D-Waveマシンのハードウェア
本当の量子コンピューティングを行うチップは小さいが、D-Waveマシンは底辺が1.8m程度の正方形で、高さは1.8mより多少高いという大きな箱に入っている。この箱の大部分は、ノイズとなる外部からの電界や磁界を遮蔽するためのものである。図6は組立中のD-Waveマシンの写真であるが、左側の扉の内側で光っているのは銀(めっき)の内扉である。電気抵抗の低い銀を使って、極力、外部の電界を遮るファラデーケージを作っている。

|
|
図6 組立中のD-Waveシステム。内側に銀の扉がありファラデーケージを構成している |
そして、断熱量子アニールの最大の敵は熱雑音で、D-Waveのシステムでは、絶対温度で0.02度という低温を実現している。冷凍機の負荷は外部から流入する熱で、量子コンピュータチップの消費電力は微々たるものであるので、Qubit数を増やしても消費電力は変わらないという。

|
|
図7 中央の円筒が超電導量子コンピュータチップを冷却する冷凍機。消費電力は15.5kWで、これはQubit数を数千に増やしても変わらない |
常温の外部と量子コンピュータ本体とは192本の配線でつながっているが、77K、4K、1K、0.3K、0.02Kと温度階層を設けて、熱の流入を抑え、量子コンピュータチップを含む10kgの部分を0.02Kに冷却している。なお、修理などでチップを室温に戻すと、0.02Kまで冷却するには半日程度かかるとのことである。
また、外部からの電磁界も系のエネルギーに影響を与える雑音となる。このため、多重のシールドを施して外部からの電波を遮断している。また、磁界は10-9テスラ以下と地磁気の5万分の1に抑えている。
さらに振動も抑えており、コンピュータというより、敏感な実験装置という感じである。

|
|
図8 図7の円筒の中に入る量子コンピュータ本体。チップを絶対温度で0.02度にするため、77K、4K、1K、0.3K、0.02Kと温度階層を設けている。右はチップ搭載部分の拡大写真 |
図9は512-Qubitを集積するVesuviusチップの写真で、左側のメモリアレイのように見える規則的な部分が量子コンピュータ本体で、その他の部分はチップをプログラムする情報を記憶するメモリや制御回路、そして外部とのデータのやり取りを行う入出力回路となっている。これらの回路も、超電導のジョセフソン素子で作られている。

|
|
図9 512-QubitのVesuviusチップの写真。左側の規則的に見える四角い部分が量子コンピュータで、その他の部分は、チップをプログラムするデータを保持するメモリや制御回路、IO回路などである |
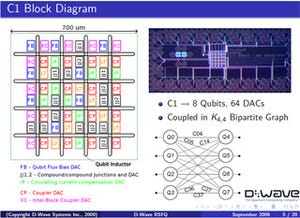
Vesuviusチップのアーキテクチャは、図10のようになっている。8-Qubitが単位で、左上の図のように、この8-Qubitのグループが8×8個並んでいる。そして、右下の図のように、Q1~Q4の各QubitはQ4~Q8のQubitへの直接の結合を持っている。そのため、右上の図のように、Q1~Q4は上辺に、Q5 ~Q8は右辺に配置され、中央の部分は結合マトリクスとなっている。また、各Qubitは、隣接する8-Qubitグループと接続する2本のリンクを持つ構造となっている。
なお、D-Waveのチップは、各Qubitに記憶する0と1の重なりの比率や、6本のリンクの結合の強さを設定できるようになっており、これで解くべき問題をプログラムする。

|
|
図10 Vesuviusチップのアーキテクチャ |
図11はD-Waveマシンで最適化問題を解く手順を示すものである。まず、1.で解くべき問題を各QubitのバイアスhiとQubit間の結合係数Jijの形で表現する。そして、2.でこの情報をチップに設定する。

|
|
図11 D-Waveマシンの動作手順 |
3.でチップを初期化して、量子アニールを行い、最終状態のHproblemを得る。さらに、4.で各Qubitの状態を読みだす。
通常のビットであれば、単純にその値を読めばよいが、Qubitの場合は、読みだされる値は、多数回読みだせば、記憶されている0と1の比率に応じて0や1が読みだされるが、1回の読み出しではどちらが出てくるのかはわからない。
このため、2.~4.のステップを多数回繰り返して、読み出しを行う。そして、各読み出しで得られた0/1の値を、解くべき問題の解の評価関数に代入して、どの程度、良い解であるかを判定する。この手順を多数回行い、もっとも良い解を選び出す。
図12と13は、GoogleのAI Labのブログにも掲載されている評価結果であるが、D-Waveマシンを使ったQuantum Anneal(破線)と、通常のプロセサを使って通常のアニールをシミュレーションするSimulated Anneal(実線)の計算時間を比較したものである。
図12の問題1ではほとんどのケースで、通常コンピュータによる最適化の方が速いという結果になっている。なお、D-Waveは、この問題は理想的なQAでも速度が上がらない問題であり、意味がないテストであると主張している。
一方、図13の問題2は、たくさんの浅い谷があるが、本当の最適値の深い谷は少ないという問題で、規模の大きい問題では、浅い谷を抜け出すのが難しいSAに比べてQAの方が数万倍も速いという結果になっている。

|

|
|
図12 問題1の量子アニール(破線)とコンピュータによるシミュレーテッドアニールの所要時間比較 |
図13 問題2の量子アニール(QA:破線)とコンピュータによるシミュレーテッドアニール(SA:実線)の所要時間比較 |
そして、今回、D-Waveは新しい結果を示した。このデータを発表するのは今回のCool Chipsが初めてであるという。
図14はベンチマーク1を使い、D-Waveの量子コンピュータと3種の通常コンピュータを使うシミュレーテッドアニーリングのプログラムで、最適解が得られる比率をプロットしたもので、量子コンピュータでは常に最適解が得られているが、通常コンピュータの場合は、問題が小さい場合は最適解が得られるが、規模が大きくなるにつれて最適解が得られる比率は小さくなり、300-Qubit以上を必要とする問題では、最適解は得られていない。

|
|
図14 量子コンピュータと3種の通常コンピュータとの最適解が得られる確率の比較 |
図15はベンチマーク2を使い、最良の解を得るまでの時間(分布の中央値)を比較したもので、問題規模が非常に小さい場合を除き、CPLEXやMETSTABUというプログラムに比べて、Vesuviusチップの計算時間が短く、500-Qubitの場合は、3万5500倍も速いという結果になっている。

|
|
図15 最適解が得られるまでの時間の比較 |
図16はベンチマーク2の中の上位25%の難しい問題だけを取り出して比較したもので、D-Waveでは問題規模によらずほぼ一定の時間で解けているが、通常コンピュータでは計算時間が増加するので、500-Qubitの問題では11万8000倍という大きな性能比となっている。

|
|
図16 図15のベンチマークの内の上位25%の難しい問題での比較。500Qubitでは11万8000倍の性能比となっている |
(後編に続く)