PCIe Gen6の高速化手法
さて、Press Conferenceそのものはこれで終わりなのだが、Press Conferenceの翌日である6月4日に、PCI-SIGが主催する「PCIe 6.0 Specification: The Interconnect for I/O Needs of the Future」というオンラインセミナーが開催され、ここでPCI Express Gen6の詳細が説明されたので、この内容をご紹介したい。
まずPCI Express Gen6の動機であるが、これは説明するまでもない(Photo06)。
-

Photo06:加えて言えば、CCIXとかCXLみたいに、PCIeを前提としたInterconnectがすでに存在し、これらの今後の高速化を考えると、既存のPCIeの枠組みを外さずに高速化する方法が必要、という事もある

問題はこれをどうやって低コストで実現するかである。このためのGen6の設計目標はこんな感じ(Photo07)である。
-

Photo07:Reliabilityで1FIT未満、という話が何時から入ったのか筆者は確認できない(以前は無かったと思うのだが)。今までReliabilityで言えばBERの議論だけだった気がする

100G Ethernet向けのFECの利用をのっけから断念してるあたりが中々興味深い。このFECの話は後でするとして、まず倍速にする方法だが、これまでのBinary SignalingをPAM-4変調に切り替えたのが最大の違いである。これにより1回の転送で2bit分がまとめて送れるようになるので、転送速度そのものはGen5と同じ32GT/secであっても、実効転送速度は倍の64Gbit/secになるという仕組みだ(Photo08)。
-

Photo08:もちろんこのEYEはFECとかイコライザを経由して補正した結果のものだから、その補正が重要という話ではあるのだが

ただPAM-4を使うと、当然ながらエラーが増える。Ethernetではこれをカバーすべく強力なFEC(Forward Error Collection)を組み合わせているのだが、PCIeでは後述の理由でFECは軽めのものになっている。それよりも、実際にPAM-4を利用するとFBER(First bit error rate)を抑える事が出来れば、比較的エラーの影響は少ないというのがPAM-4における分析結果だとする。
-

Photo09:Burst Errorの場合、特定のレーンにそれが集中するので、これを抑えられればBERを結果的に減らせることに繋がるそうだ

ではどうするか? といえば。FECはもちろん実装はするが、これはあまり強力ではない(ただしLatencyが少ない)方式を使い、これで漏らしたエラーはLink LayerのCRCで検出して対応することで、FITを1未満に抑えられる、という方式である(Photo10)。
-

Photo10:FECのLatencyの目標は2nsだそうで、そりゃ100nsオーダーのEthernet向けFECは使えない訳である

実際の評価では、FECはそこそこの強度にしてCRCによるエラー検出でリトライを噛ました方が、強力なFECを使うより良好な結果になるとしている(Photo11)。
-
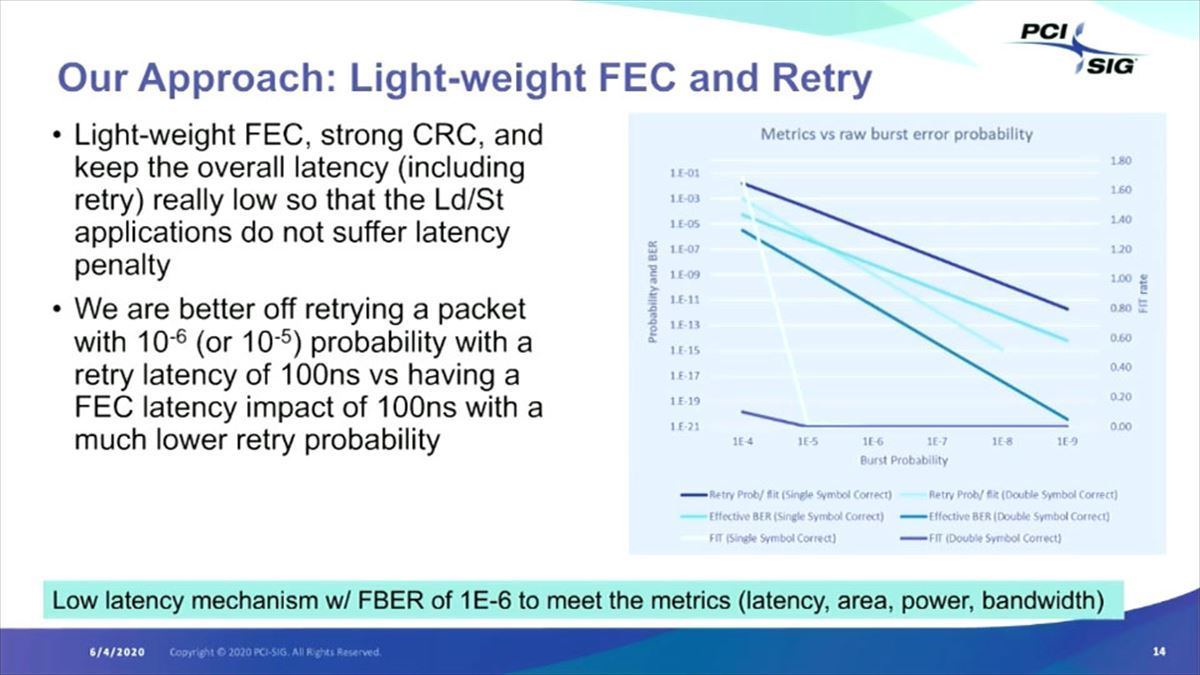
Photo11:一度リトライが入ると100nsオーダーのLatencyになるが、その頻度が10-5~106であれば、常時100nsのLatencyが入る強力なFECよりマシ、という判断である

さて、この組み合わせの場合はRetryの際のLatencyをどれだけ抑えられるかという話になる訳だが、ここで新しく導入されたのがFLITである(Photo12)。
-

Photo12:FLITは256Bytesの固定サイズパケットで、うち236Bytesがデータ、残りがヘッダとCRCである。固定サイズなので、x1レーンだと1個のFLITを転送するのに32ns、x16レーンだと2nsで完了することになる。なのでレーン数が大きければ再送のLatencyは極めて少ない事になる

先ほどもちょっと出てきたが、従来のRetryはTLPレベルでのパケット再送になる。これに対してFLITはPHYレイヤでの再送が可能な仕組みである。基本的な仕組みは、上位から渡されたデータを256Bytes単位のFLITパケットに分解して、このFLITパケット単位での再送制御を行う形になる。その再送制御の様子がこちら(Photo13)である。
-

Photo13:FLIT 11はNOP TLPなので再送しない。逆にFLIT 20は、これでFLITの再送完了の通知のためにNOP TLPを送る形となる

1つのTLPパケットは複数のFLITに分解されて送られることになるが、ここでFLIT 11/13/18/19/20に誤りが検出された場合、13/18/19/20だけを再送するので、RetryのLatencyが最小限に抑えられるという話である。
この方式がうまく行くかどうかは、エラーの発生率に依存する訳だが、試算の結果として元々のRaw Burst Errorの発生率が10-6程度であれば、最終的なFITは4.6E10-10程度に抑えられるので、1FIT未満という設計目標を抑えられる、という話だそうだ(Photo14)。
-

Photo14:ただこの前提はFBERが10-6以下という条件での話ではあるが

FLITを利用すると、実際にはバスの利用効率が上がる結果として、特にデータサイズが小さい場合には3倍近い効率が実現できる、というのもGen 6の特徴であり(Photo15)、またFLITを利用すると特にデータサイズが小さいときにはLatencyに若干のインパクトがあるが、データサイズが大きくなるとむしろLatency削減の効果がある、とされる(Photo16)。
-
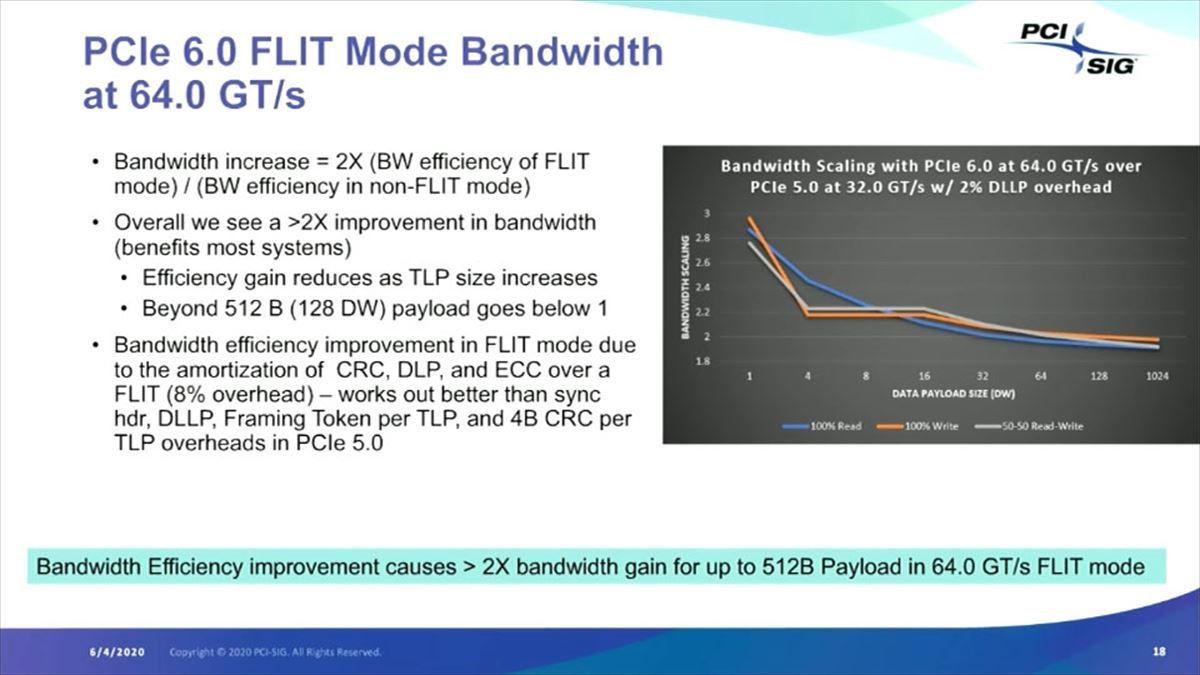
Photo15:ちょっと判りにくいかもしれないが、要するにデータペイロードサイズが小さいと、PCIe Gen5でもPCIe Gen6でもフルのスピード(32Gbpsなり64Gbps)は出ない訳で、ずっと落ち込むのだが、FLITを利用することでその落ち込みをカバーできる結果、データサイズが小さいときには3倍位の帯域比になるという話
-

Photo16:FLITはサイズ固定なので、x1とかだと無条件で32nsが必要になり、Retryの効率化で多少相殺されるとしても10nsほど増えるが、データサイズが大きくなるとこのデメリットはほぼ消え、むしろメリットが出てくる訳だ


着々と進むPCIe Gen6の仕様策定
さて、FLITの話はこれで終わりであるが、他にもう1つL0pという省電力ステートが追加された。Gen5ではL0/L0s/L1/DLW/Speed Changeといくつかの省電力モードがあるが、Gen6ではx16構成向けに、x8だけを有効にするL0pというステートが新たに追加された(Photo17)。これは特にサーバーなどのワークロード向けで、性能にそれほどインパクトを与えずに消費電力を落とす方法として利用可能なオプションとして提供されることになる模様だ。
-

Photo17:8レーンのみIdle状態にして、残りはそのままActiveなので、Interruptとかメッセージ転送などには問題が無い。一方データのバルク転送などの場合にはx16をActiveにすることでフルの帯域が利用できるが、Power DownではなくIdleからActiveなので、Latencyは最小に抑えられるという訳だ。それは良いのだが、これが自動で行われるのか、アプリケーション(というか、ドライバだろうか?)から指示を出すのか、が良くわからない

最後にPCI Express Gen6の主要な目標とその達成可能性をまとめたのがこちら(Photo18)。いくつかのものはDesign dependent(実際の設計に依存)だし、Latencyはx1/x2レーンではやや厳しい(FLITを使う限り多少オーバーするケースがある)ものの、概ね順調に推移しており、今のところこの仕様のままでDraft 0.7がまとまりそうという話であった。
-
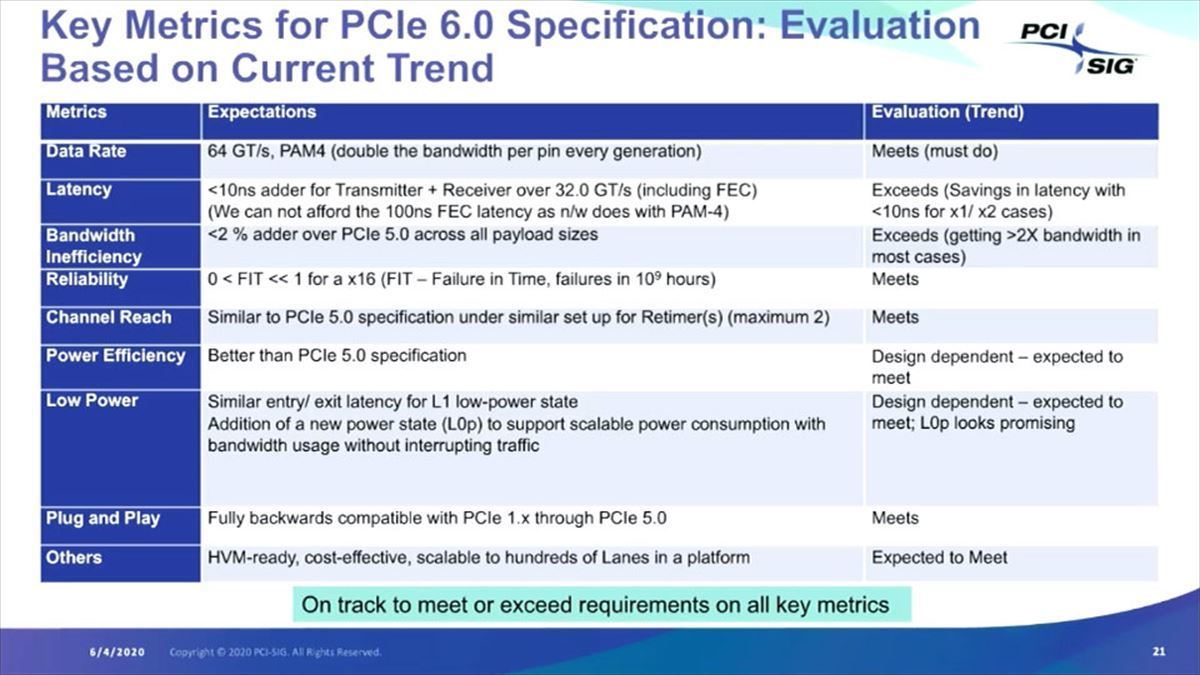
Phtoo18:ただこのリストを見るとコストの話が出ていないのだが、実際には5nmあたりがターゲットプロセスになると思われるので、7nmでEUVを使わないTSMCのN7とかと比較するとむしろ安くなるのかもしれない