできたら、そのデータを使って棒グラフを作成する。これでデータの分布状況を示すヒストグラムを作成できる。
-
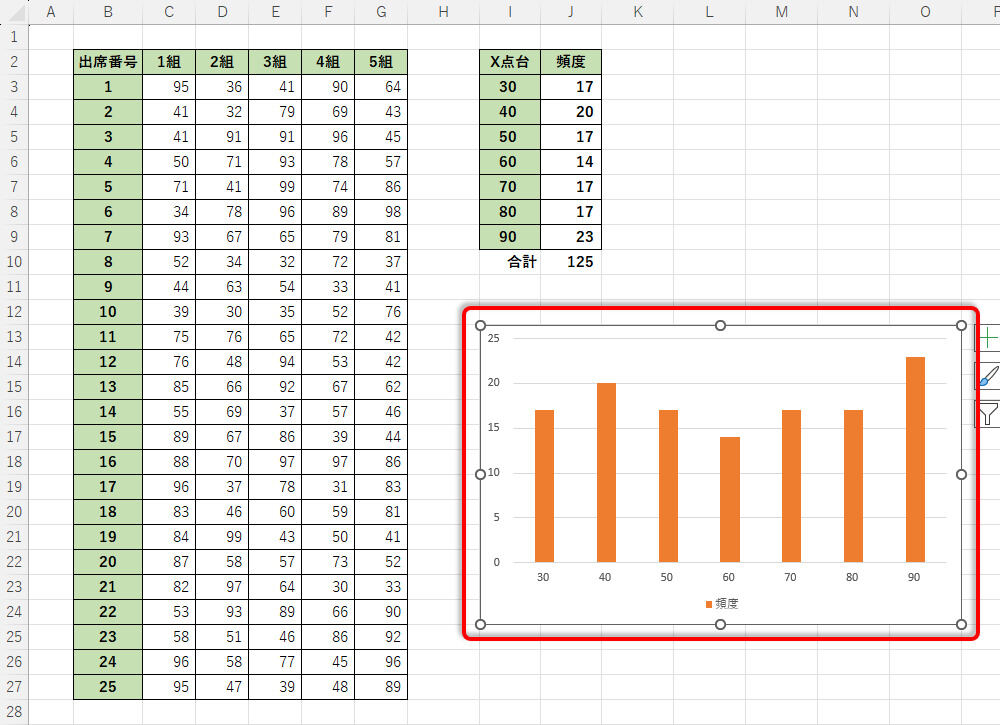
生成した乱数のヒストグラム

今回の例では、上図のようなヒストグラムが作成された。RANDやRANDBETWEENといった関数は乱数を一律に生成するため、多少の“ばらつき”はあるものの、各階級とも大差のないデータ頻度になっている。
このように「一律のデータ分布」ではなく、平均値付近のデータが多い「凸型のデータ分布」にするには、何らかの工夫を施さなければならい。


正規分布に従った乱数の生成
ということで、データ分布が凸型になる「正規分布の乱数」を生成する方法を紹介していこう。この場合は「NORM.INV」という関数を活用する。
◆関数NORM.INVの書式
=NORM.INV(確率, 平均値, 標準偏差)
第1引数には「確率」を0~1の値を指定する。ランダムな数値を生成したい場合は、ここに関数RANDを指定すればよい。続いて、第2引数に「平均値」、第3引数に「標準偏差」を指定する。
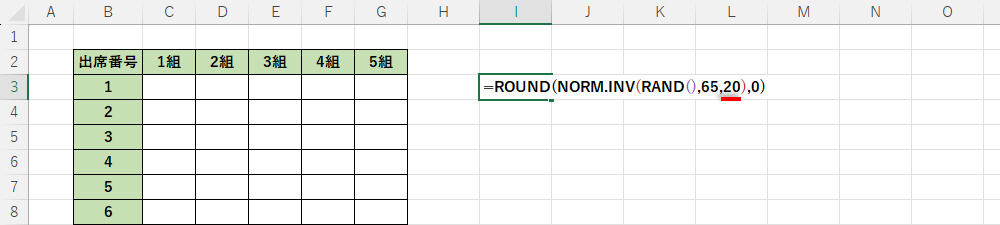
小難しい話をする前に具体的な例を見ていこう。たとえば、平均値を65、標準偏差を10として乱数を生成するときは、以下の図のように関数NORM.INVを記述すればよい。標準偏差の意味がよくわからない方もいると思うが、これについては後ほど詳しく解説する。とりあえずは、標準偏差を10として話を進めていこう。
-
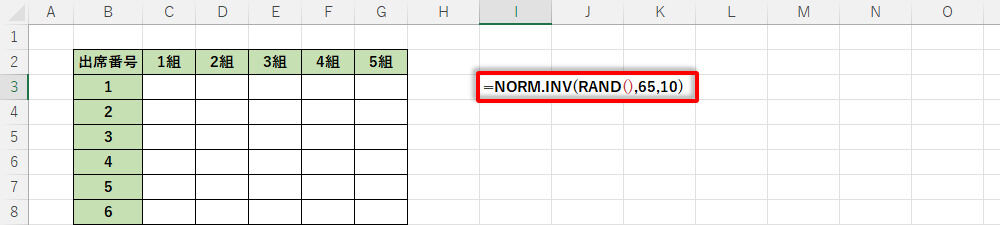
関数NORM.INVの入力

「Enter」キーを押して関数を実行すると、今回の例では「73.1214」という乱数が生成された。
-
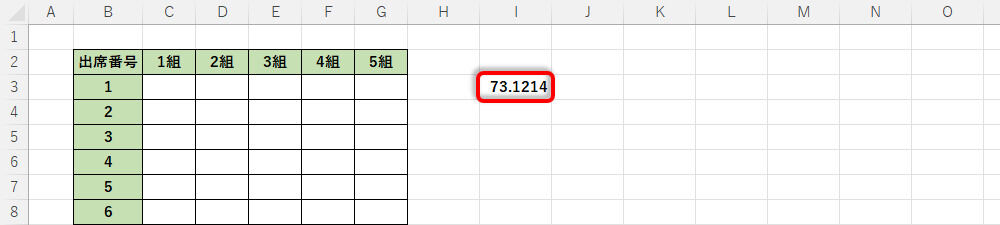
生成された乱数

この数値には小数点以下が含まれている。これを整数にしたいときは、「関数ROUNDで四捨五入する」などの処理を追加してあげる必要がある。
-
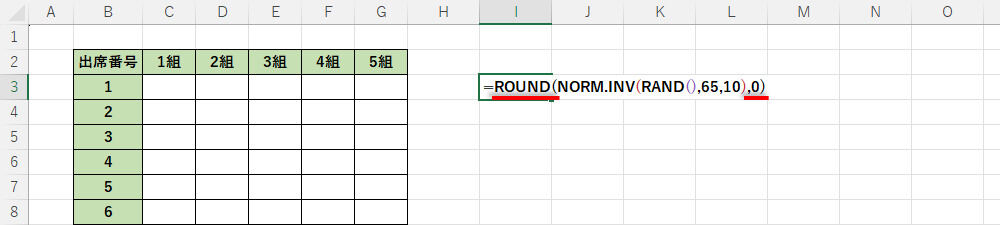
関数ROUNDで四捨五入して「整数の乱数」を生成

-
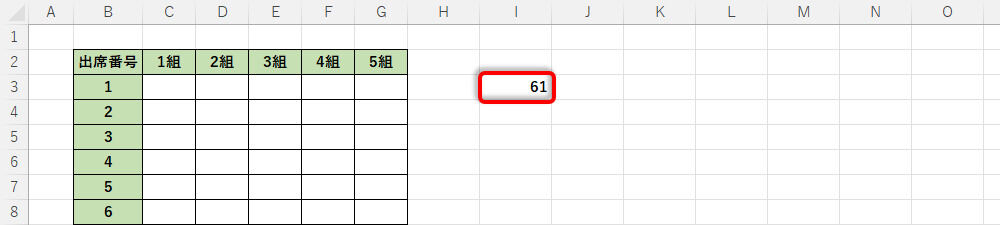
生成された乱数

あとは、この関数をオートフィルでコピーするだけ。これで好きな数だけ「正規分布の乱数」を生成できる。
-
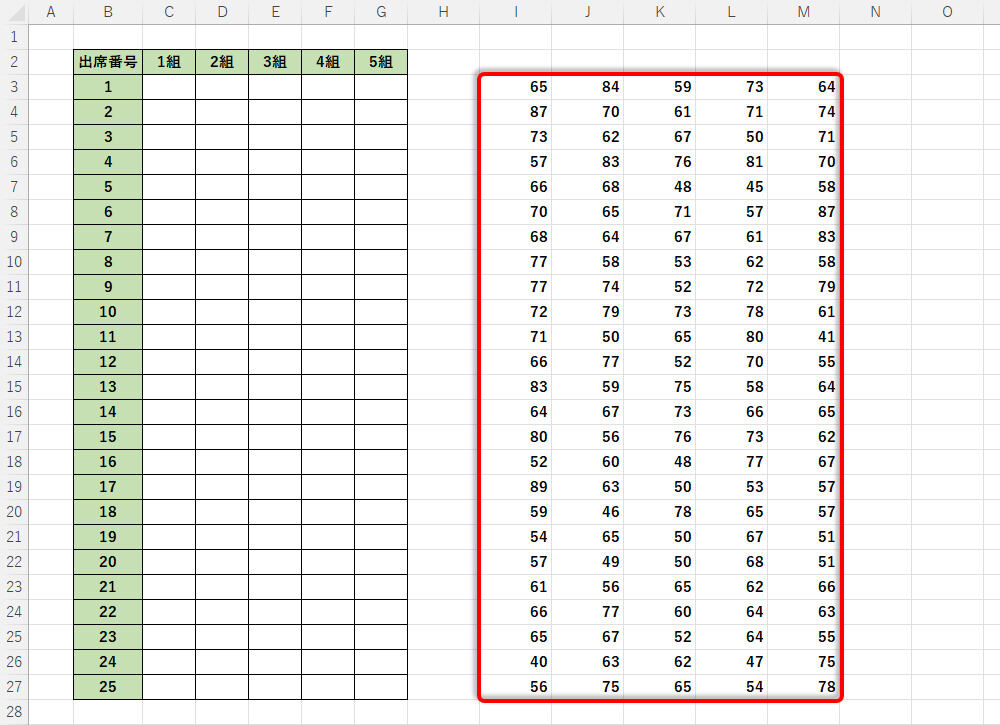
オートフィルで関数をコピーした様子

なお、生成した乱数を固定したいときは、「値」として貼り付けるコピー&ペーストを実行しておくとよい。
-

生成した乱数を「値」として貼り付け

先ほどと同様に、生成した乱数についてデータ分布を調べてみよう。各階級で「データの個数」を調べてヒストグラムを作成すると、以下の図のような結果が得られた。
-
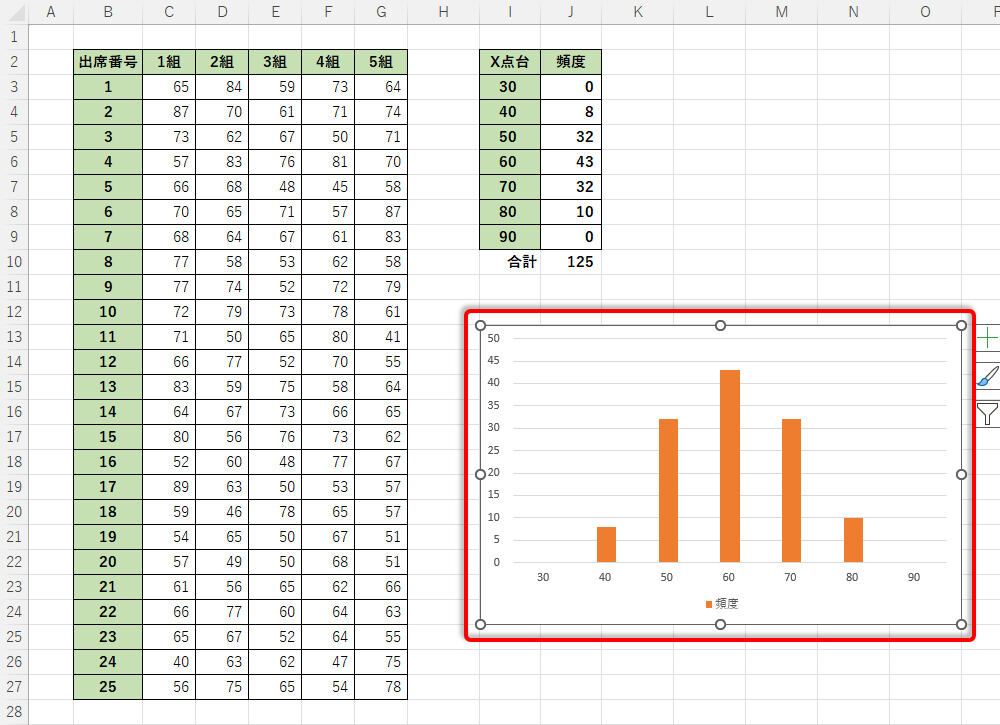
生成した乱数のヒストグラム

平均値に指定した65点(60点台)を中心に、「凸型のデータ分布」になっていることを確認できるだろう。ただし、「30点台」と「90点台」のデータは1個も存在しておらず、期待していたようなデータ分布にはなっていない。これを改善するには「標準偏差」の値を調整する必要がある。
標準偏差の決め方
標準偏差は“データのばらつき”を示す指標で、大きい数値を指定するほど“データのばらつき”は大きくなる。逆に、小さい数値を指定すると、平均値付近にデータが密集したデータ分布になる。
とうことで、標準偏差を20に変更した例を紹介しておこう。関数NORM.INVの第3引数を20に変更する。
-
標準偏差を20に変更

続いて、この関数をオートフィルでコピーすると、以下の図のような乱数を得ることができた。“データのばらつき”が大きくなった結果、100以上の数値も散見されるようになっている。「テストの点数」として考えると、これは不適切な数値といえる。
-
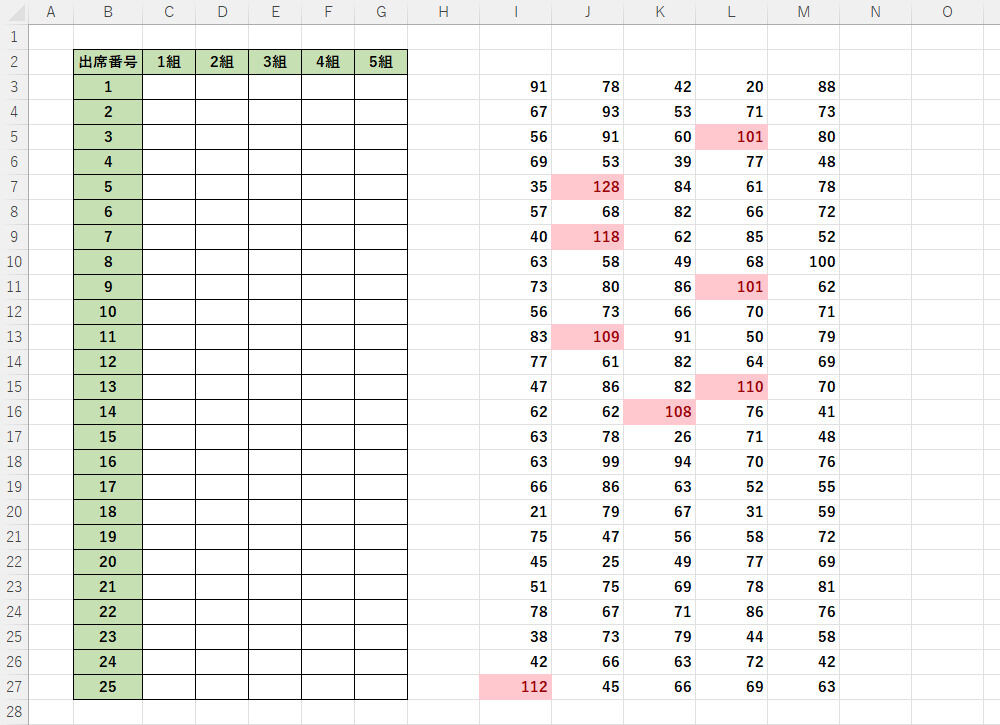
オートフィルで関数をコピーした様子

つまり、「標準偏差20では大きすぎる・・・」ということになる。では、どのような値を標準偏差に指定すべきなのか? 最適な値を最短距離で指定するには、標準偏差の特徴について学んでおく必要がある。
正規分布のデータは、標準偏差の値に応じて「平べったい凸型」や「尖った凸型」のデータ分布になるが、必ず以下の法則が成り立つようになっている。
・(平均値)±(標準偏差×1)の範囲に約68%のデータが含まれる
・(平均値)±(標準偏差×2)の範囲に約95%のデータが含まれる
・(平均値)±(標準偏差×3)の範囲に約100%のデータが含まれる
※厳密には、順に68.27%、95.45%、99.73%のデータが含まれる
よって、平均値を65、標準偏差を20とした場合は、以下のようなデータ分布になると考えられる。
・45~85の範囲に約68%のデータが含まれる(65±20の範囲)
・25~105の範囲に約95%のデータが含まれる(65±40の範囲)
・5~125の範囲に約100%のデータが含まれる(65±60の範囲)
つまり、大半のデータは45~85の範囲にあるものの、一部のデータは100を超えてしまう可能性がある、ということになる。生成される乱数を100以下にするには、(平均値)+(標準偏差×3)が100を超えないように調整しなければならない。
ということで、今度は標準偏差を11.5に変更した例を見ていこう。この場合、65±(11.5×3)=30.5~99.5になるため、100点以内の範囲に約100%のデータが含まれるはず、と考えられる。
-

標準偏差を11.5に変更

オートフィルで関数をコピーすると、以下の図のような乱数が生成された。
-
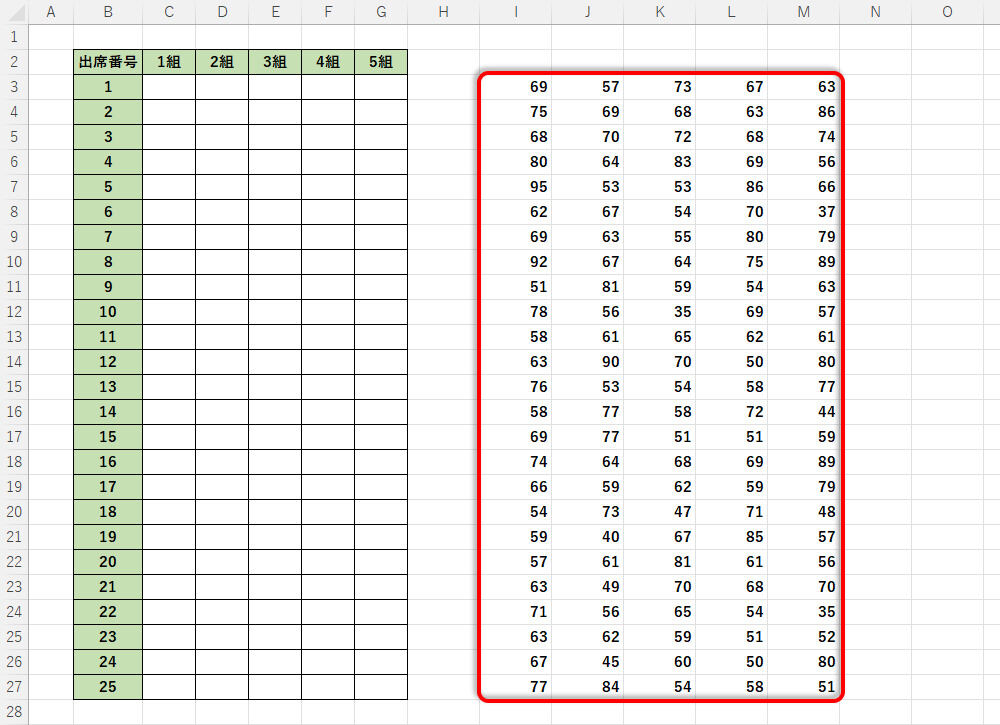
オートフィルで関数をコピーした様子

このままでは状況を把握しづらいので、先ほどと同様の手順でヒストグラムを作成してみよう。
-
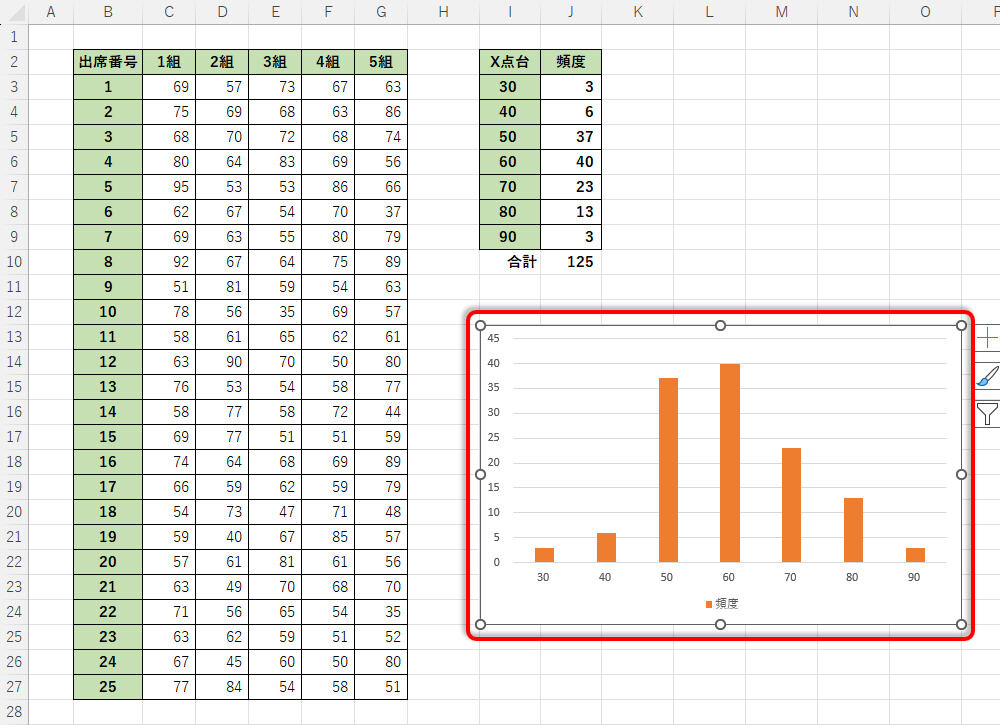
生成した乱数のヒストグラム

今回の例では、「30点台」や「90点台」も若干だけ存在するデータ分布になっている。ただし、少し“ゆがんだ凸型”のヒストグラムになっていることは否めない。乱数によりデータを生成している以上、このように“きれいな凸型”にならないケースもある。特に、今回の例のように100件程度のデータ数の場合は、多少の乱れが生じても不思議はない。
もう少し穏やかな凸型のヒストグラムにしたいときは、関数RANDで指定する「確率」の範囲を調整してみるのも効果的な手法となる。
たとえば、NORM.INVの第1引数を「RAND()*0.95+0.025」に変更すると、0.025~0.975未満の「確率」を指定できるようになる。これは上下2.5%ずつを除外した、中央部の約95%のデータ範囲に相当する。
前述したように、中央部にある「約95%のデータ」は(平均値)±(標準偏差×2)という範囲になるので、これが100以内に収まるように「標準偏差」を調整してあげればよい。平均値が65の場合、標準偏差に17を指定すると(平均値)±(標準偏差×2)が31~99になり、「テストの点数」として適切な範囲になる。
-

RANDの範囲を0.025~0.975、標準偏差を17に変更

この関数をオートフィルでコピーして、先ほどと同じようにヒストグラムを作成すると、以下の図のようなデータ分布の乱数を生成できる可能性が高くなる。
-

生成した乱数のヒストグラム

このように「平均値」の近辺のデータ頻度が高い乱数を生成するには、関数NORM.INVに適切な「標準偏差」を指定してあげる必要がある。少しだけ統計学の知識が必要になるが、気になる方は試してみるとよいだろう。