HSAの概要
これを実現するためにHSAでは、CPUやGPUなどのすべてのプロセサが共通のメモリ空間をアクセスできるようにする。現在のCPUはページテーブルを使ってメモリを管理しており、アプリケーションが意識している仮想アドレスとメモリページの物理アドレス対応は変わってしまうことがある。このため、GPU側も同じアドレス変換テーブルを使って物理アドレスへの変換を行わないと、アプリケーションと話が通じなくなってしまう。
そして、複数のプロセサがメモリをアクセスすると、他のプロセサからみてメモリアクセスの順序がどう見えるかという面倒な問題が出てくる。これらについて、ヘテロなシステムのメモリモデルをどのようにするかをHSAは規定する。

|
|
高レベルのHASの特徴 |
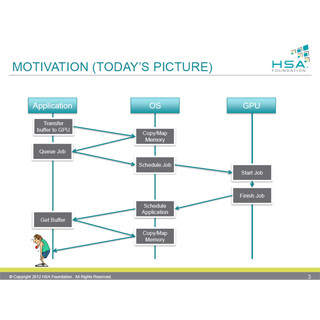
そして、OSを経由してGPUでのジョブの実行を依頼するのではなく、GPUの実行キューにアプリが直接、実行依頼を書き込むようにして、実行開始のオーバヘッドを減らす。
また、高級言語ではGPUプログラミングのサポートや、CPUのように、割り込みで処理するプロセスを切り替えるコンテキストスイッチもHSAで実現する特徴に上げられている。
なお、現状では、これらのHSAのベースとなる単一仮想メモリ空間や、CPU、GPUで共通のアドレス変換メカニズムをサポートするハードウェアは存在しておらず、メンバー各社がこの仕様に沿った製品を開発していくことになる。
メンバーを見ると、FounderはすべてCPU+GPUのSoCを開発する会社である。そして、CPUを開発する会社としてはARMとMIPSを買収したImagination Technologiesが入っている。また、GPUを開発する会社は、AMD、ARM、Imagination、Qualcomm、Samsungがあり、そして、TIはDSPを開発している。HSAとしてはこれらのメンバー会社のCPUやGPUをサポートしなければならない。
このため、仮想的な命令アーキテクチャ(Instruction Set Architecture)として、HSA Intermediate Layer(HSAIL、エイチ-セイル)を定義している。HSAILは各社のハードウェアから独立した並列処理用の命令セットで、JITコンパイラやFinalizerと呼ぶツールで、ハードウェア命令に変換して実行される。

|
|
HSAILは仮想的な命令アーキテクチャで、JITコンパイラやFinalizerで実機の命令に変換される |
そして、HSAILは並列プログラミング用に、並列性を明確に記述できるように定義されている。また、HSAILは例外(Exception)や仮想関数などの高級言語を実現するためのサポートを持つ。
一方、HSAILは、OpenCLの中間言語であるSPIR(Standard Portable Intermediate Representation)よりもハードウェアに近い低レベルのモデルで、OpenCLのコンパイルのスタックに自然にフィットする。そして、HSAILはJava、C++、OpenMPなどの他のハイレベル言語のサポートに適しているという。
次のスライドの左側の図は、現在の実行モデルで、アプリケーションはドメインライブラリやOpenCL、DXxxなどのユーザモードドライバを呼び出し、ユーザモードドライバがグラフィックスのカーネルモードドライバを使ってハードウェアを動かしている。これに対して、HSAでは、HSAドメインライブラリやOpenCLのランタイムはHSAILの命令を実行し、これをHSA JITコンパイラなどで機械命令に変換して、タスクキューイングライブラリ経由でGPUなどのHSAコンポーネントに実行が依頼されることになる。

|
|
HSAの実行モデル |
また、GPUのプログラミングを容易にするため、BOLTというツールを開発していると言う。BOLTはC++のテンプレートで、GPU向けに最適化したScan、Sort、Reduce、Transformなどの一般的に使われる機能を含んでいる。

|
次の図は、Hesssianというカーネルを、各種のプログラムの作り方でコーディングした場合の行数と性能を比較したもので、左側のカラフルな棒グラフが行数、右側の棒グラフが性能である。

|
|
各種のプログラミングモデルでのコード行数と性能の比較 |
左端はシングルスレッドで通常のCPU用に書いた場合で、コードの行数は少ないが、性能も非常に低い。左から2番目はThread Building Blockを使って書いた場合で、マルチスレッドを生成するLaunchのコード行数が増えているが、並列化されるので性能は向上している。3番目は詳細は不明であるが、GPU機能を使って計算性能を上げていると思われ、Algorithmの記述行数が大幅に増えているが、同時に性能も大きく改善されている。
この中で一番性能が高いのは、OpenCLのC版であるが、行数は一番多い。OpenCLのC++版は性能はわずかに下がるものの、C版よりはかなり行数は少なくて済む。C++ AMP(Accelerated Massive Parallelism)ライブラリを使うと更に行数を削減できる。
しかし、右端のグラフのHSAとBOLTライブラリを使用すると、CPUのシリアルコードより少ない行数で、C++と同じ性能が得られるという。
Javaで書いたデータ並列プログラムをGPUを使って高速化するというAparapi(A PARallel API)という方法がある。Aparapiは実行時にバイトコードを見て、OpenCLに変換できる部分はGPUに実行させることにより、性能を改善する。

|
|
Javaでデータ並列処理を記述するAPIであるaparapiを使って書かれたJavaプログラムを、バイトコードの実行時にOpeCLに変換してGPUで実行する |
このAparapiの実装には、次のようなロードマップを考えており、最終的には、Sumatraと呼ぶHSA用のJVMを開発し、GPUで実行できる部分は最適化されたHSAILコードを出力する。

|
|
Javaサポートのロードマップ。左端がHSA以前の現状。右端がHSA対応のJVMを使う将来像 |
SumatraはOpen JDKプロジェクトの一環で、Java 8のマルチコアStream/Lambda APIをGPUコンピューティングに拡張し、2015年のJava 9のリリースに組み込むことを目標としているという。

|
|
Sumatraプロジェクトの概要。2015年リリース予定のJava 9がターゲット |