日本マイクロソフトは3月23日、同社のヘルスケア分野における最新の取り組みを紹介するオンライン記者説明会を開いた。
ヘルスケア分野において同社は、患者それぞれに合った医療行為を実施する「精密医療(プレシジョン医療)」の実現に向けて、医療機関や公的機関、業界関連企業に対するテクノロジー面の支援を続けている。
説明会では、プレシジョン医療の実現支援のために同社が提供するクラウドプラットフォームの最新情報とともに、ヘルスケア業界におけるAI活用の可能性が示された。
データ分析基盤「Azure Health Data Services」を国内でも提供開始予定
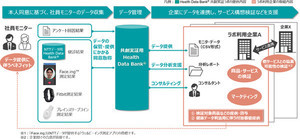
日本マイクロソフトは2023年の上期中に、データの統合的な連携と分析のためのプラットフォーム「Azure Health Data Services」を日本で提供開始する予定だ(グローバルでは2022年から提供開始済み)。
同サービスはAzure API for FHIR(Fast Healthcare Interoperability Resources)の後継版となり、構造化データ・画像などの非構造化データ異なる種類のデータをクラウド上で統合し、管理・分析することができる。また、個人のヘルスケアデータを取集するためにウェアラブルデバイスと連携することも可能だ。


HL7 FHIRや、DICOM(Digital Imaging and Communication in Medicine)などヘルスケア業界の標準規格にも準拠しており、同社はセキュリティ要件を満たしたデータ連携基盤として同サービスを提供する方針だ。
-

ヘルスケア業界のデータ連携プラットフォームとして「Azure Health Data Services」の国内提供が開始する予定だ

日本マイクロソフト 業務執行役員 ヘルスケア統括本部長の大山訓弘氏は、「医療データを扱い、連携・保存・分析していくための主軸のサービスとして提供していく。現時点で複数の国内パートナーから引き合いがあり、当サービスを利用したアプリケーション開発の要望も受けている」と説明した。
-

日本マイクロソフト 業務執行役員 ヘルスケア統括本部長 大山訓弘氏

個人の健康情報に関するデータであるPHR(Personal Healthcare Record)の管理・活用において、マイクロソフトはPHRの普及やデータの相互運用性、取り扱いの標準化を推進している。Azure Health Data Servicesには、PHRを収集するための機能も実装されているという。
「PHRと電子カルテの連携やPHR同士の連携はこれから実現していく段階にある。PHRを業界標準的に利用できるよう、行政や臨床学会が求める標準化ガイドラインや有識者による協議会などとの連携も継続していく」と大山氏。
医学論文の検索や臨床現場でのメモ作成など、幅広いAIの活用領域
ヘルスケア業界におけるAIの活用領域について、マイクロソフトでは患者とのコミュニケーションの自動化・効率化、複雑なカルテ情報や研究論文の解読・要約、医療機関内に散在するさまざまな情報の横断的な検索とレコメンド、画像診断のサポートなどを想定しているという。
すでにマイクロソフトは、OpenAIのGPT-2ベースで開発した生物医学分野特化の言語モデル「BioGPT」を提供している。同サービスについて大山氏は「PubMedの生物医学論文の英語テキストをベースとしているモデルだ。対話型で必要な情報を収集できるため、専門家と同等レベルの情報収集も可能になる。今後はGPT-4のモデル利用と併せて、日本語も含めた領域での活用も見込まれる」と述べた。
-

「BioGPT」の概要

2023年3月20日(米国時間)には、会話型AIとアンビエントAI、GPT-4を組み合わせた臨床文書作成を自動化できる医療従事者向けアプリケーション「Dragon Ambient eXperience (DAX) Express」の提供が発表された。DAX Expressを用いた実証実験では、文章のベースとなるメモの作成を数秒で完了することができたという。
「今後は患者と医師が会話をするだけで、臨床文書を作成することも可能になるのではないか。それにより、文章作成の作業時間を減らして、医師が患者に向き合う時間をより多く確保できるようになることを期待する」(大山氏)
厚労省のゲノム解析プロジェクトではデータ分析のITインフラ整備が課題に
他方で、マイクロソフトはゲノム解析の分野において、Microsoft CloudやMicrosoft Azureを通じてコンピューティングリソースやデータ分析ツールなどの解析環境のほか、研究者などの共同作業を支援するツールとしてMicrosoft Power PlatformやMicrosoft Teamsなどを提供している。
-

マイクロソフトがゲノム解析分野で提供するサービスなど

国内におけるゲノム解析の取り組み例としては、厚生労働省が主導する国家プロジェクト「全ゲノム解析等実行計画」が紹介された。同プロジェクトでは、人の全ゲノム情報を解析し、ゲノム医療の飛躍的な向上と、治療法のない疾病に対する新たな個別化医療の提供を目指している。
同プロジェクトでは将来的に、年間40万人分の全ゲノム解析の実現を目指すが、スーパーコンピュータで処理するデータ量が160ペタバイトと膨大になることが想定されている。また、人と共生しているマイクロバイオーム(細菌、ウイルスなど)や、生活環境から得られる健康関連のデータも解析対象になる。分析対象となるデータの形式も文字列、実数、画像などと多様で、データ解析のためのITインフラの整備が課題となっている。
-

「全ゲノム解析等実行計画」では2025年度中の事業化を計画している。課題となるのが膨大で多様な形式のデータを解析するためのITインフラだ

プロジェクトの解析・データWG(ワーキンググループ) WG長を務める東京大学 医科学研究所 博士の井元清哉氏は、「蓄積されたビッグデータをアカデミアや企業がセキュアに解析し、それぞれの解析に活用できる仕組みが必要となり、プロジェクトで利用するITインフラのクラウド移行を検討している。マイクロソフトには、データ分析のためのプラットフォームの提供とともに、多様な情報を統合的に解析して人が解釈可能な形で提示できるようなAI技術を期待する」と述べた。
-

東京大学 医科学研究所 博士 井元清哉氏