Wave Computingは、ディープラーニング用の高性能のLSIを開発しているスタートアップであるが、そのLSIや計算のやり方については公開情報が無く、どのような仕組みであるかは分からなかった。
しかし、4月26-27日に米国サンタクララにて開催された「Machine Learning Developers Conference」において、同社は「Coarse Grain Reconfigurable Array (CGRA)」と呼ぶ方式で処理を行う「Dataflow Computing Unit(DPU)」と呼ぶ高性能LSIを開発していることを発表した。また、DPUを使った開発システムのアーリーアクセスプログラムを開始しており、今年の第4四半期には製品を出荷することも発表した。
この発表資料などを基に、DPUとDPUを使ったディープラーニング用のシステムを見て行こう。
ディープニューラルネットワークは、多数の入力がニューロンに与えられ、ニューロンが計算を行って出力を出し、それを次のニューロンに伝えるというユニットが複合したグラフ構造となっている。Wave Computingの方式は、このグラフをチップ上に作ってしまい、それぞれのニューロンは通常は低電力のスリープ状態で、信号が到来したときだけ動くという非同期型の信号処理を行うという、ある意味では、本当の神経網に近い動きをする。
このProcessing Element(PE)のグループがCoarse Grain(粗い粒度)で、その間の接続をFPGAのように再構成可能にしているので、このアーキテクチャをCoarse Grain Reconfigurable Array(CGRA)と呼んでいる。
次の図に示すように、左上のニューラルネットは、フレームワークで表現すると右上のようなグラフになる。これをハードウェア的に表現すると、右下のように、それぞれのノードの機能はPEのグループで実現され、機能間を接続する矢印のエッジを持つグラフとなる。これを左下の図のようにDPUのPEにマッピングし、チップ内ネットワークで接続してチップ上にグラフを作ってしまう。
C言語などで書かれたプログラムもグラフ表現に変換することができるので、Wave ComputingのDPUは、GPUのディープラーニングシステムのようにCPUを必要とせず、DPUだけで推論や学習を行うシステムを作ることができるという。
1つのDPUチップ、あるいは開発システム内のDPUですべてのネットワークを収容できる場合は良いが、ニューラルネットの規模が大きく、一度に全体を収容できない場合には、部分的にハードウェアにマッピングして計算を行いその結果はメモリに格納し、次は別の部分をマッピングして、必要に応じてメモリから前の計算結果を読み出して、計算するという方法で順に計算を行っていくと思われる。

|
|
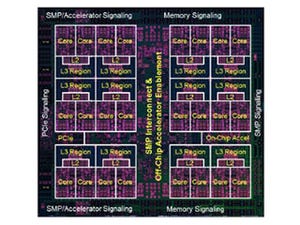
DPUでは、いくつかのPEからなる粗い粒度の塊をネットワークで接続して、チップ上にグラフを作る (このレポートの図は、Machine Learning Developers ConferenceにおけるWave ComputingのDarren Jones氏とSonicsのDrew Wingard氏の発表資料のコピーである) |
Wave ComputingのDPUは16K個のPEを1チップに集積し、今回発表した開発システムは、3U筐体に16個のDPUを搭載している。この筐体1台で、8ビット整数のピーク演算性能は2.9PetaOps/sである。これは16個のDPUの性能であるから、DPU 1個あたりでは、181.25TeraOps/sという計算になる。
NVIDIAのP40 GPUの8ビット整数でのピーク演算性能は47TeraOps/sであるので、DPUはP40の4倍弱の性能を持っている。また、DPUはGoogleのTPUと比較しても2倍程度のピーク演算性能となっている。
そして、開発システムは高バンド幅の3D積層DRAMであるHybrid Memory Cube 2を4個使用しており、128GBの容量の高バンド幅メモリが搭載されている。また、2TBのDDR4メモリと32TBのSSDを持ち、16レーンのPCIe3.0ポートを持っている。
なお、開発システムは、最大4筐体の開発システムを接続して、64DPU、11.6PetaOps/sまで拡張することができる。

|
|
3U筐体に16個のDPUを収容するWave Computingの開発システム |