カリフォルニア大学サンディエゴ校、コーネル大学、ミシガン大学、カリフォルニア大学ロスアンジェルス校の大学院の学生がRISC-Vコアを使った3階層のメニーコアチップを開発し、Hot Chips 29で発表を行った。
発表のタイトルスライドには、設計に参加したこれら4つの大学の28人の名前が書かれているが、その中でUC サンディエゴ校のScott Davidson、コーネル大のKhalid Al-Hawaj、ミシガン大のAustin Rovinskiの3氏が登壇して発表を行った。

|
|
Hot Chips 29での発表のタイトルスライド。開発に参加した4大学28人の大学院生の名前が載っている (このレポートのすべての図は、Hot Chips 29におけるCelerityチップの発表スライドのコピーである) |
カリフォルニア大学のサンディエゴ校とロスアンジェルス校は比較的近いが、それ以外の大学は遠く離れている環境で、大学院の学生だけで、わずか9か月で設計を完了しテープアウトしたというのは驚異的な開発スピードで、注目に値する。
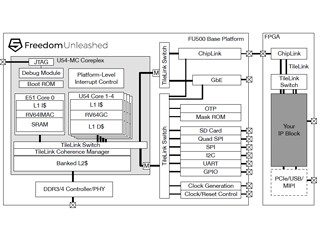
「Celerityチップ」は5コアのRocketコア、496コアのVanilla-5コアとニューラルネットの畳み込み処理専用の10コアの合計511個のRISC-Vコアを集積している。Rocketコアとニューラルネットのアクセラレータは625MHz、496コアのメニーコアチップは1.05GHzで動作し、DDR DRAMコントローラは400MHzクロックで動作させている。
CelerityチップはTSMCの16nm FFCプロセスで設計され、チップサイズは5mm×5mmで、約385Mトランジスタを集積している。チップは672ピンのBGAパッケージに入れられている。
次の図の右側に描かれているのは、設計を担当した4大学のロゴマークである。

|
|
Celerityチップの概要。TSMCの16nm FFCプロセスで作られ、25mm2チップに385Mトランジスタを集積する。3階層の処理ユニットの合計で511個のRISC-Vコアと2値化ニューラルネットのアクセラレータを集積する |
Celerityチップは、5つのRocketコア、496個のVanilla-5コアアレイ、ニューラルネットのアクセラレータという3階層の処理ユニットを持っている。Rocketコアの階層は汎用の処理ユニットであり、フレキシビリティが高い。このため、SPECベンチマークプログラムのように汎用の処理やOSの実行、IOやメモリの管理などを担当させる。
496コアの高並列階層は、中程度の柔軟性とエネルギー効率を持ち、粗粒度、および細粒度の並列処理を担当させる。ニューラルネットに特化したアクセラレータは、専用の処理を高いエネルギー効率で実行させる。

|
|
柔軟性の高い汎用処理階層はOSやI/O、メモリ管理などを担当。高並列処理階層は粗粒度や細粒度の並列処理を担当。専用処理階層は特化した処理を高いエネルギー効率で実行する |
Celerityチップの汎用処理階層は5個のRocketコアで構成されている。汎用処理階層は、SPECベンチマークのような汎用的なアプリケーションやTCP/IPスタックのようなOSの処理、例外処理などを行う。
RocketコアはRV64G命令セットをサポートする5段パイプラインのインオーダのスカラプロセサであり、16KBで4wayの命令キャッシュと、同じ構成のデータキャッシュを持っている。
このRocketコアは0.97mm2で625MHzクロックで動作する。

|
|
汎用処理層は5個のRISC-V Rocketコアで構成されている |
Celerityチップの次の処理階層は496個のタイルを2次元メッシュで接続した高並列処理階層である。各タイルは、RISC-V Vanilla-5コアに命令メモリとデータメモリが付き、メッシュ接続用のルータが付いている。

|
|
Vanilla-5コアを使った496個のタイルをメッシュ接続する高並列処理階層 |
Vanilla-5コアは5段パイプラインのインオーダ実行コアで、4KBの命令メモリと4KBのデータメモリを持っている。コアのサイズは0.024mm2で、1.05GHzのクロックで動作する。そして、コア間をつなぐリンクのバンド幅は80Gbpsのフルデュプレックスである。
Vanilla-5コアの命令セットアーキテクチャはRV32IMである。このコアはオープンソースで提供されている。
高並列処理階層は、並列度の高い処理を、汎用処理階層より高いエネルギー効率で実行する。

|
|
メニーコアアレイは16×31の2次元メッシュアレイで、496個のVanilla-5コアで作られている。並列度の高い処理を、汎用処理階層より高いエネルギー効率で実行できる |
メニーコアアレイは16×31のアレイになっており、無限の長さのデッドロックフリーの通信ができるようになっている。プログラミングモデルはMIMDで、細粒度の並列プログラムの記述ができる。各コアには4KBのデータメモリしかないが、メモリへの書き込みは、他のタイルのデータメモリにも書き込めるようになっている。
コア間の通信はバッファ間の通信であり、Producer-Consumerモデルで同期をとっており、ストリームプログラミングモデルが使えるようになっている。

|
|
メニーコアアレイは496個のタイルが2次元のメッシュネットワークで接続され、リモートのタイルのメモリに書き込みができるようになっている。タイル間でProducer-Consumerの同期がとれ、ストリームプログラミングが可能になっている |
Celerityチップのタイルは0.096mm2であるが、昨年のHot Chips 28で発表されたPrinceton大学のOpenPitonのコアは1.17mm2で、プロセスの微細化の違いを補正しても12倍のサイズである。また、Raw Tileの面積は5.25倍、MIAOW GPUのコア面積は9.75倍である。結果として、右の棒グラフに示すように、プロセスの微細化を補正した単位面積当たりの実行スレッド数では、Celerityが圧倒的に高い性能を示している。

|
|
Celerityとこれまで発表されたメニーコアチップのコアの面積の比較。Celerityはこれらに比べて、スレッド/mm2が高い |