第38回の連載で「住所」から「都道府県」を抽出する方法を紹介したが、このテクニックは「住所に都道府県が記されていること」が大前提となる。「名古屋市千種区・・・」のように都道府県を省略した住所には対応できない。そこで今回は、変換用のリストを作成し、それに準拠してデータを抽出する方法を紹介していこう。
都道府県が記載されていない住所に対応するには?
ここ数回の連載で「文字列データ」から「特定の文字」を抜き出す方法を色々と紹介してきた。しかし、一般的な手法ではどうやっても対処できないケースもある。たとえば、「名古屋市千種区・・・」という住所から「愛知県」の文字を抽出することは不可能だ。抽出元のデータに存在しない文字を抜き出す、というのは普通に考えて無理な話である。
とはいえ、このように都道府県を省略した形で住所が入力されているケースは意外と多い。「大阪市が大阪府にあるのは当たり前」とか、「札幌市が北海道にあるのは一般常識」という考えのもと、都道府県の記述を省略する人も沢山いるだろう。荷物の配送なら都道府県を省略しても問題なく届くかもしれないが、データ処理においては非常に厄介な問題となる。
そこで今回は「変換用のリスト」を作成し、それに準拠してデータを抽出する方法を紹介していこう。この処理は、関数FIND、IFERROR、FILTER、INDEXを組み合わせることで実現できる。
-

リストに含まれるデータだけを抽出(FIND、IFERROR、FILTER)

今回も「住所」から「都道府県」を抜き出す場合を例にして話を進めていこう。これまでの連載と異なる部分は、「札幌市北区・・・」や「大阪市港区・・・」のように都道府県の記述を省略した住所が散見されることだ。
-
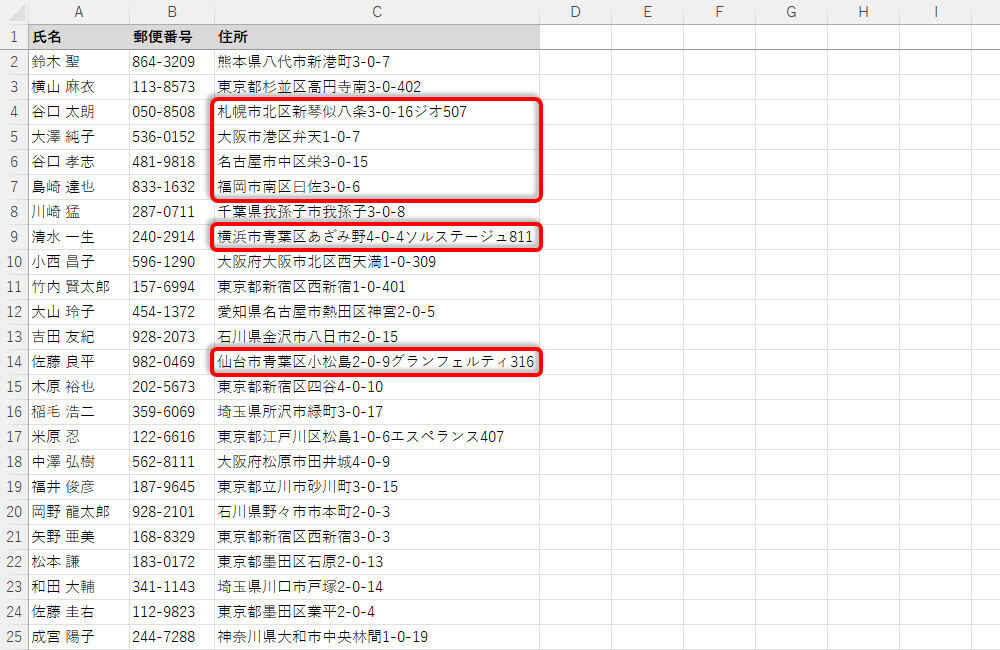
「都道府県」の文字が不足している住所録

第38回の連載で紹介したように、「住所」から「都道府県」を抽出するときは「4文字目が"県"であるか?」などのアルゴリズムに従って文字を抽出する。ただし、このアルゴリズムは「住所が必ず都道府県から始まる」ことが大前提となる。
今回の例のように「市町村から始まる住所」が混在していた場合は、正しく「都道府県」を抽出できない。無理を承知のうえで実際に試してみると、以下の図のような結果が得られた。
-
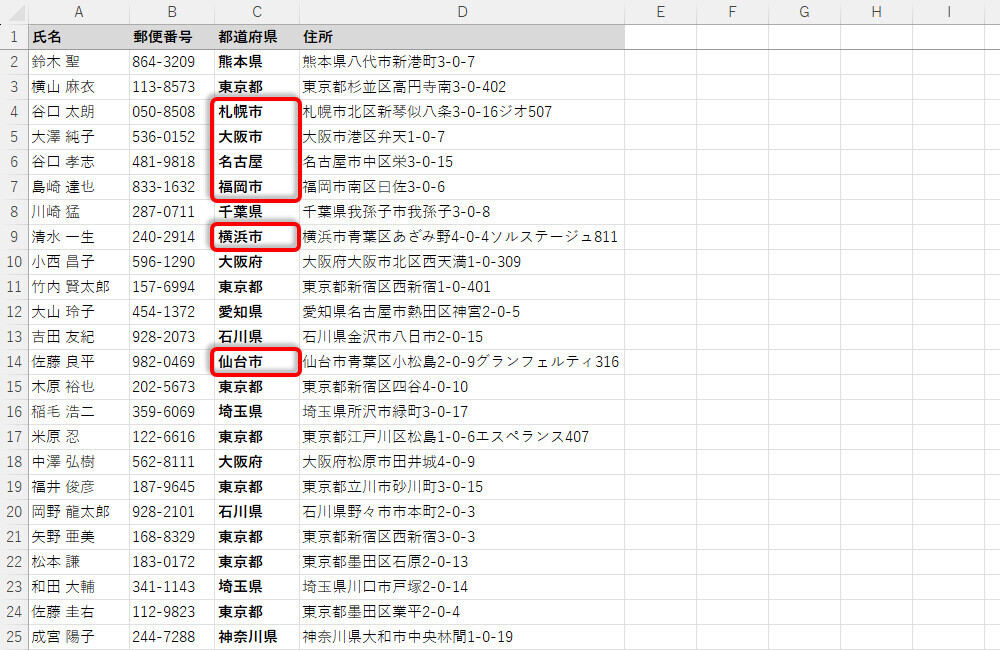
「4文字目が"県"であるか?」で都道府県を抽出した場合

都道府県を省略した住所は、「札幌市」や「大阪市」、「名古屋」、「福岡市」といった具合に先頭の3文字が抽出される。もちろん、このような状態ではデータを都道府県別に分類できない。


変換リストの作成と名前の定義
今回の例のように「データに含まれない文字」を抽出したいときは、「変換用のリスト」を作成してあげるとよい。
まずは「都道府県」を抽出する列を用意する。続いて、以下の図のように「変換用のリスト」を作成する。このとき、いちいち都道府県名を入力るのが面倒な場合は、「都道府県 リスト」などのキーワードでネット検索してみるとよい。コピー&ペーストして使える都道府県名の一覧を簡単に見つけられるだろう。
-
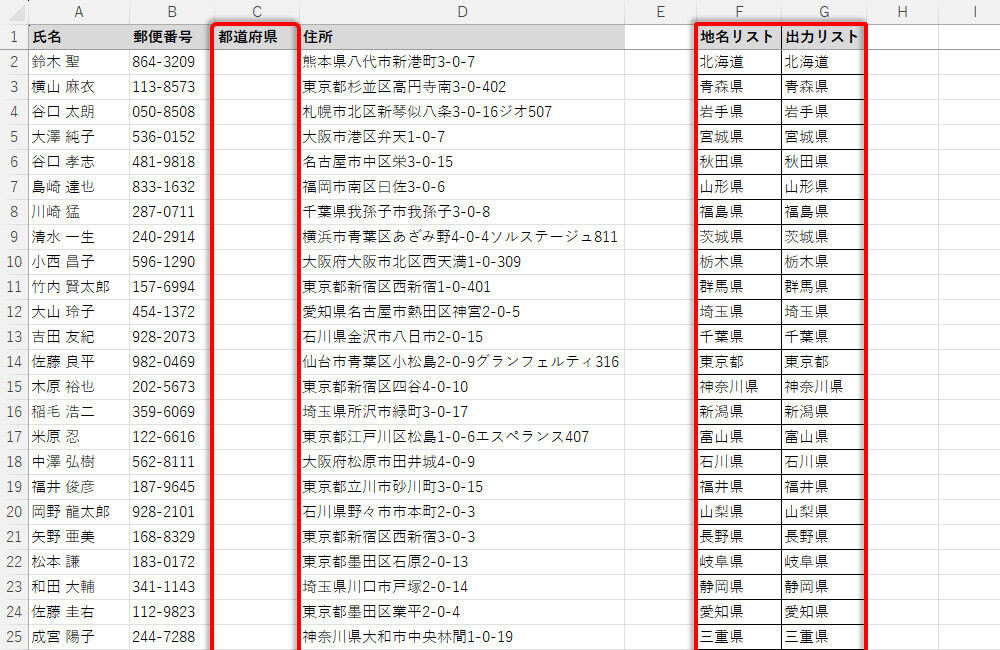
「都道府県」の列を用意し、変換リストを作成

リストを作成するときは「地名リスト」や「出力リスト」などの列を2つ用意し、それぞれに「北海道」~「沖縄県」の文字を入力する。都道府県の場合、必要なデータ数は47組になるが、ある程度の予備欄を設けておくとよい。
-
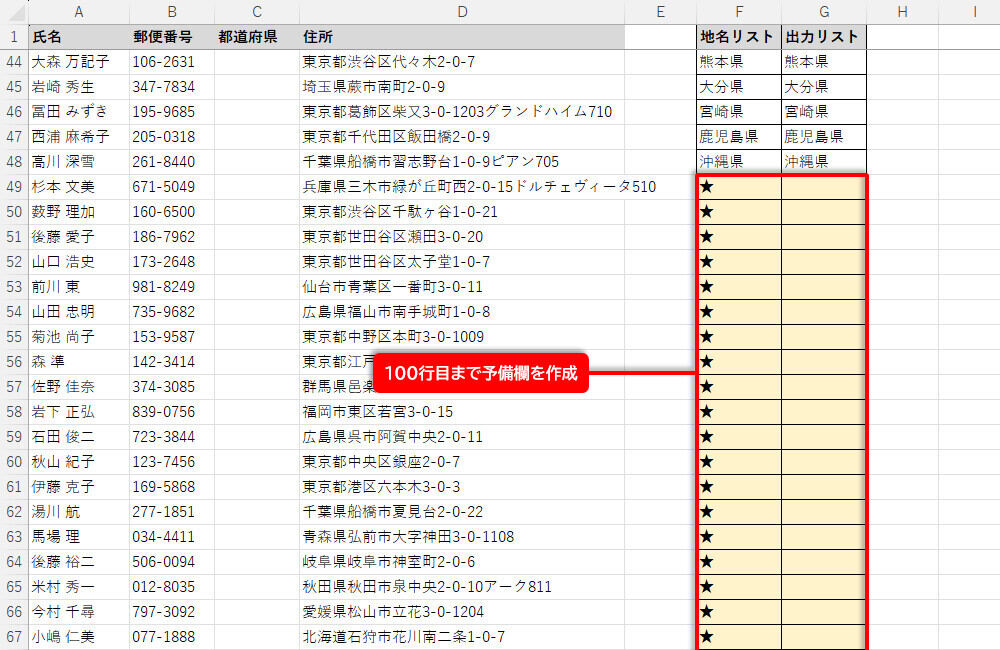
変換リストに予備欄を設ける

今回はワークシートの100行目までリストを作成した。範囲が一目でわかるように、セルの背景を「薄い黄色」で塗りつぶしてある。また、検索用の「地名リスト」には、住所に絶対に含まれない「★」などの文字をダミーとして入力しておく必要がある。
ここまでの作業が済んだら、それぞれのデータ範囲に「名前」を定義しておこう。まずは「地名リスト」のセル範囲だ。今回の例の場合、F列の2~100行目を選択する。続いて、名前ボックスに「地名リスト」と入力し、このセル範囲に名前を定義する。
-

「地名リスト」のセル範囲に名前を定義

同様に「出力リスト」のデータ範囲にも名前を定義しておこう。G列の2~100行目を選択し、名前ボックスに「出力リスト」と入力する。
-
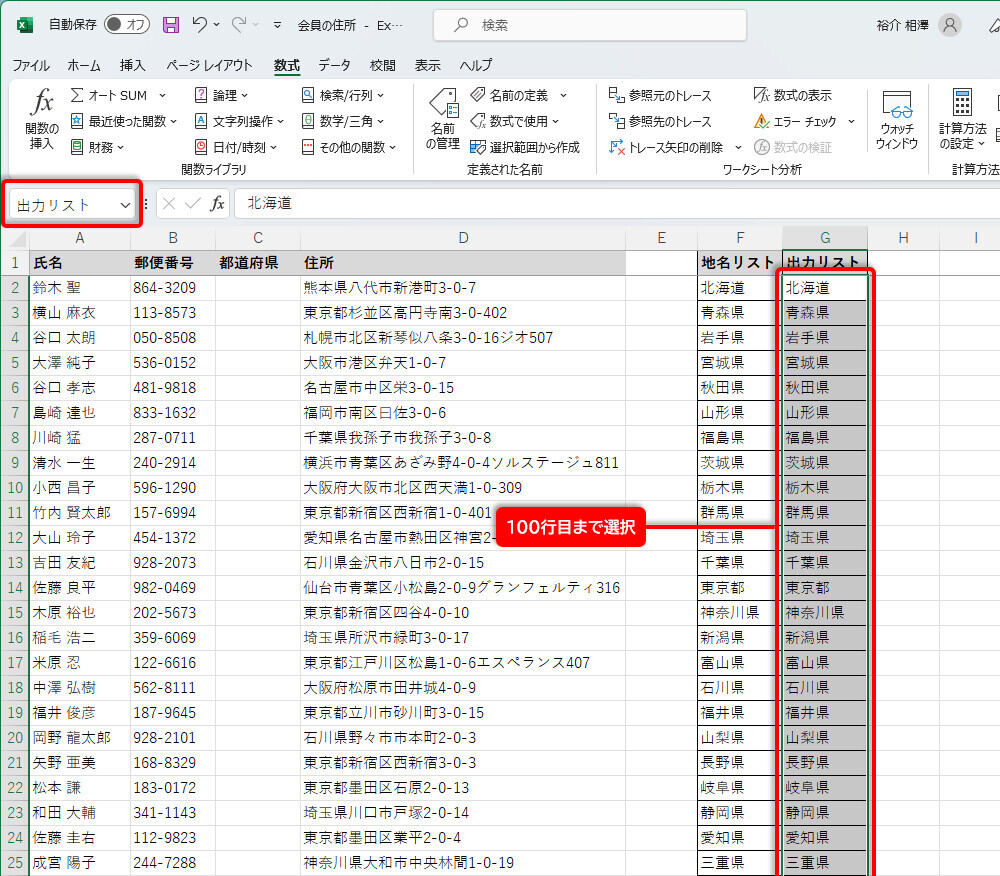
「出力リスト」のセル範囲に名前を定義

これで準備は完了。次は「変換用のリスト」に準拠してデータを抽出する関数を入力していく。
リストに登録されているデータだけを抽出する
今回の例では、以下のような手順で抽出処理を進めていく。
- 「住所」に「地名リスト」の文字が含まれているかを調べる
- 含まれていた場合は、同じ行にある「出力リスト」のデータを抽出する
この処理は、関数FINDとIFERROR、FILTERを組わせて実現する。第26回の連載で紹介した「関数FILTERを部分一致でも検索可能にする裏技」とよく似ているので、そちらも参考にするとよいだろう。
詳しい手順を解説する前に、全体の記述を紹介しておこう。たとえば「住所」がD2セルに入力されていた場合は、以下のように関数を記述する。
=FILTER(出力リスト,IFERROR(FIND(地名リスト,D2),0))
-

部分一致に対応する関数FILTERの入力

内側から順番に解説していこう。まずは、関数FINDで「住所」(D2セル)に「地名リスト」のデータが含まれているかを確認する。
・含まれていた場合 ・・・・・ N番目の数値データが返される
・含まれていない場合 ・・・・ 「#VALUE!」のエラーが発生する
続いて、関数IFERRORで「#VALUE!」のエラーを数値の0に変更する。その結果、返される値は以下のように変化する。
・含まれていた場合 ・・・・・ N(1以上の数値データ:TRUE)
・含まれていない場合 ・・・・ 0(数値データ:FALSE)
「地名リスト」には47件のデータが登録されているので、この結果は「N」または「0」が47個並ぶ配列になる。1以上の数値は「TRUE」、数値の0は「FLASE」とみなせるので、この結果は「TRUE」または「FLASE」が47個並ぶ配列と考えることもできる。
これが関数FILTERの第2引数、すなわち「条件の判定結果」になる。そして、判定結果がTRUEになる行のデータだけが抽出される。関数FILTERの第1引数には「出力リスト」のデータ範囲が指定されているので、「地名リストでTUREと判定されたデータ」と同じ行にある「出力リストのデータ」が抽出されることになる。
先ほど示した図の場合、
・「住所」に「熊本県」の文字が含まれている
・「熊本県」は「地名リスト」の43番目
・判定結果の配列は、43番目だけがTRUE、それ以外はFALSEになる
・「出力リスト」の43番目にある「熊本県」のデータが抽出される
という挙動になる。
あとは、この関数をオートフィルでコピーするだけ。すると、以下の図のような結果を得ることができる。
-
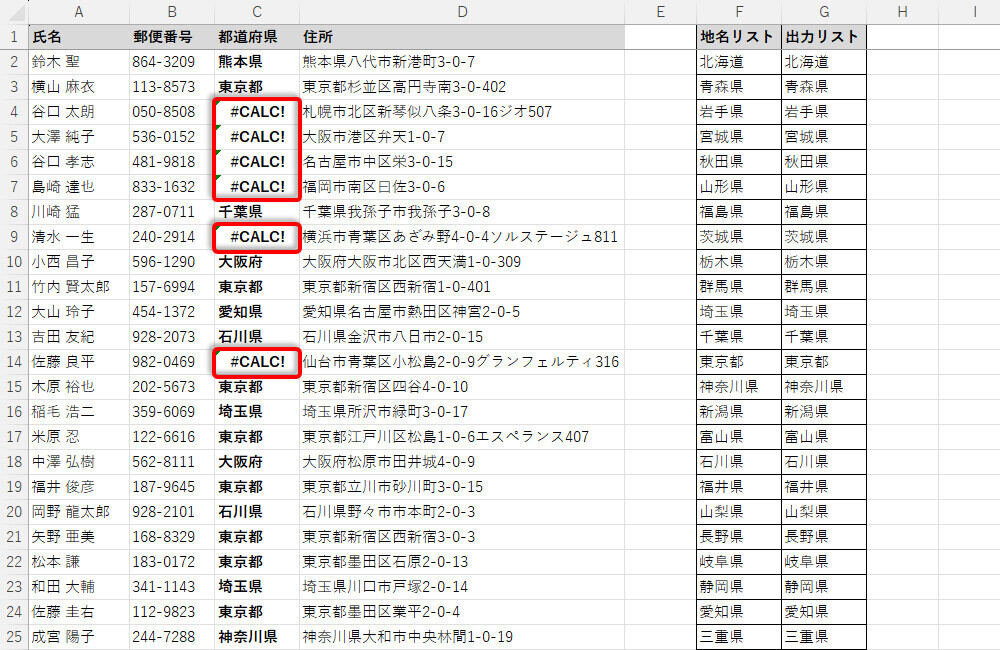
オートフィルで関数をコピーした様子

「住所」に「地名リスト」と同じ文字が含まれていた場合は、その「都道府県」が抽出される。含まれていなかった場合は、関数FILTERで抽出できるデータがないため「#CALC!」のエラーになる。
このように処理することで、「地名リスト」に登録されているデータ(文字)だけを「都道府県」として抽出し、それ以外は抽出しない(エラー)として処理することが可能となる。
あとは、エラーの部分を対処していくだけだ。たとえば、以下の図のように「北海道」の文字を「住所」に補完してあげると、「都道府県」を正しく抽出できるようになる。
-

「住所」に都道府県を補完した例

とはいえ、エラーの数が多いと、一つひとつ「住所」を補完していくのも大変な作業になる。このような場合は「変換用のリスト」の予備欄を活用するとよい。
変換用のデータをリストに登録する
今回のテクニックは、「地名リスト」の文字が含まれていたら、同じ行にある「出力リスト」の文字を抽出する、という処理になる。よって、リストに地名を追加していくことで、都道府県が記述されていない住所にも対応することが可能となる。
たとえば、以下の図のようにデータをリストに追加した場合を考えてみよう。
-

変換用データの登録

この場合、住所に「札幌市」の文字が含まれていたら「北海道」を出力、住所に「仙台市」の文字が含まれていたら「宮城県」を出力、などの処理も自動的に行われるようになる。よって、手作業で「住所」を補完しなくても、正しい「都道府県」を抽出できるデータを増やすことができる。
-

変換リストに従った「都道府県」の抽出

都道府県を省略されやすい住所を「変換用のリスト」に追加しておけば、手作業で対処すべきデータを大幅に削減できるだろう。これが今回のテクニックの最重要ポイントとなる。
その反面、「#スピル!」のエラーが発生する、という不具合が生じてしまう。
-

「#スピル!」のエラー

このエラーは「FILTERで抽出したデータを表示するセルが足りない」ということを示している。試しに「#スピル!」より下にあるデータ(関数)を削除してみると、エラーが解消され、以下の図のような結果になるのを確認できる。
-

「#スピル!」のエラーが発生する原因

上図の場合、「大阪府」と「大阪市」の両方が「地名リスト」に登録されている。よって、以下のような処理が行われる。
・「大阪府」を含んでいる ・・・・ 「大阪府」を抽出
・「大阪市」を含んでいる ・・・・ 「大阪府」を抽出
その結果、2つの「大阪府」が抽出され、それらを表示するセルが足りないため「#スピル!」のエラーが発生してしまう。こういったエラーの対策を施しておく必要がある。
「#スピル!」のエラーに対処する方法
関数FILTERにより「複数のデータ」が抽出された場合は、そのデータは配列として処理される。この配列の中から1番目のデータだけを取得すれば、「複数のデータ」は抽出されなくなり、「#スピル!」のエラーも発生しなくなる。
この処理は関数INDEXで実現できる。具体的には、以下のように全体を関数INDEXで囲み、第2引数に「1」を指定してあげればよい。
=INDEX(FILTER(出力リスト,IFERROR(FIND(地名リスト,D2),0)),1)
-
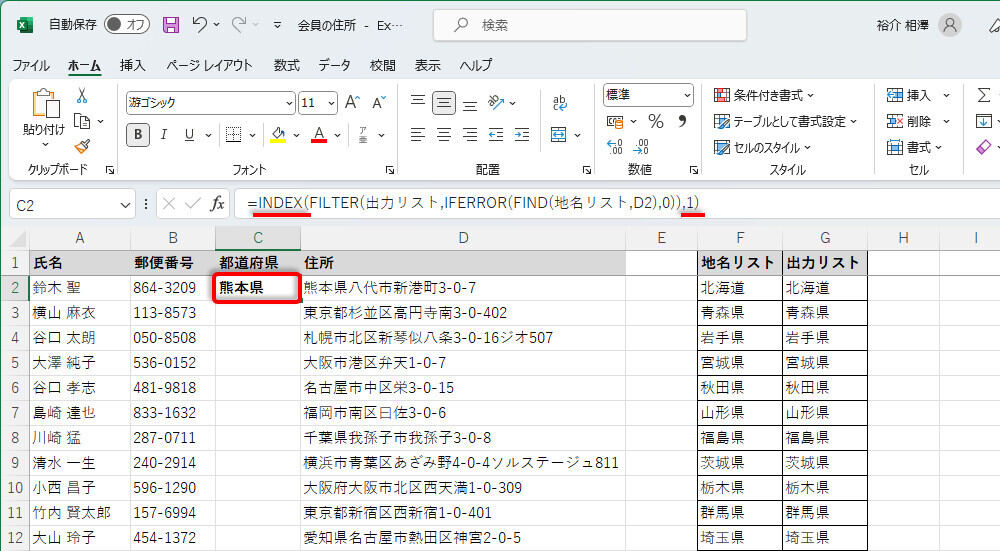
関数INDEXで1番目のデータだけを取得

このように修正した関数をオートフィルでコピーすると、「#スピル!」のエラーを発生させることなく、「都道府県」を抽出できるようになる。
-
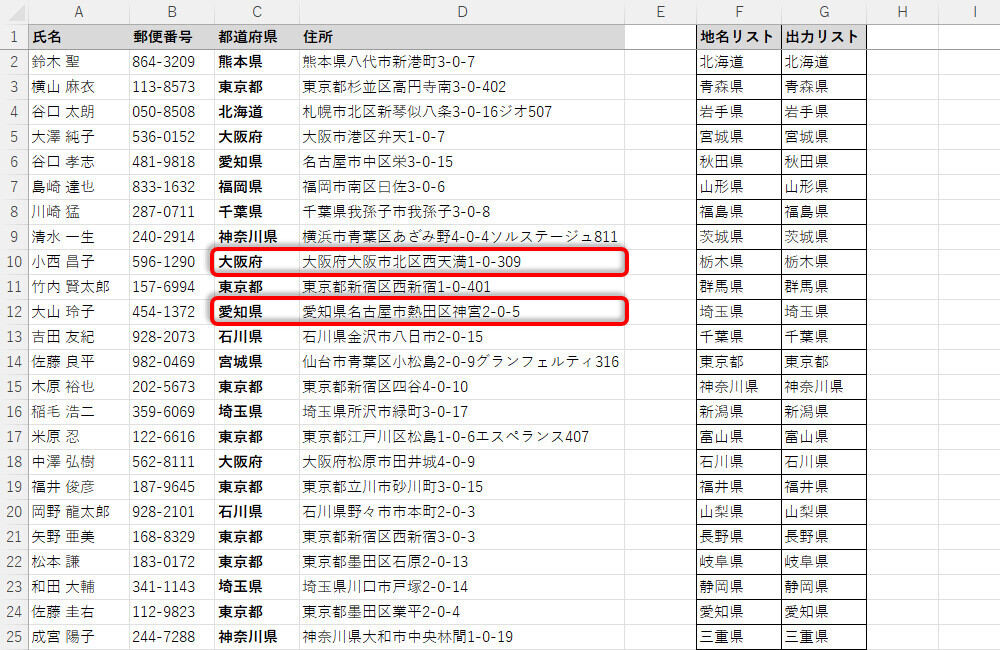
オートフィルで関数をコピーした様子

以上が、今回紹介するテクニックの全体像となる。少し上級者向けの内容になるが、「住所から都道府県を抽出」以外の場面にも応用できるので、よく仕組みを研究しておくと役に立つだろう。
なお、今回の例では「変換用のリスト」をワークシートの100行目まで用意したが、登録する市町村の数が増えてくると「100行目まで」では足りなくなるかもしれない。この場合は「200行目まで」とか、「300行目まで」といった具合に変換用リストを拡張してあげればよい。もちろん、それに合わせて「名前の定義」のセル範囲も修正しておく必要がある。
ただし、「変換用のリスト」を増やしていくと、それだけ処理が遅くなってしまうことに注意しなければならない。極端な話、日本全国の市町村をすべて登録しておけば、あらゆる住所に対応できるようになるが、処理速度はかなり遅くなる。
総務省の資料によると、2023年8月時点における市町村数は1,718もあるそうだ。これらをすべて「変換用のリスト」に登録するのは大変な作業になるだろう。よって、適当な塩梅で「変換リスト」を作成し、それでもエラーになるデータは「都道府県」を手作業で補完する、というのが現実的な使い方になるだろう。