情報の流れを処理するメモリファブリック
そして、メモリファブリックは各種のスライスやL3キャッシュ、Ramboキャッシュなどを接続するコヒーレントなインタコネクトである。さらに、メモリファブリックにはPCI Express、ディスプレーポート、メモリコントローラなどが接続される。そして、メモリコントローラからはDDR4やGDDR6、HBM2などのメモリが接続できる。
また、Xeリンクを通して他のXeチップに接続して複数タイルのXeシステムにすることもできる。
-
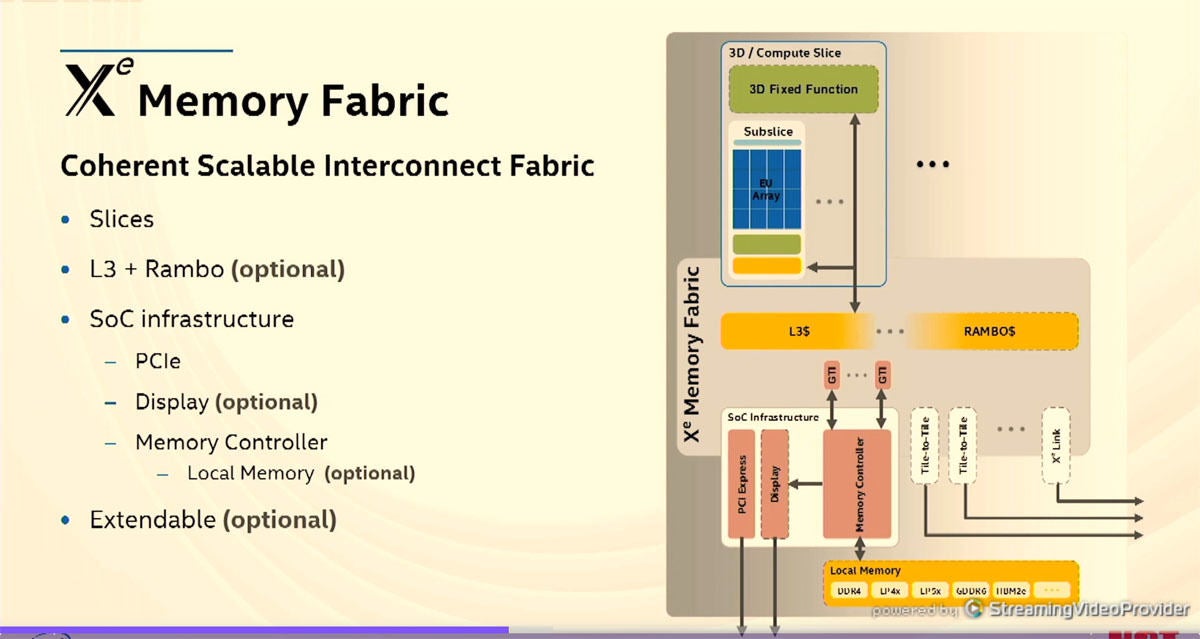
メモリファブリックは内部にL3キャッシュや大容量のRAMBOキャッシュを持ち、各種のスライスと外部メモリやPCI Expressとの間をコヒーレントに接続する

次の図は4個のXeタイルをEMIBブリッジ(図中の白い部分)で接続してマルチタイルのXeを作った例である。このような同一パッケージ内の複数タイルの結合は、パッケージングを行う時のオプションとして実行することができる。
-

4つのタイルを1つのパッケージに搭載し、EMIBで接続して4タイルのGPUを作っている例。接続するかどうかはパッケージする時に決めても良い

XeLPは1スライスだけの低電力システムで、CPU内蔵型のGPUとして使われる場合も、CPUとは別チップのディスクリートGPUとして使われる場合もある。XeHPGはディスクリートのゲーミング用GPUなどをターゲットにしており、GDDR6メモリを使いレイトレーシングを実行するような使い方ができる。
XeHPはマシンラーニングやメディアワークステーションのような使い方を想定しており、HBM2eメモリの使用や同一パッケージに1-4タイルを接続するような使い方を想定している。
XeHPCはスパコン用で、高バンド幅のHBM2eメモリを使い、Xeリンクで複数タイルを接続する。そして、パッケージ内ではFoverosやEMIBを使って複数タイルを接続する。これに加えて小規模のシステムでは1-2タイルをパッケージに入れるという形態もあり得る。
Tiger Lake CPUの内蔵GPUとしての使用が先行
現状では、Tiger Lake CPUに搭載されるXeLPが製造中というステージにあり、一番、商品化に近い。その次がエクサスケールのAuroraスパコンに使用されるXeHPCのPonte Vecchio GPUで、これは製造中のステージにある。XeHPとXeHPGはまだ、設計部門の手を離れていない状態である。
次の図はXeLP GPUを内蔵したTiger Lake CPUのチップ写真である。GPUの面積はチップ全体の1/3程度であり、比較的小さいという印象である。これで前世代のGen 11 GPUと比べて、同一面積、同一電力で比較して、3DやComputeの性能は約2倍に向上しているという。
-

XeLP GPUは、Tiger Lake SoCのチップ面積の1/3程度で比較的小さい印象である。しかし、3D/Computeの性能は、同一面積、同一電力で比較すると前世代GPUの2倍程度の性能になっている

そして、XeLP GPUは最大96個のEUを搭載しており、これは前世代の1.5倍にあたる。また、最大48テクセル/クロック、24ピクセル/クロックのピクセル処理が可能になっており、前世代に比べて1.5倍の大きさのエンジンになっている。
-

Tiger Lakeに搭載されたXeLP GPUは、前世代の内蔵GPUの1.5倍の性能のグラフィックスエンジンになっている