Infineon Technologiesは4月20日にLPDDR4インタフェース(I/F)をもつ自動車向けNOR Flash「SEMPER X1」を発表した。同製品に関する説明会が日本でも5月11日に開催された(Photo01、02)。
-

Photo01:説明を行われたSandeep Krishnegowda氏(Infineon Technologies VP or Marketing and Applications, Flash Memory)

-

Photo02:通訳および補足説明を担当された品田唱秋氏(インフィニオン テクノロジーズ ジャパンのリージョナルマーケティング シニアマネージャー)

今回発表された製品は、要するにこれまでxSPI(x4ないしx8)で接続していたNOR Flashを、LPDDR4のI/Fに切り替える事で、より高速にアクセスできるようにしたというものである(Photo03)。
-

Photo03:なぜランダムリードがxSPI比で20倍にもなるのか、という話は後述

なぜLPDDR4か?というと、まず前提として
- 昨今の先端プロセスではEmbedded Flashを実装できない。今のところTSMCのN12が一番微細化されたものであり、あとはMRAMとかPCMという話になるが、どちらもまだ成熟しているとは言えない。先端プロセスへのEmbedded Flashの実装の研究も進んでいるが、まだ7nm世代への対応は遠い。
- その一方で特に自動運転などに絡む部分は先端プロセスを利用して性能を引き上げる方向に突っ走っている。これは自動運転の実装にはそうした性能が必要と言う話であり、これを下げる方向にはいかない。実際TSMCは2020年5月には7nm世代の自動車向けプロセスを発表、2021年にはN5Aについて言及しており、今年4月に開催されたTSMC Technology Symposiumでは2024年にN3AE(Automotive Early)、2026年にはN3Aを提供すると発表した。こうした先端プロセスではもはやEmbedded Flashは実現できない、という問題がある。
そこでこうした先端プロセスを利用するプロセッサはNOR Flashを外付けにせざるを得ないのだが、今度はその速度が問題になる。というのはxSPIだとx8で400MB/sec、x16でも800MB/secでしかない。先端プロセスを使うプロセッサが例えば2GHz駆動で、デコーダが平均2Bytes/cycleで命令を読み込んだとしても4GB/secの帯域が必要になるからだ(実際は平均2Bytes/cycleはかなり少ない想定である)。これはキャッシュなどを併用しても、十分な性能とは言えない。しかしながら
- そもそもxSPIベースでは性能の向上に限界がある
- HyperBusもxSPIの延長でしかない
- xSPIを複数並べるのは配線やBOMコストの増加につながるから好ましくない
- 新規の独自I/Fは好まれない
ということになると、あとはUFSかDDR/LPDDR系ということになる。もっともUFSにしても、UFS 4.0ですら最大で5.8GB/secで、xSPIよりはマシにしても頭打ち感がある。もう少しヘッドルームを、という事になるとDDRかLPDDR系に行きつくのは自然な流れである。
-

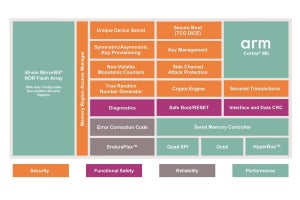
Photo04:もちろんスピードを上げてもNOR Flashが付いてこないので、内部はマルチバンクのInterleave Accessにして稼ぐ形になる

そんな訳でSEMPER X1はxSPIだけでなく、LPDDR4のI/Fを持つことになった。ただこの実装が少し独特である。SEMPER X1と従来型のxSPI NORとの比較がPhoto05、LPDDR4 DRAMとの比較がPhoto06である。
-

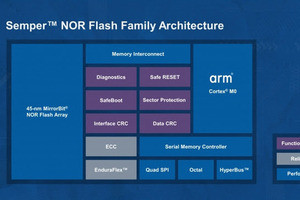
Photo05:従来のSEMPERはMirrorBitを利用していたが、今回のSEMPER X1は記憶方法としてeCT(Embedded Charge Trap)を利用している

-
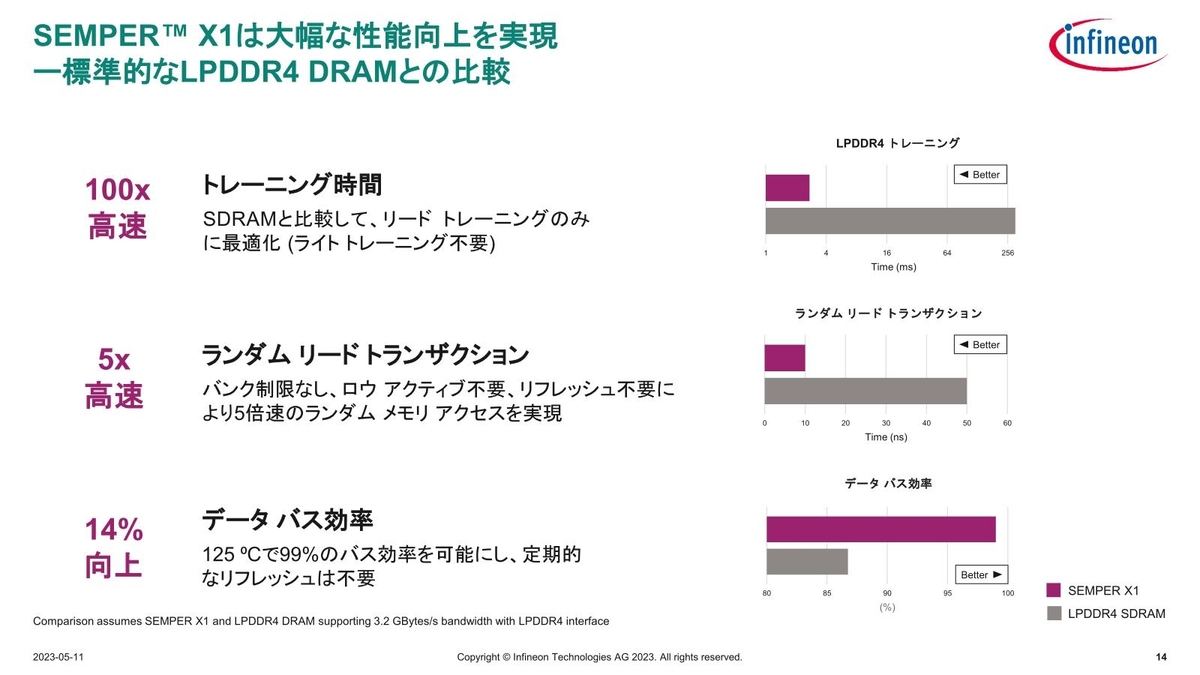
Photo06:このメリットを享受するためには、メモリコントローラの方にも手を入れる必要がある

まずPhoto05に関しては、何しろxSPIだと信号速度が最大でも400Mbps/pinに制限され、あとはレーン数を増やすしかないし、コマンド/アドレスバスとデータバスを多重化している関係でパイプライン動作が出来ない。ランダムアクセスが高速化した最大の理由は、LPDDR4だとコマンド/アドレスとデータバスが別々になっているので、パイプラインアクセスが出来るのが大きな要因とされる。
次いでPhoto06だが、なぜ? と思われる方も居るかと思う。SEMPER X1のLPDDR4 I/Fは
- Read Accessのみ対応。Writeは従来のxSPI経由となる
- そもそもBank selectorとかRow Activeとかは発生しないし、Refreshという概念もない。なのでこうしたリクエストがコントローラから来ても無視する
- 通常温度が上がるとRefresh頻度を引き上げる操作が行われるが、SEMPER X1は自動車向けということで125℃までの動作温度範囲をサポートしており、なのでRefreshが要らない(から効率が上がる)
という仕組みである。
上で説明したように、SEMPER X1の目的は高速なプロセッサのプログラムメモリの代替である。ということは、書き込みというのは基本発生しない(システムの起動に先駆け、プログラムをロードするときのみ)から、Read Accessのみで十分という割り切りである。もちろん今後はFlashに書き込みたいという用途もありえるだろうが、もともとNOR Flashだからそれほど書き込み寿命が高い訳では無い(自動車向けということでデータ保持期間は長いだろうが)。もし煩雑に書き込みをしたいのであれば、SRAMなりFRAMなりMRAMなり、と他のソリューションを使う方が賢明であり、今回は読み込みだけに絞った、というのがその理由だそうだ。この結果、例えば初期化時のLPDDRのBus TrainingはReadだけを行えば済むから高速、という訳だ。
ただ、既存のLPDDR4のI/Fを使った場合、勝手にBank Selectionを掛けたり、Row Activeを発生させたりするし、Refreshも自動挿入される。ReadだけではなくWriteのTrainingも行おうとするだろう。なので、このPhoto06に示されたメリットを享受するためには、SEMPER X1に最適化した(要するに余分な事をしない)LPDDR4 I/Fを作る必要があり、それをしない場合はLPDDR4 DRAMとの差は無いということになる。ただ差が無いだけで一応既存のLPDDR4 I/Fに直結させることは可能、との事であった。
パッケージの方もJEDECのLPDDR4の標準に合わせ、1ch、x8、Single Endedから2ch、x16、Differentialまで自由に設定できるとの事だった(Photo07~09)。また現状はそんなわけで信号をLPDDR4に合わせた独自規格という事になっているが、現在JEDECでLPDDR4 Flashの仕様策定に向けて動いているとの話であった。
-
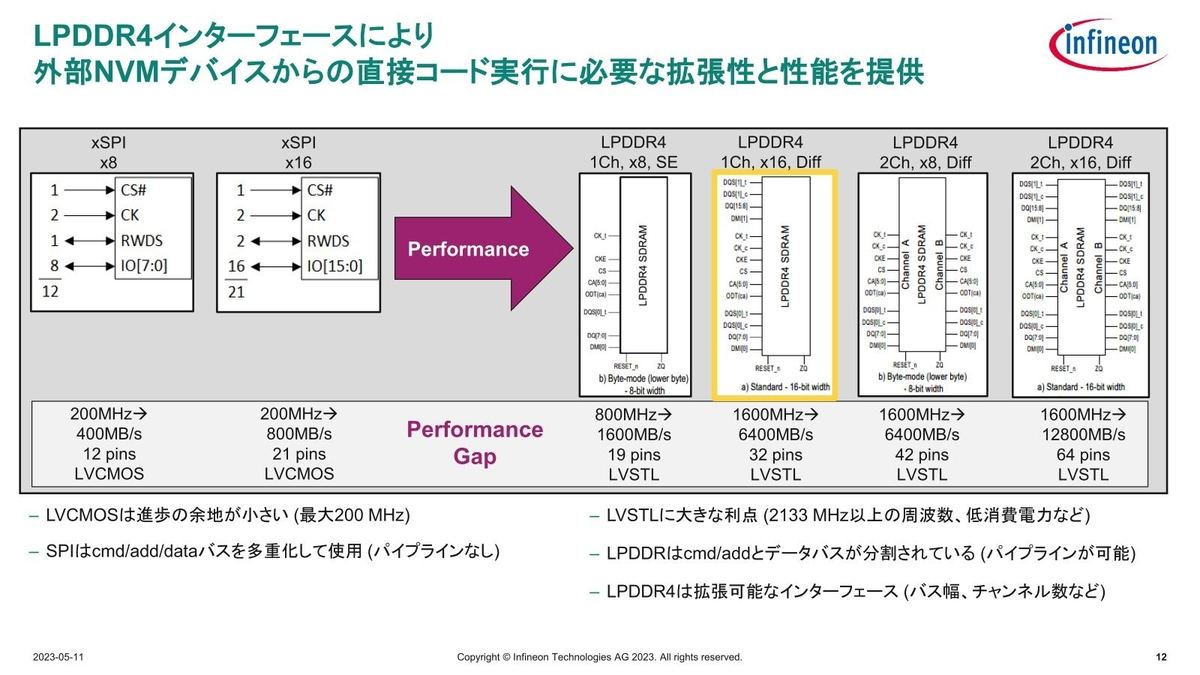
Photo07:先ほどの数字はxSPIと1Ch、x16、Differentialの構成を比較した場合の話である

-

Photo08:パッケージ裏面を示すKrishnegowda氏(の右手)

-

Photo09:サンプル品。実際はまだ顧客に出す以前の、社内試験用に向けての、出たばかりの最初のものとの事

ちなみに製造はUMCの40nmプロセスである(eCTそのものがUMCの40nmを前提にした技術であるのだが)。容量は288Mbit品と576Mbit品が提供予定。ISO 26262 ASIL-B準拠/ASIL-D対応可能で、ダウンタイム0のOTA Updateが可能となっている。現在はサンプル出荷中であり、量産出荷は2024年を予定しているとの事である。