英Graphcoreは3月3日、同社の第3世代IPU(Intelligence Processing Unit)である「BOW」を発表した。これに関してオンラインで説明会が開催されたので、その内容をベースにちょっとご紹介したいと思う。
まず最初にGraphcoreの製品そのものについてを説明したい。過去、安藤先生が何回か名前に触れた程度で、きちんと紹介している記事がなかったのでまずはこちらからご説明したいと思う。
英国で誕生したAIプロセッサのスタートアップ
Graphcoreは2016年に英ブリストルで創業された、AIプロセッサのスタートアップ企業である。創業者は現CEOのNigel Toon氏と、現CTO兼EVP,EngineeringのSimon Knowles氏の二人。実際のスタート時期は2012年である。
この2012年は丁度二人とも立ち上げたビジネスのExit(Toon氏はpicoChipという会社をMindspeed Technologyに売却、Knowles氏は立ち上げたIceraがNVIDIAに買収された)を終えたばかりで、そこで意気投合してか新しい会社を立ち上げる事を決め(何故ここでAI Processorを作る事を決めたのかは不明)、2013年末にはStealth ModeのままProjectをスタート、開発チームを集め始める。
2人には会社をExitしたことによる売却益があり、数年間の間、外部資金無しでベンチャーを回すだけの資金があったことが幸いしたのだろう。2016年にStealth Modeを抜けて会社を立ち上げた後は複数のベンチャーキャピタルからシリーズA(2016年10月、3200万ドル)、シリーズB(2017年7月、3000万ドル)、シリーズC(2017年10月、5000万ドル)を調達している。
2018年7月には最初のIPUを特定顧客にアーリーアクセスとして出荷すると共にICML 2018ではPCIeカードの形での動作デモも実施。同年末にはシリーズDで2億ドルの資金を調達。この際の出資企業にはMicrosoftも入っており、それもあって2019年にはMicrosoft Azureの上で同社のIPUの利用も可能になっている。この2019年には本格的な量産もスタート。完成製品をDellから直接購入することも可能になった。
2020年7月には第2世代IPUが発表されるが、これに先立ち同年2月には1億5000万ドルをシリーズD2としてファンドから調達。4月には東京オフィスも開設されている。そんな訳で、AIプロセッサのスタートアップ企業としては、かなり順調に拡大しつつあるのがGraphcoreという訳だ。
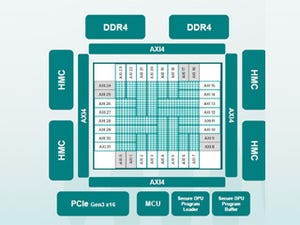
さてそのGraphcoreが提供しているのがIPUである。Photo01が第1世代のIPUである「Colossus Mk1 GC2 IPU」の構成を示したものだ。
-

Photo01:トータル300MBというのは、256KB×1216Tile=304MBというところから出てくる。ちなみに6 Execute Contextというのは同時に6つのプログラムを同時に走らせられるという訳ではなく、SMT式に6つのContextの内1つを走らせる格好と思われる

同社はいまだにIPUの内部のパイプライン構造とかの詳細を説明していないが、内部的には1216個のIPU-Tileと呼ばれるプロセッサコアとメモリが密結合したユニットが置かれる。同社のポリシーとしては、なるべく演算効率(性能/消費電力比)を引き上げるためには外部にメモリ(HBM2など)を置かずに内部のSRAM(256KB)と密結合させた方が、効率も上がる上にメモリ帯域も広くとれる(ただしその分プロセッサ密度は低下する)という判断である。ちなみに各IPU-Tileは6つの実行Contextを保持可能(Thread、としてしまって良いのかは議論が残る)とされる。
もう1つの特徴は、そのTile間の通信方式である。IPUの場合、当初からマルチチップ構成を想定しているため、Tile間の通信は同じチップ(というか、ダイ)内とチップ間を跨ぐ通信の両方があり得る。これを実装するにあたり、いわゆるGlobal Clockを使っての同期ではなく、データ通信のタイミングでSync信号が送り出され、このSync信号に合わせてすべてのIPUが処理をスタートするという、広義には同期式でありながらいわゆるDataflowに近い処理が実装されているのも珍しい。ちなみにSyncはチップ内の通信用とチップ外の通信用の2つがある。
さてこの第1世代のColossus MK1 GC2 IPUはTSMCの16nmプロセスで製造され、1.6GHz駆動である。1cycleあたりのIPUの処理性能は16Flopsで、FP32の場合で言えばチップ全体で31.1TFlops、Mixed Precision(加算32bit/乗算16bit)だと124.5TFlopsと説明されている。ただし商品としてリリースされたC2カード(Photo02)には、2つのチップが搭載され、間が同社のIPU-Linkで接続される構造となっており、性能としてはそんな訳でFP32で62.2TFlops、Mixed Precisionでは249TFlopsとなる訳である。
-

Photo02:物凄い見かけであるが、2Slot厚のPCIeカードである。カード上面に突き出しているのはIPU-Linkのコネクタ。補助電源はカード後端に8pin×1が装備される

-

Photo03:どうもIPU-Linkは80対のものを8対でセットにして10 Linkという形になっている模様。で、2チップではチップ間を6 Link(48本)でつないでいると思われる

このC2カード、初代IPUベースという事もあってもうGraphcoreのサイトから情報が落ちているが、DTW 2019における展示をServeTheHomeがYouTubeで掲載しているので、興味ある方はご覧いただくのが良いだろう。
これに続くのが、TSMCの7nm(N7)に移行した第2世代のColossus MK2 GC200 IPUである(Photo04)。
-

Photo04:基本的にはTileが増えているだけ。ちなみにMK2からはThreadという用語を使う様になった

基本的な構成は変わらないが、IPU-Coreの数は1472個に増えるとともに、TileあたりのSRAM容量が256KB→624KBに大きく増やされている。第1世代の弱点はやはりこのSRAMであり、256KBにデータとプログラム(しかも6つ分)を格納するのはやはり相当厳しく、それもあって必ずしも効率が良くなかった。これが大きく改善した格好だ。またIPU自身も新たにFP16.16(乗加算共に16bit)とFP16.SR(確率的丸め処理付きFP16)をサポートするなどしている。動作周波数は1.35GHzに落ちたが、メモリの大容量化やこのFP16.16/FP16.SRのサポートにより、MK2では4チップで1PFlopsの処理性能と説明されている。チップあたり250TFlopsという計算で、これはMK1の2倍に当たる性能である。
ただこの結果として、MK2ではTSMC N7を使いながら、トランジスタは594億個。ダイサイズは823平方mmと説明されており(Photo05)、700平方mmを超えていたMK1をさらに上回るサイズに膨れ上がっている。
-

Photo05:HBM2などを持たないにも関わらず、「デカい」という印象

また製品の提供形態も変わり、従来のPCIeカードに変わり、4つのMK2を搭載したIPU-M2000というブレードサーバーでの形に切り替わった(Photo06)。
-

Photo06:厚みは1Uサイズ

このM2000には、4つのMK2の他、IPU Gatewayと呼ばれる管理用チップ(中には4コアの64bit Armプロセッサが搭載される)、さらにIPU Gatewayに外付けでDDR4 DIMMが装着される格好だ。
-

Photo07:このDDR4はIPU-Gateway自身が利用するメモリ+M2000全体用のLocal Cacheとしても利用できるそうだ

さて同社ではこのIPU-M2000を4枚+Dellの1Uサーバー組み合わせた「IPU-POD 16」と、それを4組組み合わせた「IPU-POD 64」、さらに「IPU-POD 128/IPU-POD 256」などをラインナップしている(Photo08)。
-

Photo08:IPU-POD 16ではIPU-M2000が表向きに装着されているが、IPU-POD 64では裏向きになっている

もうこれは単純にスケーラビリティの問題であって、数字はMK2チップの数である。性能という意味では、RESNET-50(Photo09)/BERT(Photo10)/EfficientNet-B4(Photo11)のTraininguの性能をNVIDIAのDGX A100と比較した結果が2021年6月に示されており、絶対性能はともかく導入時の価格性能比や消費電力/性能比ではDGX A100を上回る、というのが同社の主張だ。
-

Photo09:絶対性能そのものではA100の方が上だが、価格が倍という点がネックになる

-

Photo10:こちらも同様。また消費電力もNVIDIAの方が高くなるとしている

-

Photo11:ものによっては絶対性能もIPU-POD 16の方が上だったりする

3D化により性能を3割向上
さて、ここまでは長い前置きで、ここからが本題。今回発表されたのは第3世代のIPUである(名称はBOW IPU)。スペックはこちら(Photo12)であるが、IPU-Coreが全部で1472、メモリも900MBというのは、スペック的にMK2とまったく違いがない。内部構造もMK2と比較した場合に“Exact same”だそうだ。
-

Photo12:実際ダイサイズもMK2と同じ823平方mmで、トランジスタ数も594億個のままである

違うのは動作周波数で、こちらは1.85GHzまで引き上げることが出来たそうだ。しかも世界初の3D Silicon Wafer Stackedだという。この結果、平均して3割程度の性能向上が見込めた、としている(Photo13)。
-

Photo13:動作周波数比で言えば1.85GHz:1.35GHz≒1.37:1だから、まぁ動作周波数の伸びがそのまま性能に反映されている格好

問題は、「なぜ3D化したのか?」という話になる。普通に考えればSRAMを積層するなり、eDRAMを積層するなりする格好になるのだが、メモリ容量はチップあたり900MBだから、要するに何も変わっていない。この疑問は、質疑応答でやっと明らかになった。この第3世代はBOW IPUと呼ばれるのだが、このBOW IPUはTSMCのSoIC-WoW(Systems on Integrated Chips - Wafer on Wafer)を利用して製造される(Photo14)。
-

Photo14:恐ろしいというか凄まじいというか、いや説明を聞くまで考え付かなかった

この図で下側のダイは従来のMK2そのままである。つまり一切変更がない7nmプロセスで製造されたMK2がそのまま利用される。これにSoIC-WoWを利用して積層されるウェハは、信号線をC4 Bumpに接続するためのBTSV(Back-side Thought Silicon VIA)と、あとはDTC(Deep Trench Capacitor)から構成される。DTCがあることから「ひょっとしてDRAM?」と思ったら、なんとこれは電源向けのキャパシタである。つまりSoIC-WoWを使って、シリコン全面に配される形でパスコンを構成した事だ。これによりPower Deliveryが改善されたことで、動作周波数を高める事が出来た、という恐ろしい実装であった。
冷静に考えれば、この場合キャパシタ側のウェハの製造プロセスは、7nmどころか40nmとか55nmあたりでもお釣りがくるレベルで、WoWの位置合わせと重ね合わせに余分なコストは掛かるものの、ウェハコスト自体はそれほど高くない。しかもBTSVのおかげで放熱効率は悪くないし、このキャパシタ側ウェハのおかげでチップ全体の熱容量が増えるため、急速に発熱が増える事が抑えられる。しかも、ほぼダイサイズと同じ容積を持つパスコンを、電源ラインの非常に近いところに設けているわけであり、Power Deliveryも改善するのは当然ある。ちょっと目から鱗、の利用方法であった。
同社はこのBOW-IPUを、MK2とまったく同じ価格で出荷するとしている。つまりコストを変えずに性能を3割増にしたわけだ。また、ロジックそのものはMK2とまったく同じなので、プログラムの変更は一切必要ない。ラインナップとしては最小構成は16チップの「BOW POD 16」だが、最大構成は1024チップの「BOW POD 1024」まで用意されることになった(Photo15)。
-

Photo15:1ラックで最大64コアである。もっと集積できそうな気もするが、ラック当たりの供給電力がこのあたりでLimitなのではないかと思う

この結果として、例えばEfficientNet-B4のTrainingでは性能比5倍、TCPでは10倍になったとされている(Photo16)。このBOW IPUは本日より出荷開始との事である。
-

Photo16:先のPhoto11と比較すると差が判りやすい

ちなみに発表ではさらにその先の話として、The 'Good' Computerの話も出て来た。これはまだ将来の話であるが、2024年の完成を目指すシステムである(Photo17)。
-

Photo17:'Good' computerは、「“善き”コンピュータ」ではなく「Good博士のコンピュータ」の意味である。ちなみにGood博士は2009年4月に91歳で亡くなられた

元々は1965年にIrving John Good博士が出した“Speculations Concerning the First Ultraintelligent Machine”という論文に出て来た、人間の脳と同等以上の性能を持つコンピュータシステムが元になっている。
ちなみにGood博士は1968年、キューブリック監督が2001年宇宙の旅を撮影するにあたってのアドバイザーに就任しており、要するにHAL9000がその1つの理想形として考えられる。HAL9000はあくまで映画の中の架空の存在であるが、それに近いものを構築しよう、という試みである。
この'Good' Computerは同社の次世代IPUをベースとしており、8192チップで4PBのメモリを搭載、500兆個のパラメータをもつネットワークを実行する事が出来、想定コストは1億2000万ドルだとされる。
一応説明では“Graphcore will deliver by 2024 the world's first ultra-intelligence AI computer that we are calling the Good computer”とあるので、このシステムを実際に構築するつもりはあるようだが、詳細や提携パートナーなどはまだ時期尚早ということで説明されていない。とは言え、ついにHAL9000が現実のものになるという、そういう時代が来たわけだ。