MLCommonsはAI Training/Inferenceの性能を比較するMLPerf v1.1の結果を9月22日に公開した。MLPerfは当然主要なAI Processorベンダーが実施しており、その結果はオンラインで参照可能であるが、Cloud AI A100の結果についてQualcomm自身から説明があったので、その内容をご紹介したい。
そもそもCloud AI 100そのものは2018年頃から名前だけがちらちら出てきており、2019年9月に製品発表が行われたものの、この時点ではまだ開発キットがリリースされたという状況であった。
またアーキテクチャの詳細などについて説明はなく、Dual M.2e/Dual M.2/PCIeという3種類のフォームファクタが用意され(Photo01)、競合製品と比較しても十分に性能/消費電力比が高い(Photo02,03)とされた。
-
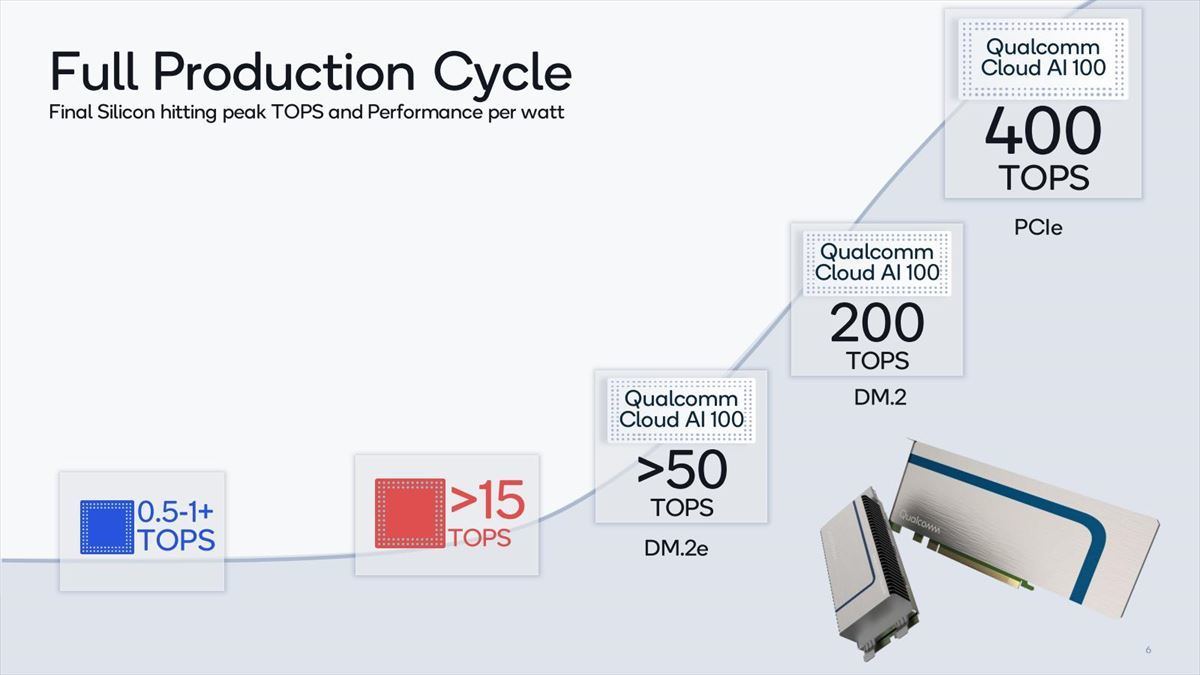
Photo01:Dual M.2eが15W、Dual M.2が25W、PCIeが75WのTDPとされた。コア数は最大16で、On Die SRAMがコアあたり9MB、カード上に最大32GBのLPDDR4xメモリを搭載、データタイプはINT8/INT16/FP16/FP32に対応とされた

-
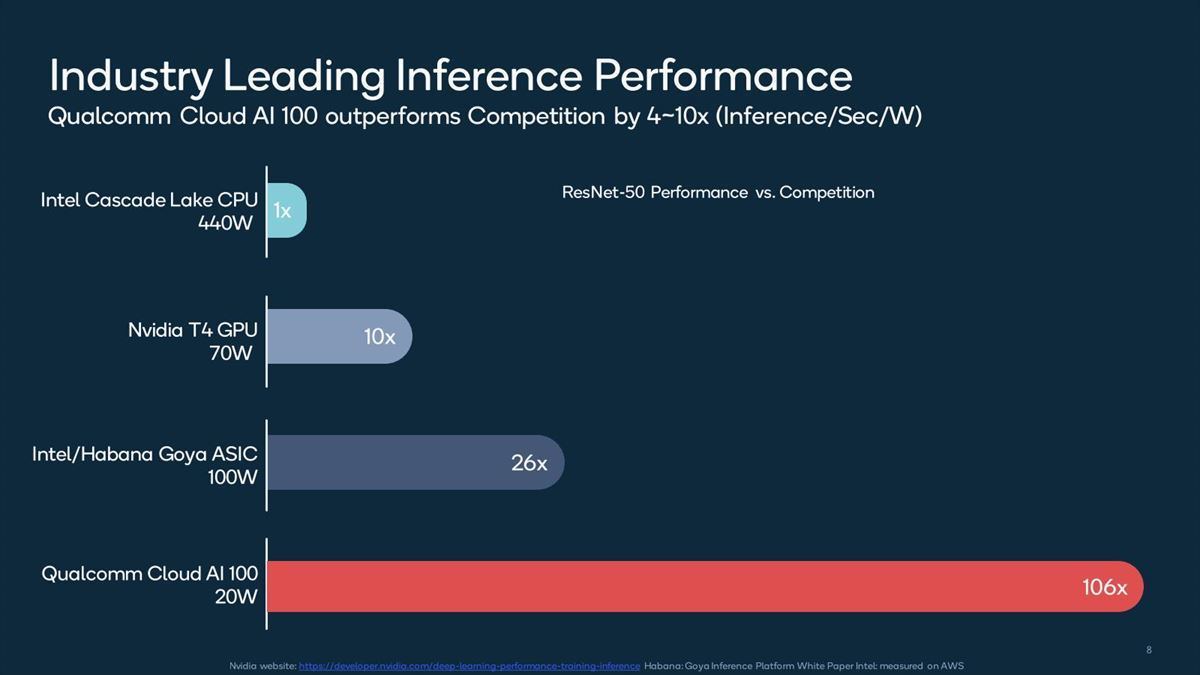
Photo02:ここにCascade Lakeが出てくるあたりが2019年の資料である

-
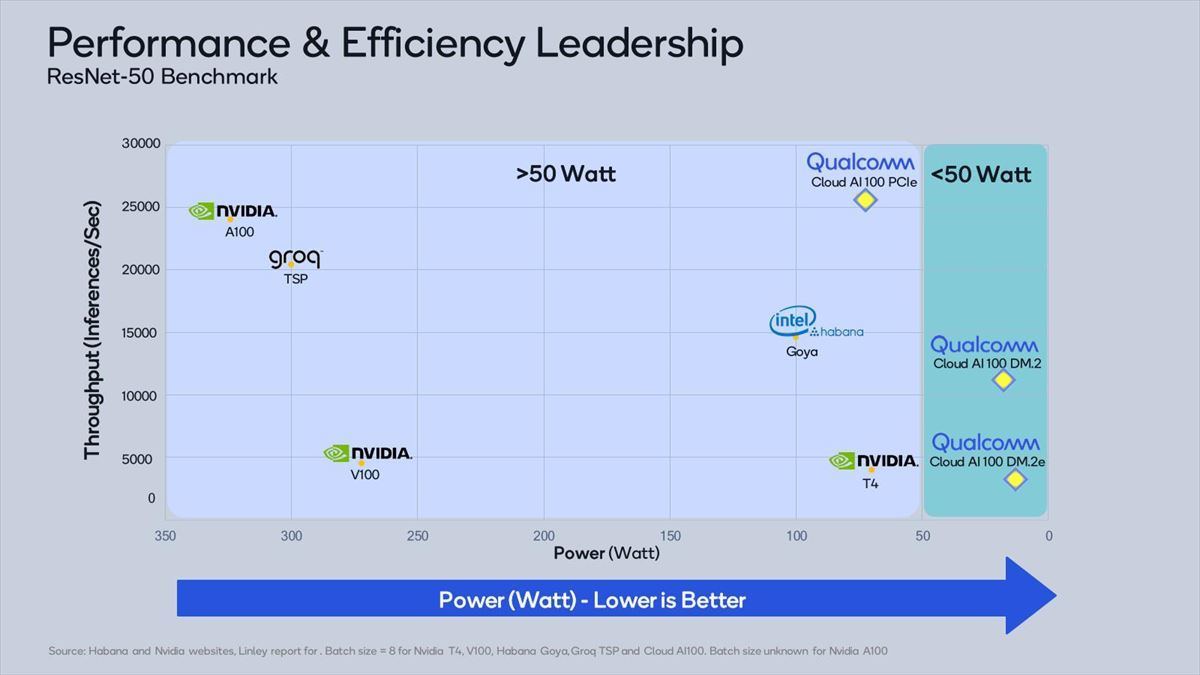
Photo03:ResNet-50でのInference性能(Image/sec)を縦軸、横軸を消費電力としているが、その横軸は逆順になっている事に注意

またカードタイプのソリューション以外に、Edge IoT向け開発キット(Photo04)も用意されるとした。ちなみにこの時点での情報では、Cloud AI 100チップそのものはサンプル出荷を開始しており、量産開始は2021年前半。また開発キットは2020年10月に出荷開始とされていた。
-
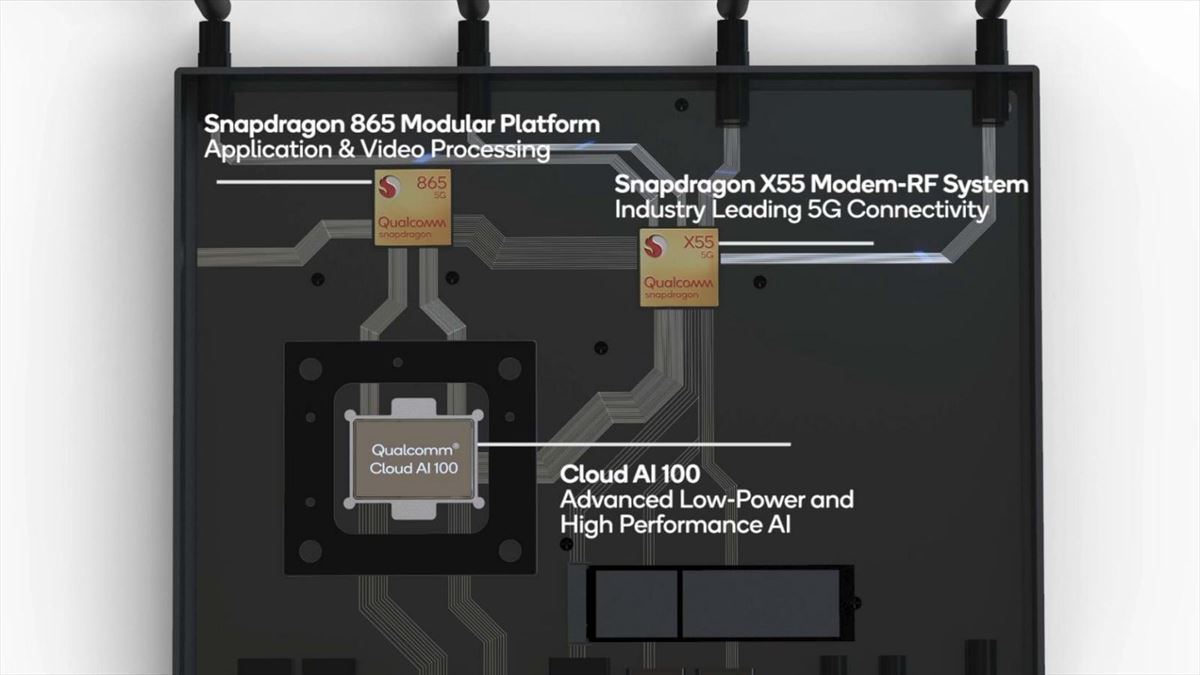
Photo04:アプリケーションプロセッサとしてSnapdragon 865と5Gモデムを搭載。ロードサイドにおける監視カメラの制御などにも使える屋外向けシャーシに搭載されており、デモでは24台のHD Videoを25fpsのフレームレートで取り込みながらObject Detectionを行う例が示された

次の情報は2021年4月に開催されたLinley Spring Processor Forum 2021ででてきた。相変わらず内部構造の詳細などは語られないままであったが、単にEdgeのみならずServer向けでも利用できる(Photo05)ことや、同社の提供するソフトウェアフレームワーク(Photo06)が紹介された。
-

Photo05:なにしろ1slot厚でTDP75Wなので、薄型サーバであっても最大16枚を実装できる、という訳だ

-
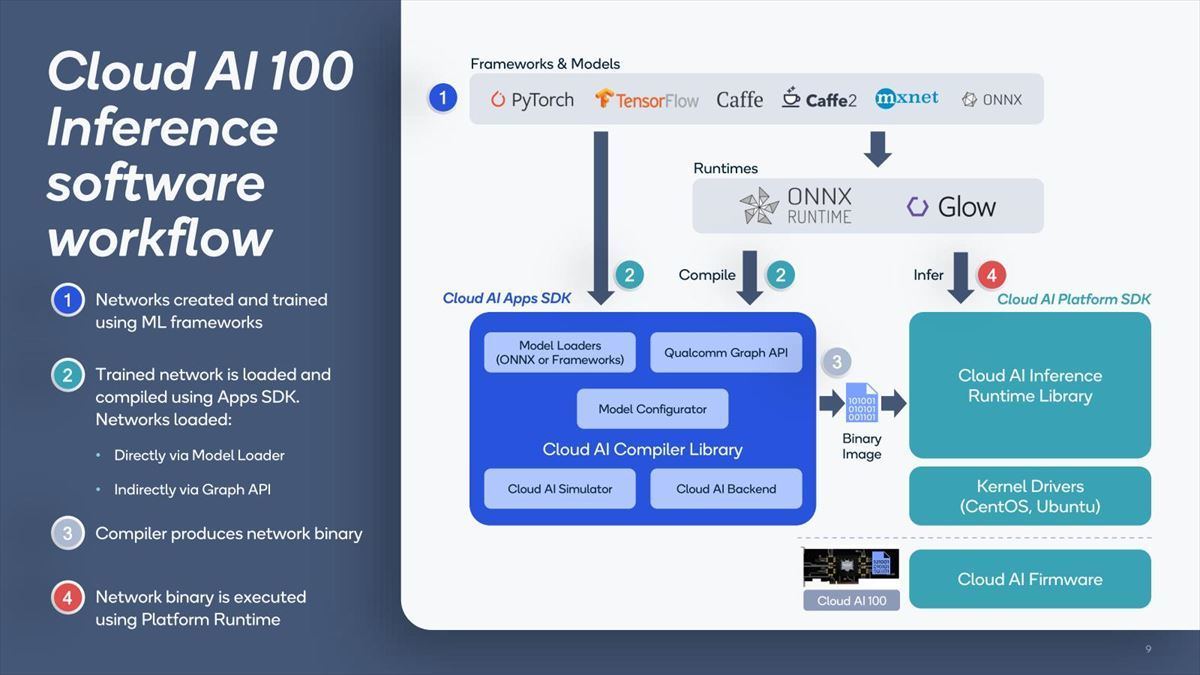
Photo06:ONNXやGlowから直接駆動する事も出来るが、基本は既存のフレームワークを同社のCloud AI Apps SDK経由でBinaryに変換してロードする形になる

次は2021年8月のHotChips 33である。多分HotChips 33におけるCloud AI 100の詳細はいずれ安藤先生が説明して下さると思うので要点だけまとめると、全体の構造(Photo07)やAI Coreの構造(Photo08)に加え、実際のチップによる性能や消費電力(Photo09)、いくつかのベンチマークの結果(Photo10)やその分析(Photo11,12)が示されている。
-
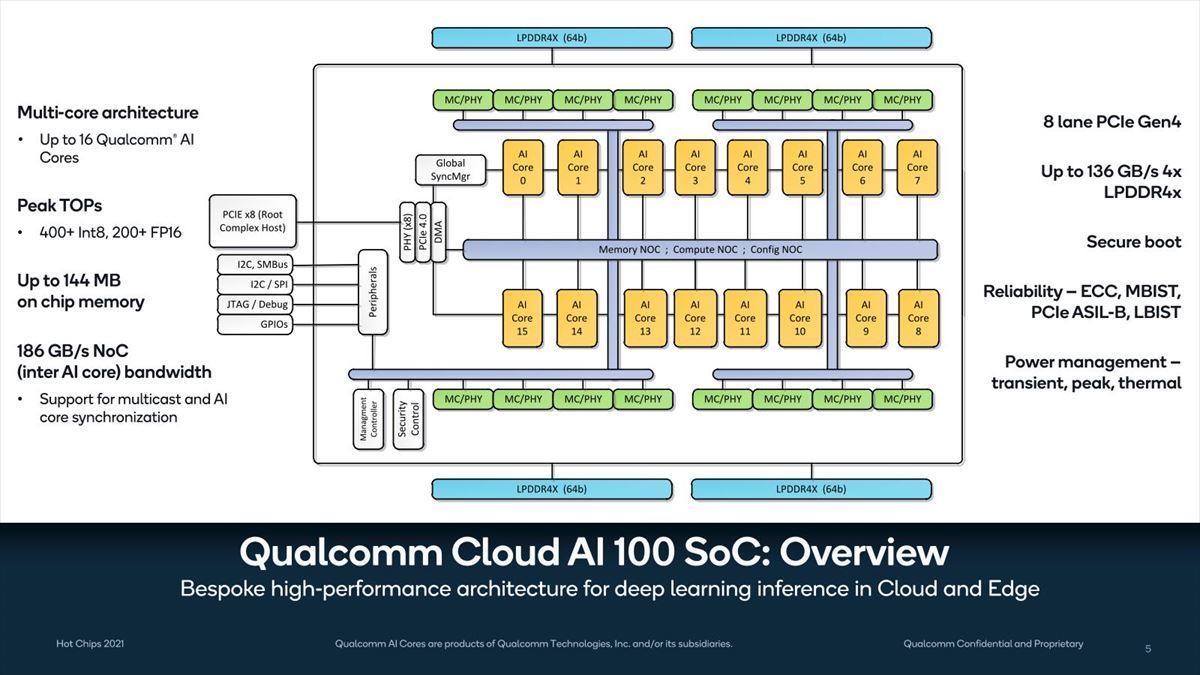
Photo07:16個のAI CoreがNoCでつながる構造。意外にシンプルというか、あまりひねりの無い構造である。Global Sync Managerからの信号がMeshになっているのは、各々のAI Coreがリピータで経由してゆくというよりも、Clock Mesh的にすべてのAI CoreにBroadcastされる形なのかもしれない

-
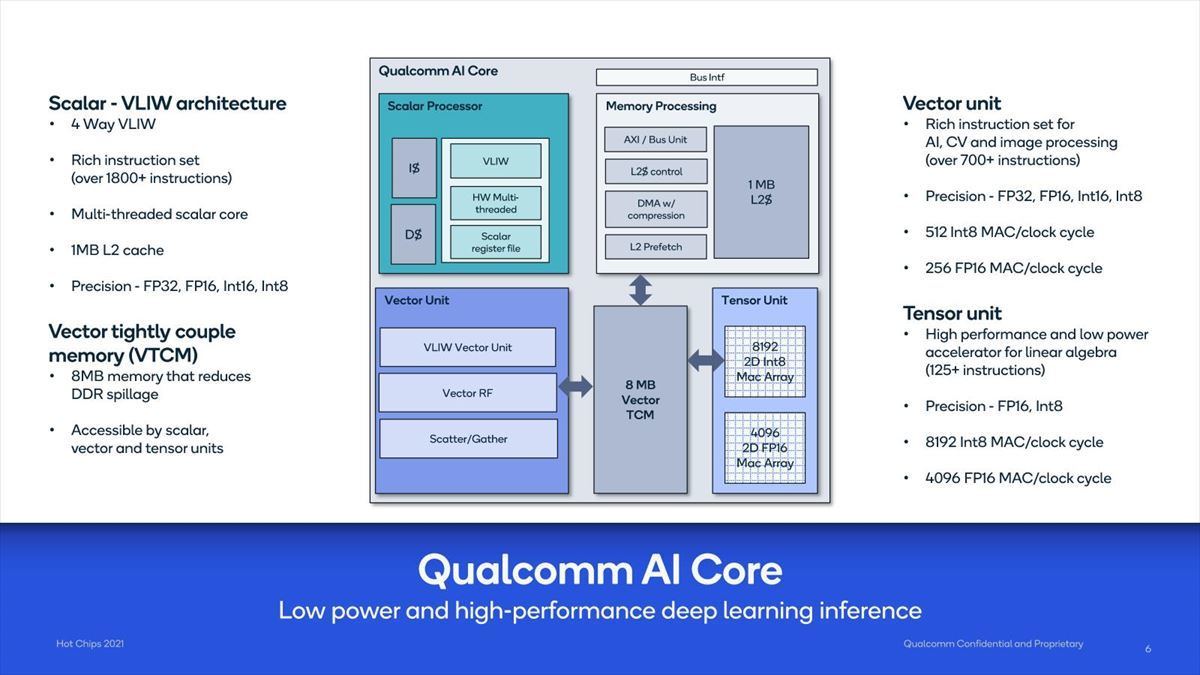
Photo08:ScalarとVectorの2種類のUnitに加え、Memory Access専用のプロセッサが付くのが面白い。またVector UnitへのメモリはRegister FileではなくTCMというのも特徴的。9MBというのは、TCMが8MB+Memory ProcessorのL2が1MBという構成である

-

Photo09:12.05WというのはDual M.2eモジュール向けのものと思われる。ついに実際のシリコンで12TOPs/Wを実現した訳で、これはちょっとしたBreakthroughである

-
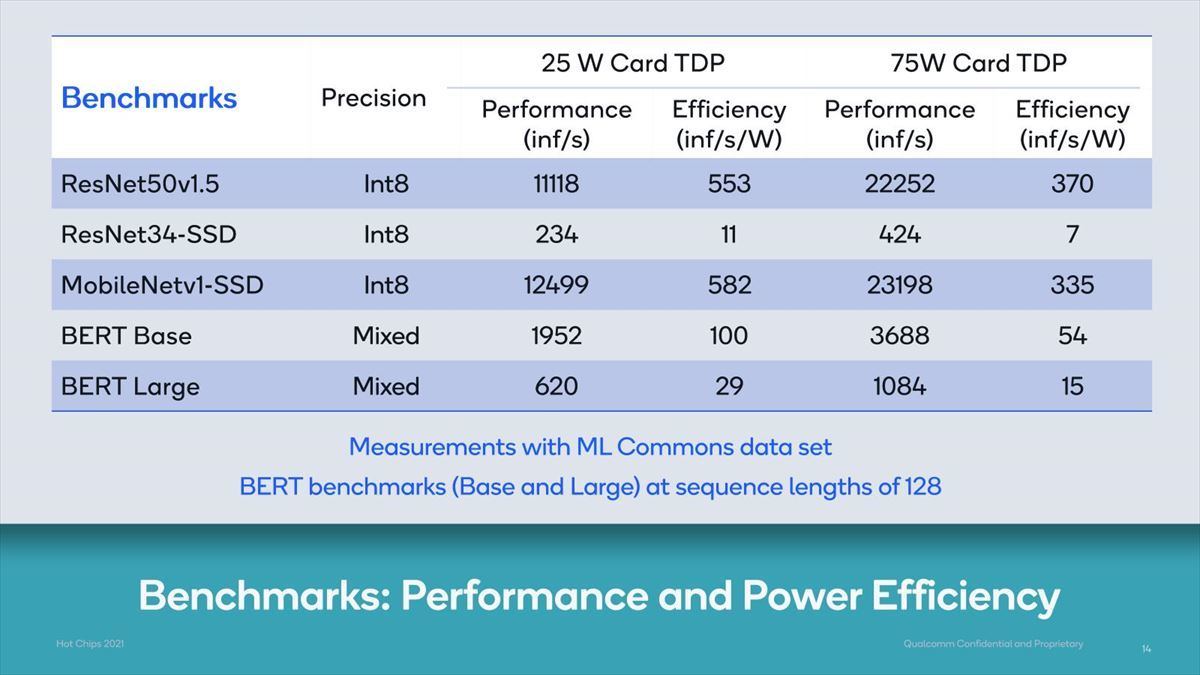
Photo10:テスト項目そのものはMLPerf v1.0のものを利用しているが、この結果はMLCommonsにsubmitしていないためか、正式な結果ではない。あくまで参考値扱いである

-
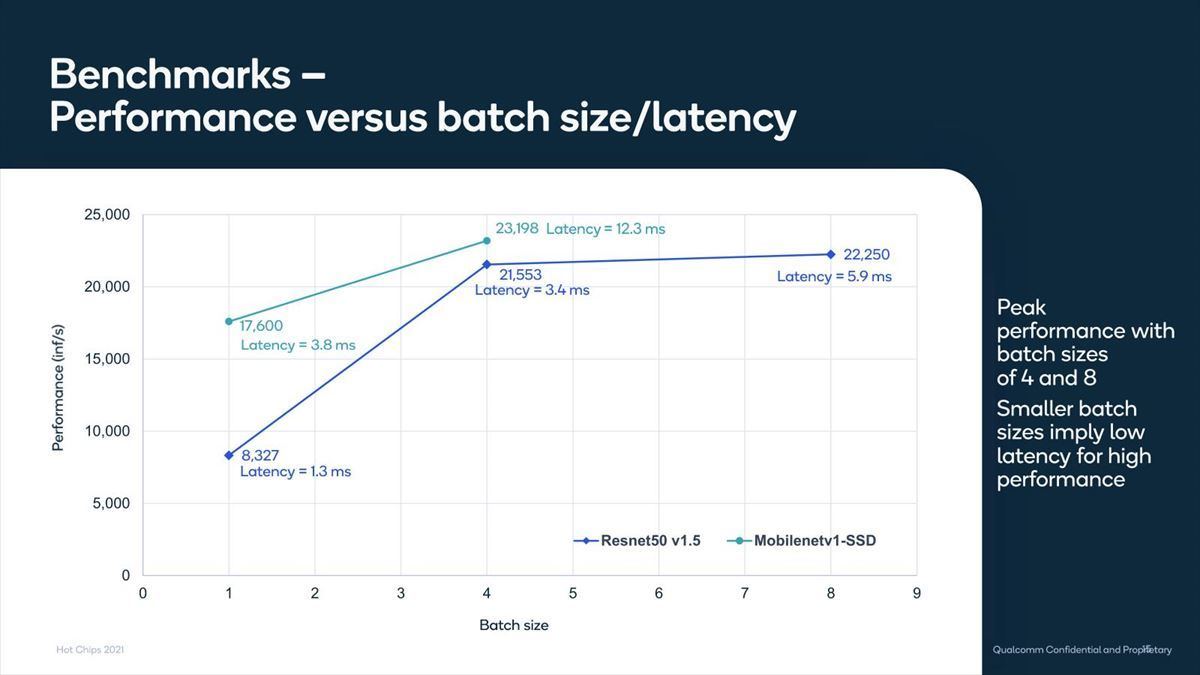
Photo11:Batch Sizeと性能の関係。Batch Size=4あたりが一番性能が出しやすいようだ

-
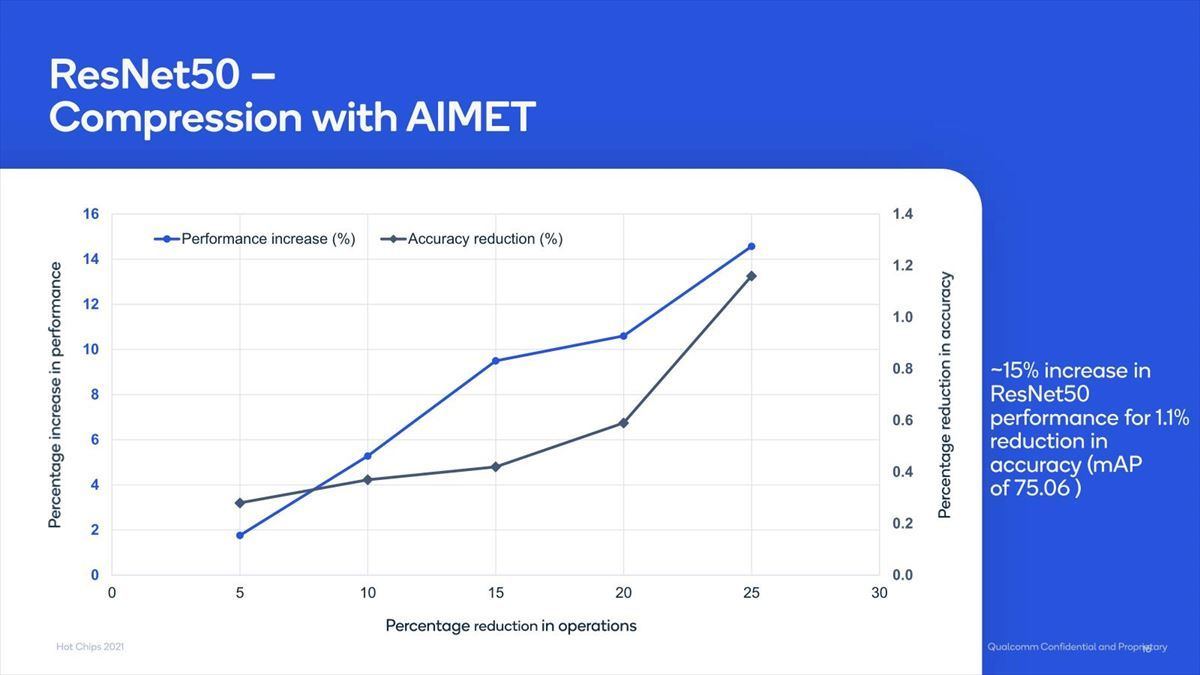
Photo12:Qualcommの提供するAIMET(AI model Efficiency Toolkit)を利用した場合の性能向上率。ResNet50の場合、最大15%近い性能向上率が期待できる(その分精度がやや落ちるが)

ということで今回の発表である。MLPerfそのものの説明はこちらにあるので御覧いただくのが早い。ただこちらの説明では、Training 1.1が先にSubmissionされ、そのあとInference 1.1がSubmissionされるはずだったのだが、MLPerf v1.1のInferenceはこちらでソースが公開されているのにTrainingはまだのようで、公開もInferenceが先になったようだ。
さてその結果であるが、Qualcommは今回82のベンチマーク結果をSubmitしており、うち36では消費電力も含めた結果をSubmitしているとする(Photo13)。またMLPerf 1.0に関しても、公開はされていないのだがSubmitはしていたようで、その結果としてMLPerf 1.0 auditにおいて“interesting submission”で2位を獲得した、としている。
-

Photo13:ちなみに今回の結果はInferenceであるが、同社のソリューションは単にEdgeだけでなくServerもカバーするし、対象も単に画像認識とかだけでなくNLP(Natural Language Processing)まで視野に入れている、と説明があった

さて、肝心のInferenceの結果である。これ(Photo14)はResNet-50の結果であるが、「消費電力当たりのInference性能」で、Cloud AI 100がNVIDIAのA100を圧倒している、としている。
-
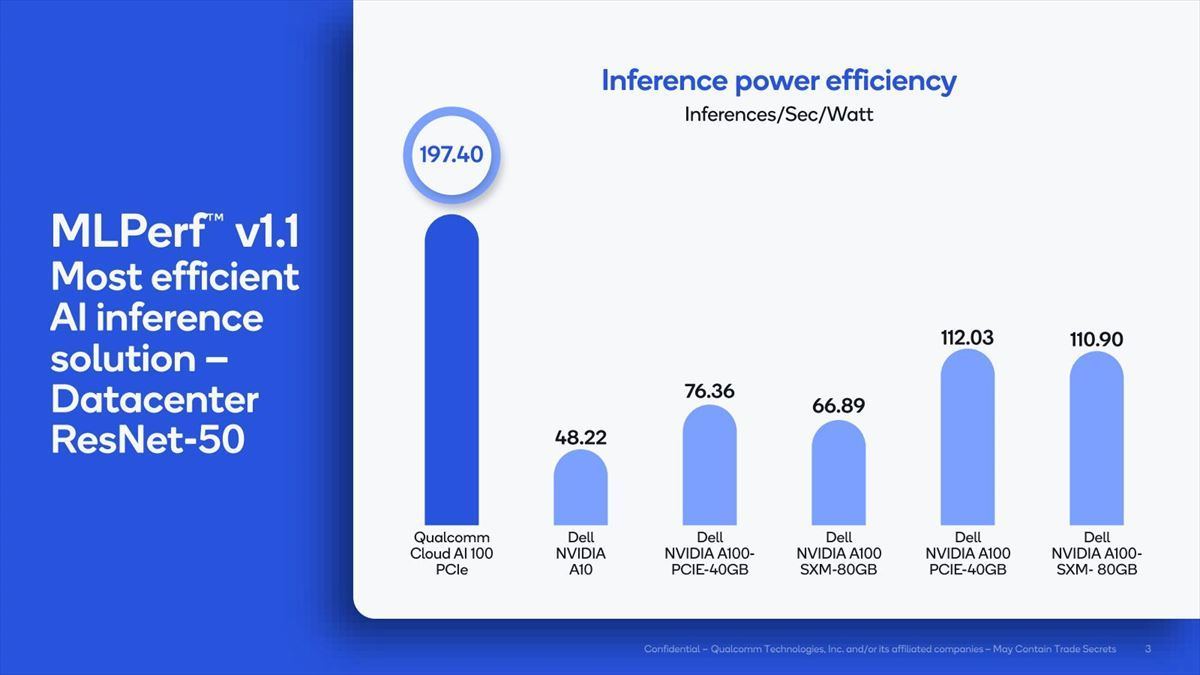
Photo14:曰く「NVIDIA A100は消費電力が1枚300Wだから16枚で4.8KWになる。Cloud AI 100は75Wだから16枚でも1.2KWでしかない」そうで。逆に言えば、消費電力を無視した結果を比較するなら、NVIDIAの結果をラフに4倍にすれば良い事になる

これはEdge Device/Edge Serverの両方で実現できる、というのが同社の説明である(Photo15)。
-
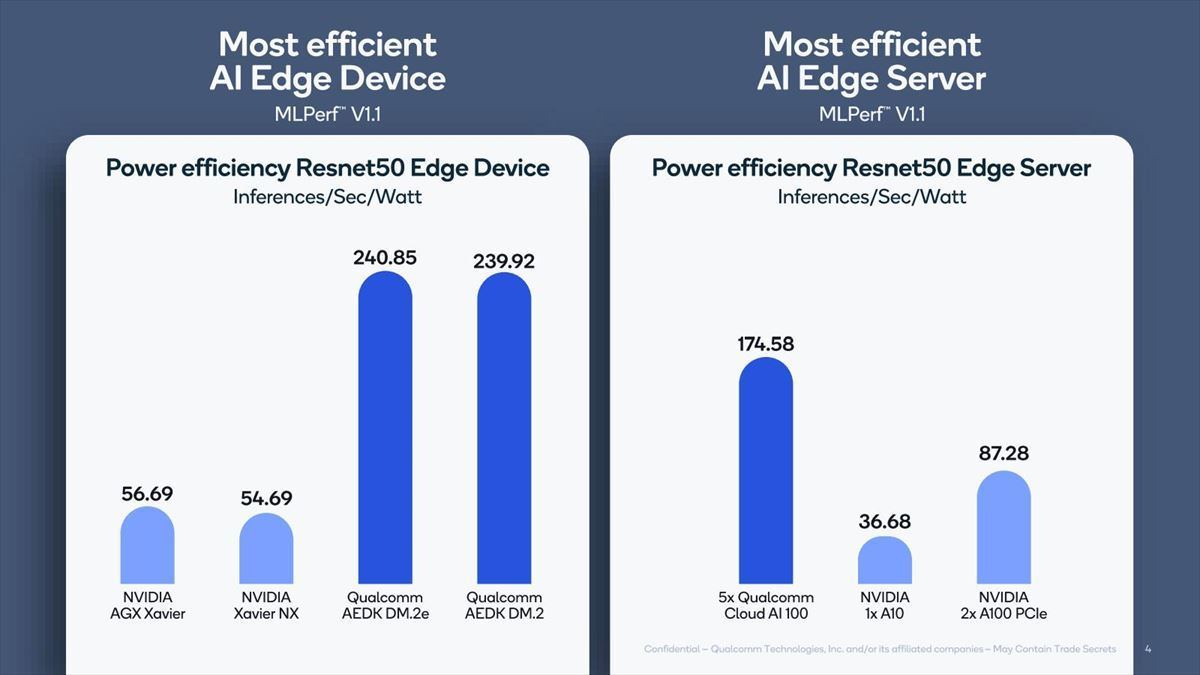
Photo15:消費電力効率そのものはDouble M.2eの方がわずかながら良いのが面白い。Edge Serverの方は、カードの数がちょっと面白い

もう少し詳細な数字はこちら(Photo16)。
-

Photo16:さすがにBERT-99 LargeはEdge Device向けは無理なので、これは省かれている。Edge Server向けはPCIeカード5枚がデフォルト構成らしい。Dual M.2eはMLPerf 1.0から1.1で性能効率が34%改善したとされているが、「どうやって」改善したかは不明

このままだと比較対象が無いのでどの程度すごいのかが判り難いが、この記事が公開される頃にはMLPerf 1.1の結果が公開されているはずなので、それを見ていただくのが良いだろう。
こちらの数字はDataCenter向けのResNet-50のOfflineにおける性能比較で、ピーク性能そのものもいい勝負になるとしており(Photo17)、またCloud AI 100は枚数に応じて比較的スケーラブルに性能が伸びる、としている(Photo18)。
-
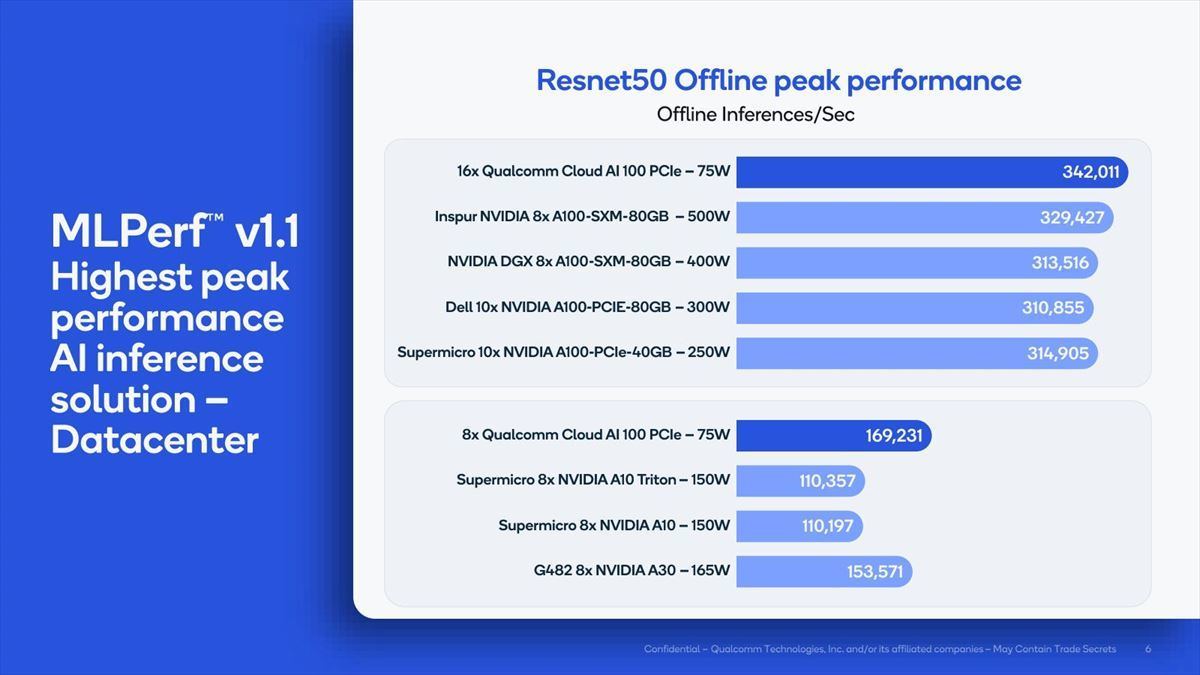
Photo17:カードの枚数を同じに揃えたらCloud AI 100の性能はもっと下がることになるが、逆に消費電力を同等にしたら利用できる枚数が大幅に増える事になる訳で、このあたりどの辺で比較するのかは難しい

-
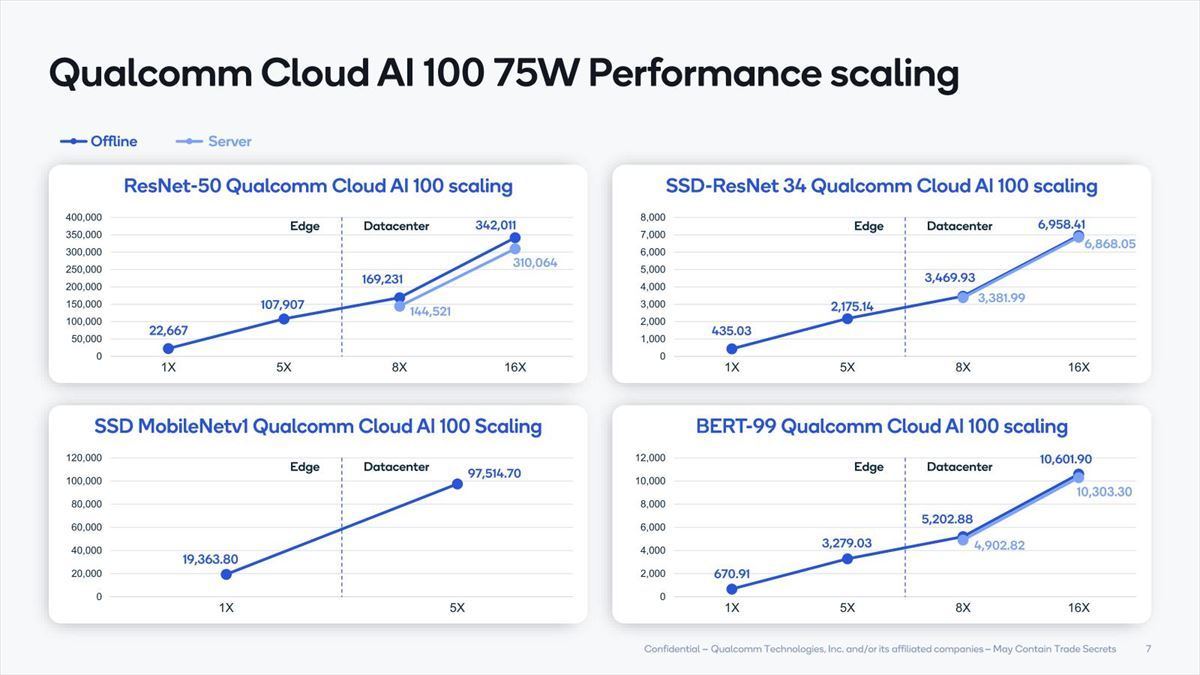
Photo18:16枚を超えてもスケールするか、は謎。もっともそれを接続できるプラットフォームが存在しないが

Photo19はDatacenter向けの結果をまとめたものだが、性能もさることながら2KW未満(カード8枚なら1KW未満)の電力で稼働する点を強調しているのが判る。
-

Photo19:ただBERT-99/99.9に関しては、効率はともかく性能の方はやっぱり厳しい模様

競合製品との比較をまとめたのがこちら(Photo20)で、絶対性能としても競合製品を上回るとしている。
-
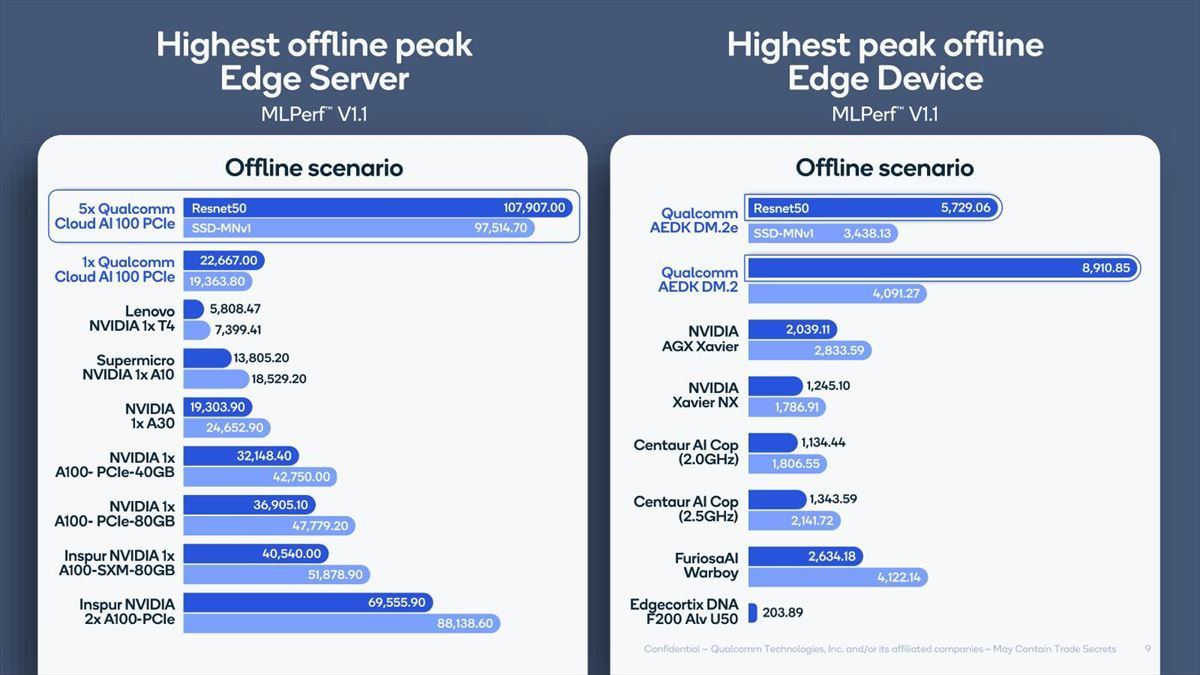
Photo20:Edge Serverの方はCloud AI 100カード×5なのはご愛敬。ところでQualcomm以外の結果はどうやって取得したのかは不明。ひょっとしてQualcomm自身がこれらのシステムを稼働させてデータを取ったのかもしれない

一方、性能/Latencyの比較を行ったのがこちら(Photo21)。
-
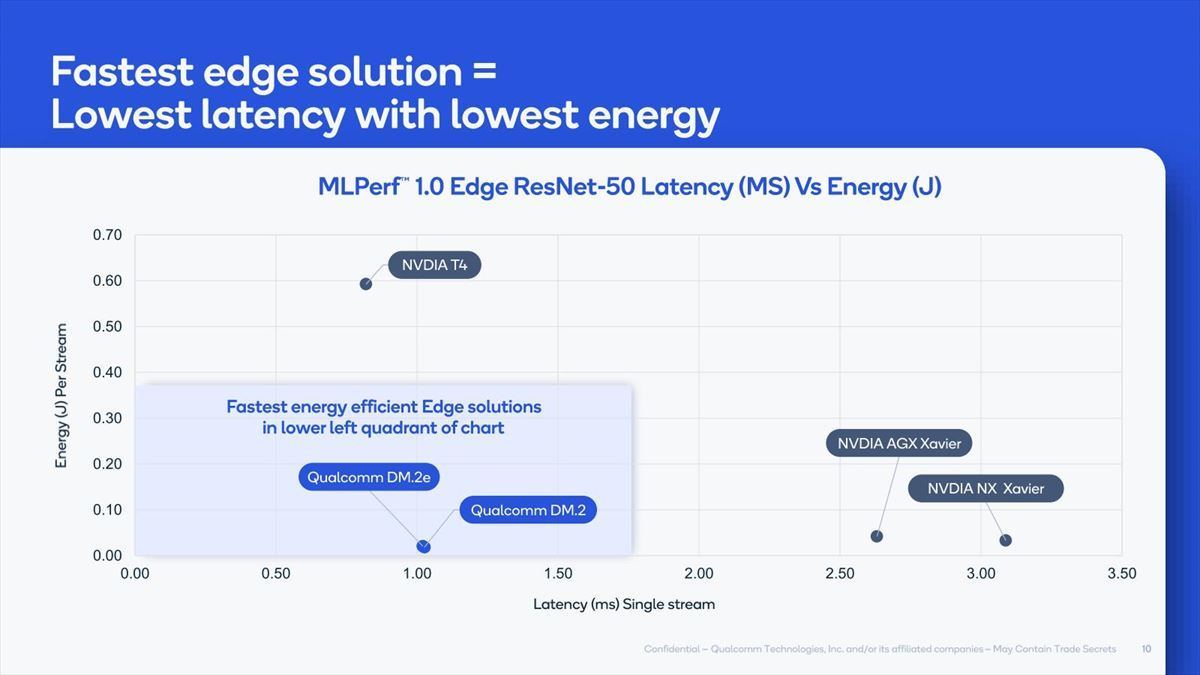
Photo21:LatencyそのものはNVIDIA T4にはやや劣るが、Xavierに比べるとずっと少なく、しかも消費電力が低いとしている

Edge向けではLatencyが結構大きな問題になることが多く、また消費電力も厳しい訳で、競合というかNVIDIAの製品に比べてずっと優れているとしている。一方Server Workload向けのBERT 99の場合の結果を比較したのがこちら(Photo22)。
-

Photo22:絶対性能ではNVIDIA Aシリーズと競合は難しい(5枚のCloud AI 100が1枚のA100-PCIe 80Gと大差なし)という事もあって性能効率での比較に持ち込みたいのだが、こちらもアドバンテージがあるとは言いにくい

絶対性能そのものではやはりBERT99に代表されるNLPはちょっと厳しい様で、それもあってNVIDIA A100に比べてアドバンテージがあるとはちょっと言いにくい結果ではあるが、大きく劣っているとも言えない、割と拮抗するレベルの性能/消費電力比だけに、あとは導入の価格次第では勝負もできるのかもしれない。
ちなみに当然Qualcomm以外のメーカーもMLPerf 1.1の結果をSubmitしているわけで、この記事の公開時にはそうした結果も出てくる事になるだろう。NVIDIAも例えばフレームワークを改良するなどして、今回Qualcommが示した数字よりも良い結果が出てくるかもしれない。そのあたりはまた改めて比較してみる事になるだろう(しかも敵はNVIDIAだけではない訳で、なかなか楽しい事になりそうだ)。