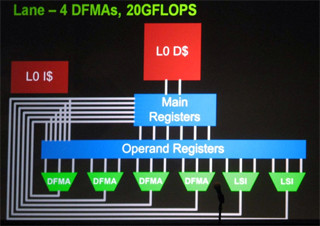
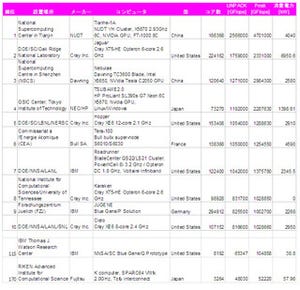
スパコンの多面的性能評価を行うHPC Challenge
Top500はLINPACKの性能だけに基づくランキングで、スパコンの一面しか評価していないという非難があり、その結果、多面的な評価を行うために開発されたのがHPC Challengeというベンチマークである。

|
|
HPC Challengeベンチマークの主導者のJack Dongarra教授 |
HPC Challenge(HPCC)は7種のプログラムを使って色々な条件での測定を行うもので、スパコンの多面的な評価はできるが、一方、それぞれのプログラムの実行性能の重要性はユーザごとに違い、LINPACK性能だけに基づくTop500のように単純に順位を付けることができない。
HPCCは、大きく分けて、Class-1とClass-2の賞があり、Class-1は
- Global HPL
- Global RandomAccess
- EP STREAM(Triad) per System
- Global FFT
の4種の測定それぞれでの性能でランキングを行っている。7種のプログラムからなぜ、この4つを選ぶのかも議論のあるところであり、さらに、これらの4つの測定を総合して1つの性能指標を出そうとすれば、ユーザごとのニーズが違うので議論百出でまとまらないであろう。
なお、HPCCでは、1つのシステム構成で全部の測定を行うことが義務付けられており、それぞれのベンチマークプログラムに対して、システムの構成を最適化することはできないようになっている。また、Top500も同様であるが、測定結果を登録したシステムだけがランキングの対象であり、登録していないシステムは対象外である。
Class-1のHPLはLINPACKと同じ連立一次方程式を解くプログラムで、LINPACKに近い性能が出るベンチマークプログラムである。また、 RandomAccessは、システム全体のメモリに対して乱数で発生したメモリアドレスに乱数の値をXORで書き込むベンチマークで、性能単位のGUPSはGlobal Update Per Secondの頭文字を集めたものである。このベンチマークは浮動小数点演算部分が無く、GPUは役に立たないベンチマークである。
そして、Class-1のFFTは高速フーリエ変換を行うベンチマークであるが、3次元のFFTを行うためノード間でのデータ通信が多く、ノード間のインタコネクトの性能が大きく影響するベンチマークである。
Class-1の最後のEP STREAMは単純な積和計算を全ノードで並列に行うベンチマークで、一般には演算性能よりもメモリのバンド幅が問題になるベンチマークであり、測定単位はバイト/秒となっている。

|
|
Class-1の測定順位 |
このリストを見て気が付くのは、Top500で上位を占めたGPUアクセラレータを使うハイブリッドシステムがランキングに含まれていないことである。HPCCの難しさは1つのシステム構成で全部のベンチマークを測るという点で、7種のプログラムに対してGPU用のチューニングされたコードを開発するのは手間が大変というのが、GPUアクセラレータを使うシステムがエントリしていない1つの理由ではあると思われる。そして、RandomAccessなどのいくつかのベンチマークではGPUは全く出番がなく性能に貢献しないというのが、HPCCにエントリしていないもう1つの理由ではないかと思われる。
LINPACKだけの評価であるTop500ではGPUベースのシステムが上位を占めたが、HPCCのような多面的な評価では、まだ、汎用CPUの巨大クラスタであるCRAYのXT-5や、BG/Pが強いというところであろう。また、NECのSX-9がG-FFTで1位となったのは特筆に値する。
そして、Class-2は解法のエレガントさやプログラムの簡潔性などを競うもので、Dongarra先生を始めとする10人のジャッジの投票で決められる。この10人の中にはFFTの開発者である筑波大の高橋先生が含まれている。
今回のClass-2の候補者は、
- IBMのGeorge Almasi氏のUPCとCAFによる記述
- Rice大のJohn Mellor-Crummey氏のCAFによる記述
- 筑波大のJinpil Lee氏のXscalableMPによる記述
- バルセロナSCのJoseph Perez氏のSMPSによる記述
の4件であった。そして、最も生産性が高いシステム賞はIBMのAlmasi氏のUPCとCAFによる記述が受賞し、最も生産性が高い言語賞はRice大のMellor-Crummey氏が受賞した