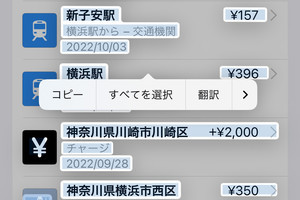
iOS 16では、かな・漢字を含む日本語の「テキスト認識表示」が正式にサポートされました。写真やスクリーンショットといった画像(ラスターイメージ)に含まれる文字列を自動検出し、テキストデータとして取り出せるようにするこの機能は、かなり有用なものです。
テキスト認識表示の仕組み・アルゴリズムは公開されていませんが、日本語テキストを対象にさまざまなテストを行ったかぎりでは、文字列の方向(縦書き/横書き)による明確な区別はありません。文字単位で検出が行われるため、画像に含まれている文字はひととおり認識されます。
ただし、基本的には横書きが想定されているようで、縦書きの場合1文字ごとに改行されることがあります。たとえば、縦書きされた「マイナビ」という文字列がテキスト認識されたものをコピー&ペーストすると、「マ(+改行)」、「イ(+改行)」...のように1文字ごとに改行されてしまいます。
斜めに書かれた文、あるいは斜めに撮影された文の場合、角度や字間により検出結果が異なるようです。縦書きのように1文字ごとに改行されてしまうこともあれば、途中で改行がないひとまとめの文字列として検出されることもあります。
空港の発着案内版を文字が斜めになるよう撮影し、それをテキスト認識表示で試したかぎりでは、「手荷物受取中」などの文字列をそのままコピー&ペーストすることができました。確実にひとまとめの文字列として検出されるわけではありませんが、斜め書きされた日本語の文でも読み取れることは間違いありません。
-

「テキスト認識表示」は斜め書きの文でも読み取れる?