
◆Sandra 20/21 2021.11.31.53 Tech Support(グラフ4~56)
Sandra 20/21 2021.11.31.53 Tech Support
SiSoftware
https://www.sisoftware.co.uk/
前回のレポートでは、SandraがAlder LakeだとMemory Latencyなどを正しく測定できない(というか、Sandraそのものがクラッシュする)ということで数字が出せなかったのだが、最新版である2021.11.31.53ではこれが修正され、すべてのテストが問題なく動作する様になった。ただメモリ回りだけの修正なのかどうか不明なので、今回はCore i9-11900KとCore i9-12900K、それとRyzen 9 5950Xの3つについて全てデータを取り直したのでご紹介したい。ちなみにMT+MC(Multi-Thread+Multi-Core)はCore i9-12900KのP-Core/E-Coreの区別なく全コアで利用、MC(Multi-Core)ないし1T(One Thread)の場合はCore i9-12900KのP-Core(i9-12900K P)とE-Core(i9-12900K E)を分けて結果を示している。
ちなみに前回の2021.11.31.49→今回の2021.11.31.53では単にメモリ回りだけでなく結構あちこち手が入ったようで、結果がだいぶ変わっている。なので、前回のテストとは全く別物、と考えてほしい。
-
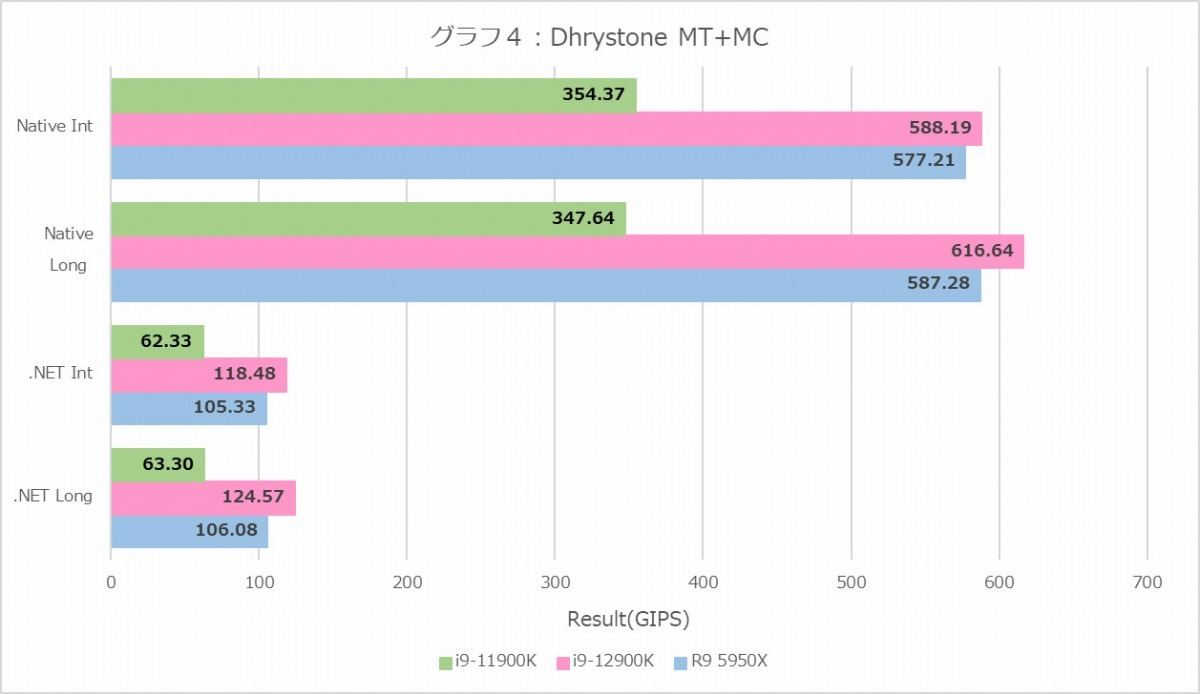
グラフ4

-
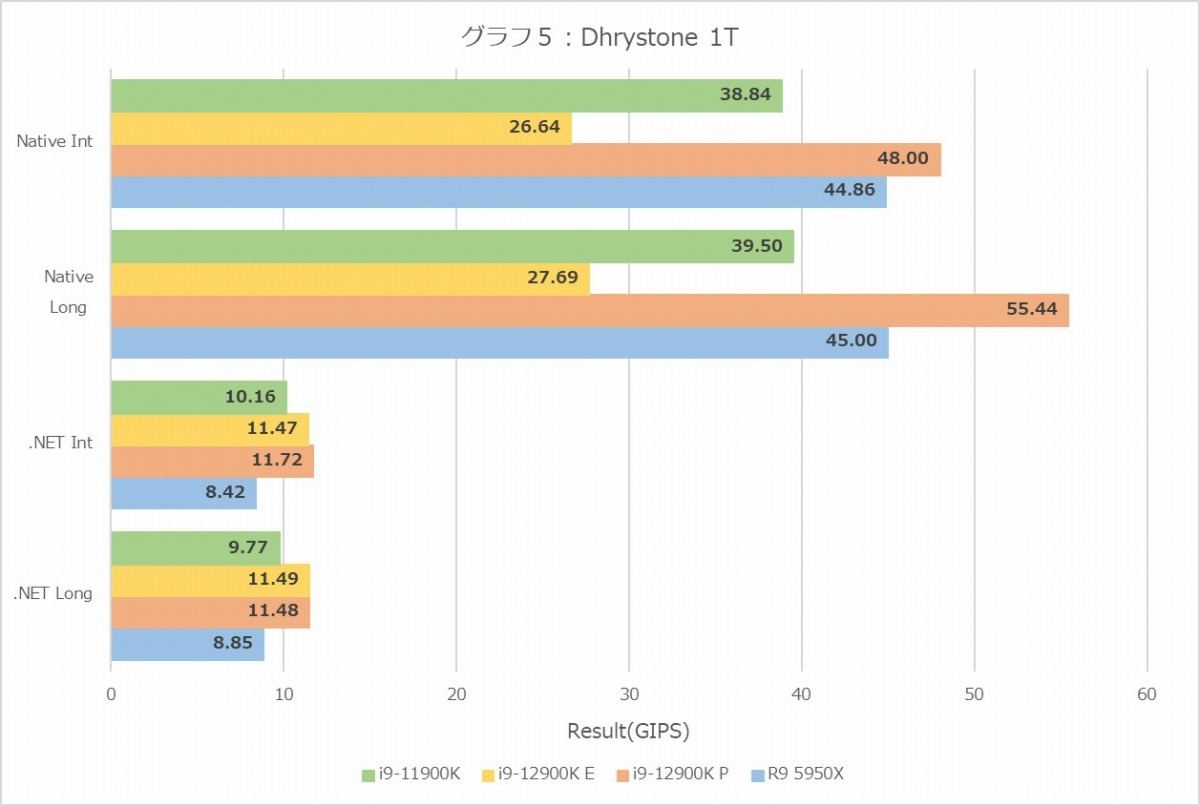
グラフ5

さてまずDhrystone(グラフ4・5)。MT+MC(グラフ4)では全般的に前より数字が落ちており、またRyzen 9 5950XがややCore i9-12900Kに劣っているあたりも興味深いが、それよりも面白いのが1T(グラフ5)。NativeだとP-CoreとE-Coreの間に大きな性能差があるのは当然だが、.NETだとP-CoreとE-Coreに差が見られなくなるのは、ハードウェア側の何かのボトルネックなのか、それともソフトウェア(.NETの実装)の問題なのか、興味あるところだ。
-
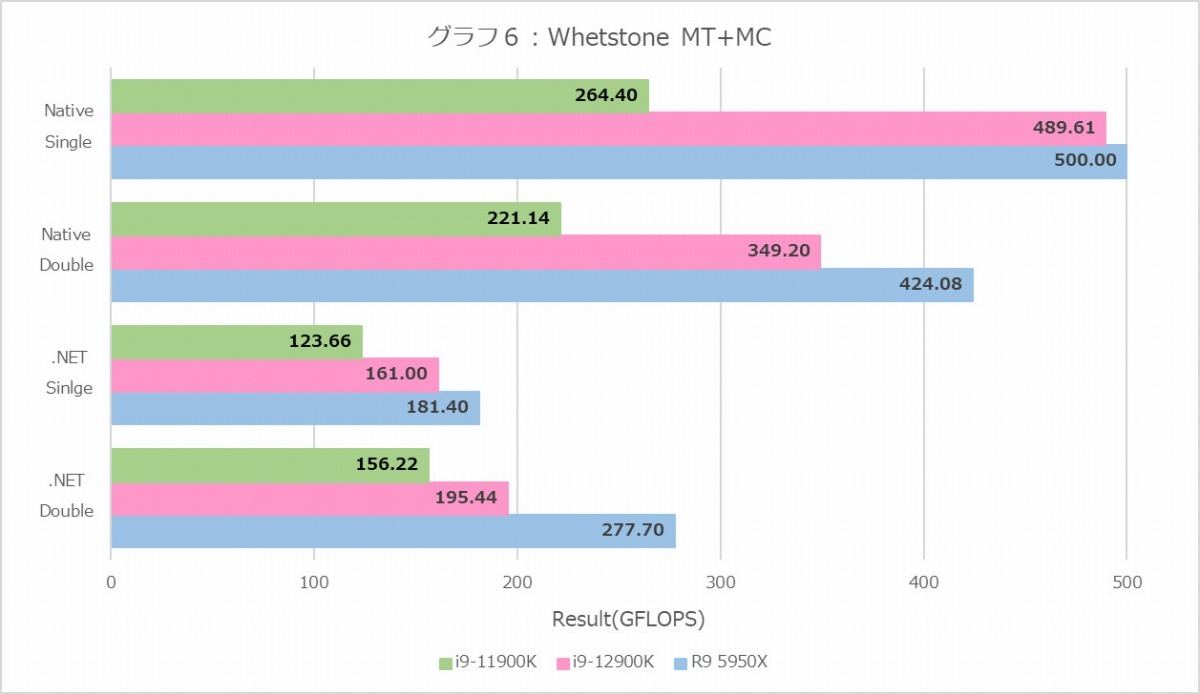
グラフ6

-
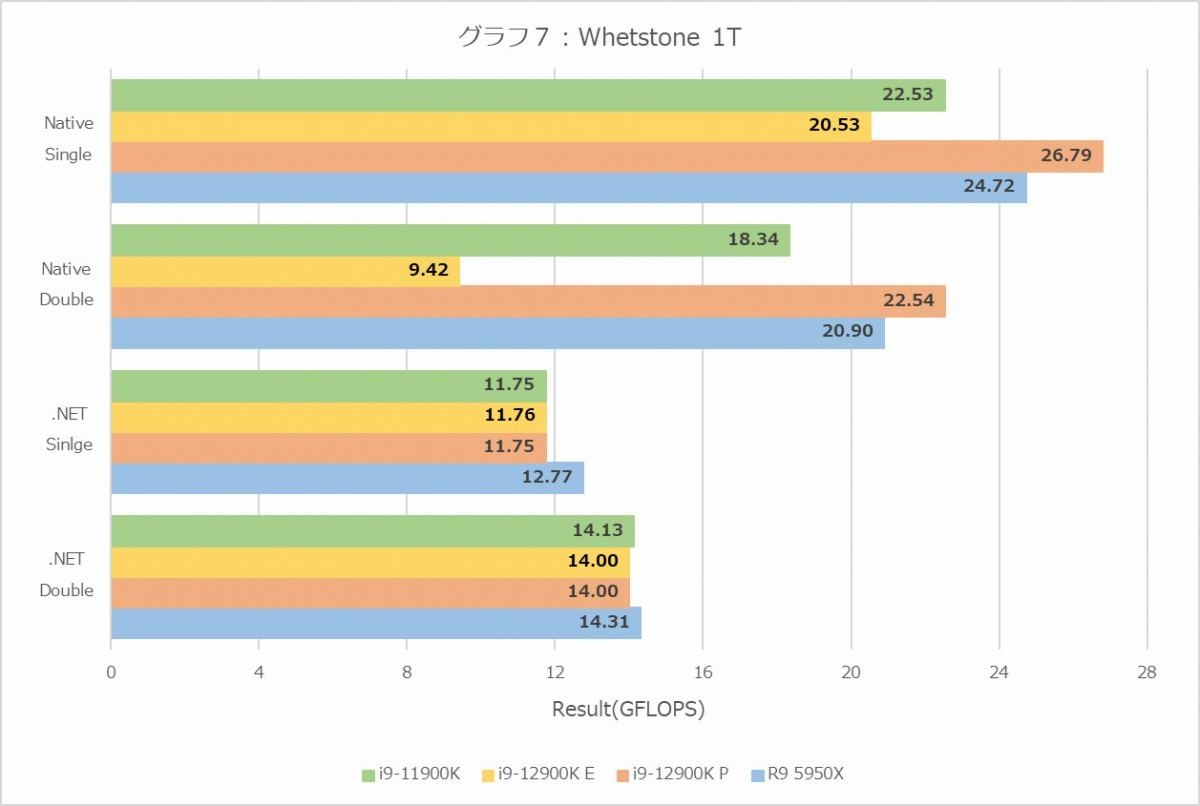
グラフ7

この傾向はWhetstone(グラフ6・7)も似ているが、こちらでは意外にRyzen 9 5950Xが健闘しているのが目に付く。このWhetstoneも面白く、特に1Tにおける.NET DoubleのE-CoreのスコアがNative Doubleより持ち上がっているのはどういう訳だろう? と疑問にならざるをえない。その意味ではちょっとベンチマークへの信頼性そのものが怪しい感じではあるのだが。
-
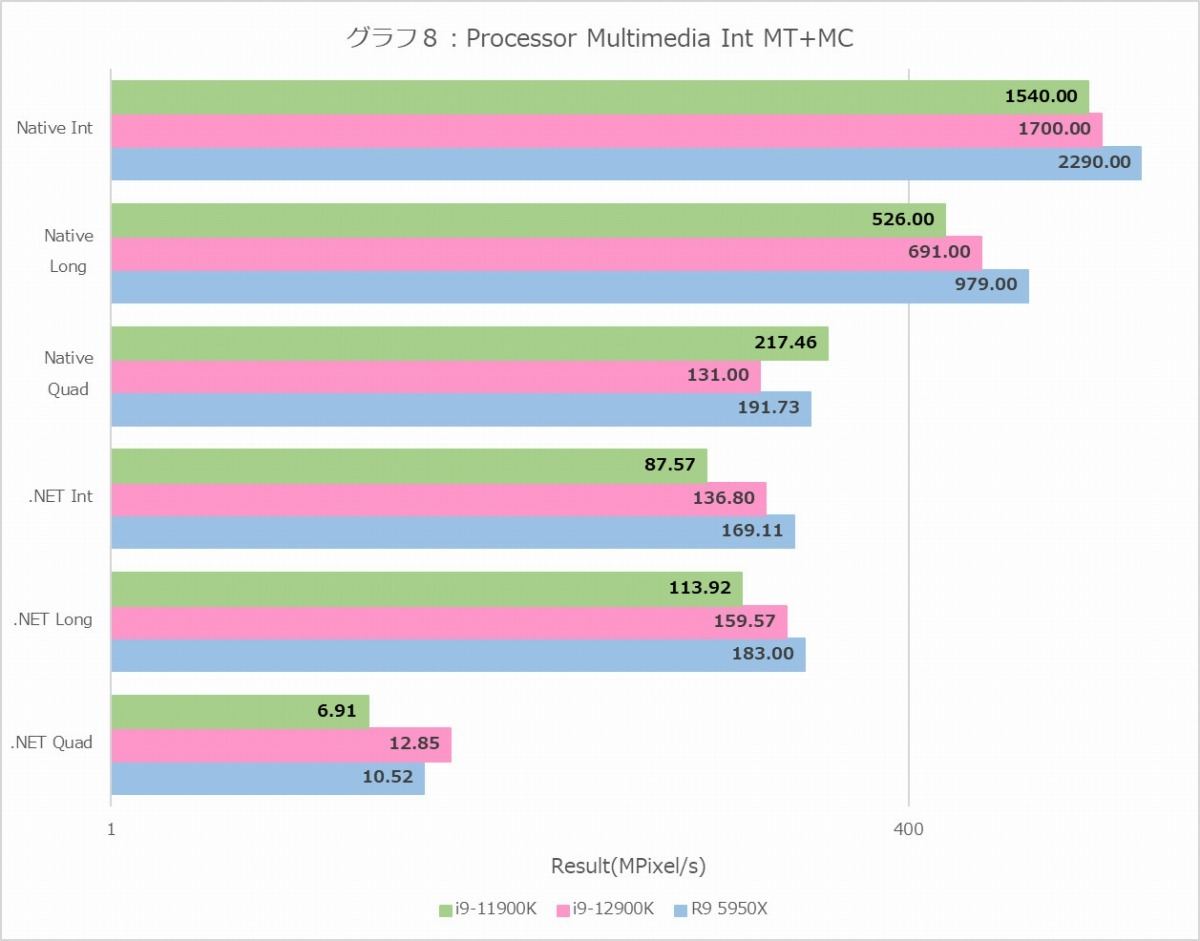
グラフ8

-
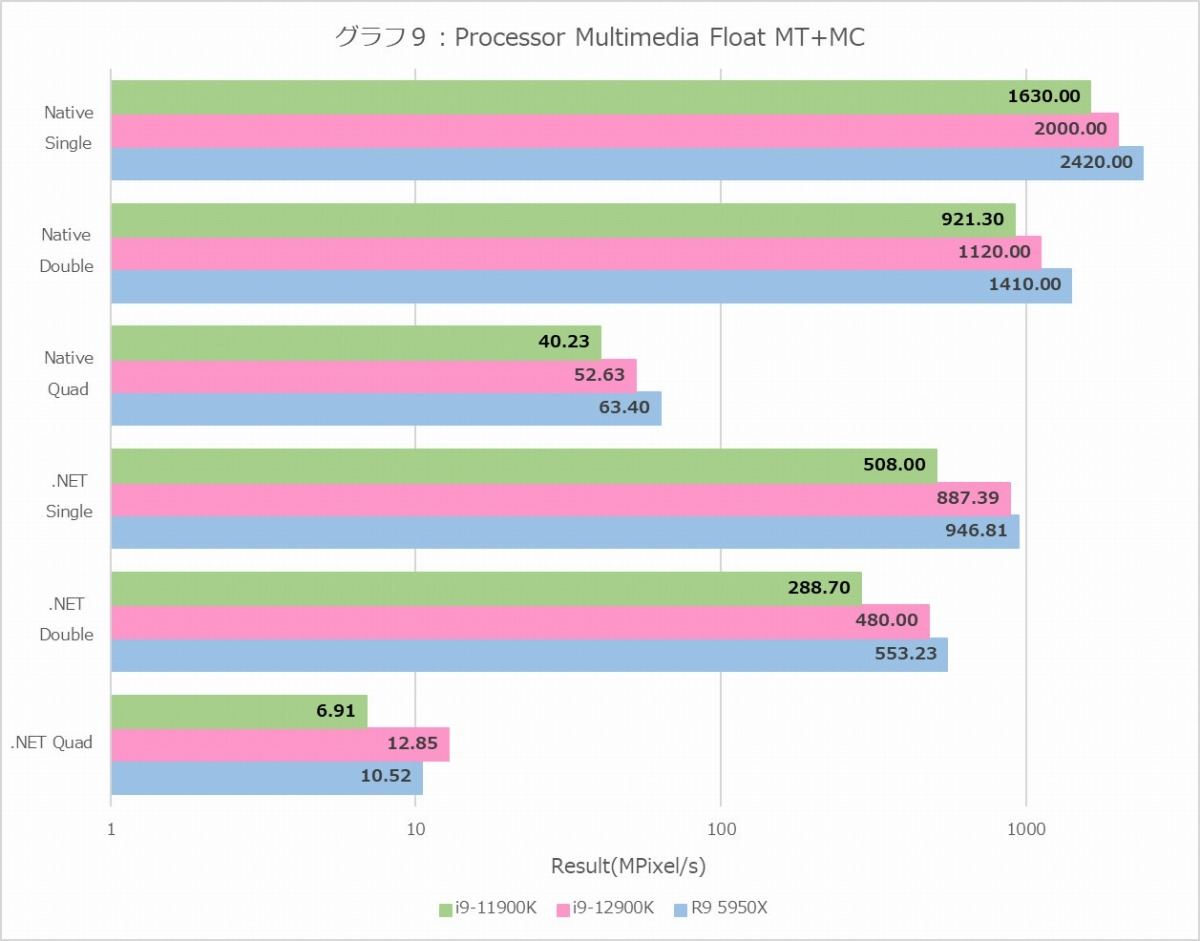
グラフ9

-
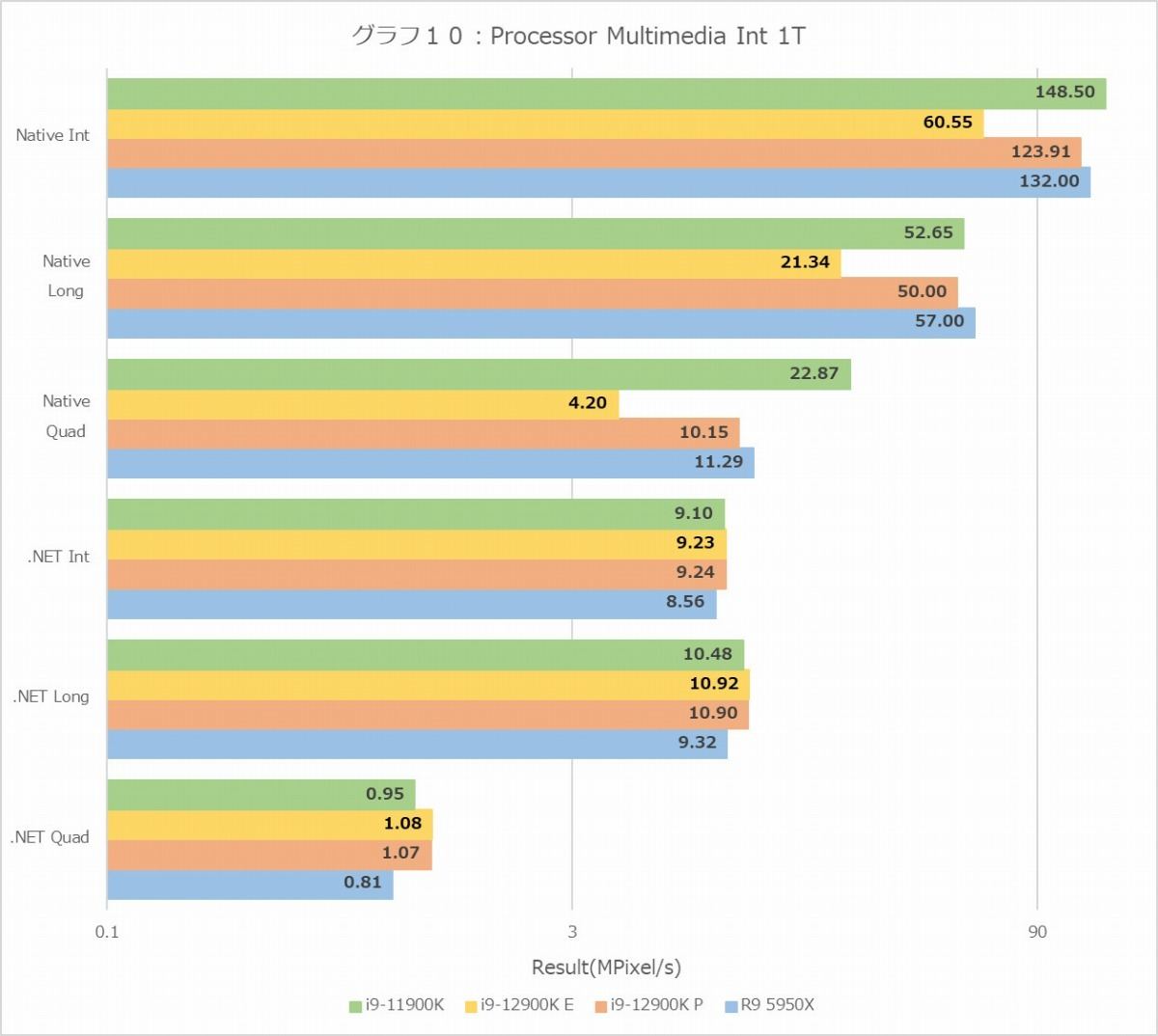
グラフ10

-
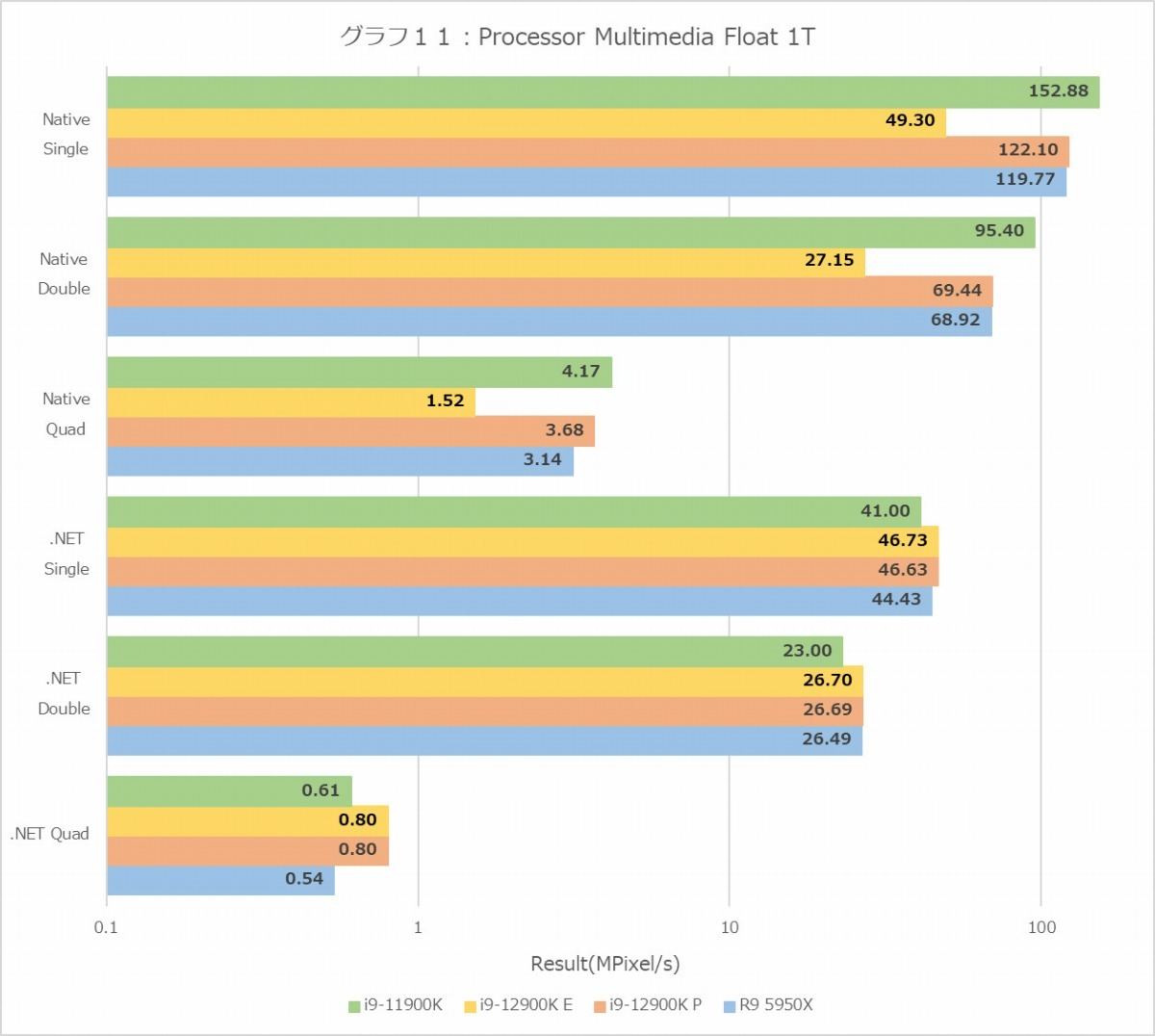
グラフ11

グラフ8~11がProcessor Multimedia、つまりマンデルブロ図形の描画(≒複素演算のひたすら繰り返し)である。MT+MC(グラフ8・9)に関して言えばInteger/Float共にRyzen 9 5950Xが健闘しているという結果になるが、1T(グラフ10・11)でもRyzen 9 5950Xが悪くないスコアを出しているのはちょっと意外である。またNativeにおけるE-CoreのIntegerの性能はP-Coreのほぼ半分、Floatにおける性能は1/3強、というのは先に示したE-Coreの発行ポートの数を考えるともう少し頑張れても良い気がするのだが、あるいはNativeだと内部でFMA命令を発行しているのかもしれない。そもそもE-Coreの場合、Efficiency優先ということは、要するに「命令処理性能は高いがデータ処理性能はそこそこ」と完全に等価ではないにせよ、当然そうした傾向が無いとおかしいし、それを考えればまぁ十分と言えるのではないかと思う。
-

グラフ12

-
グラフ13

-
グラフ14

-

グラフ15

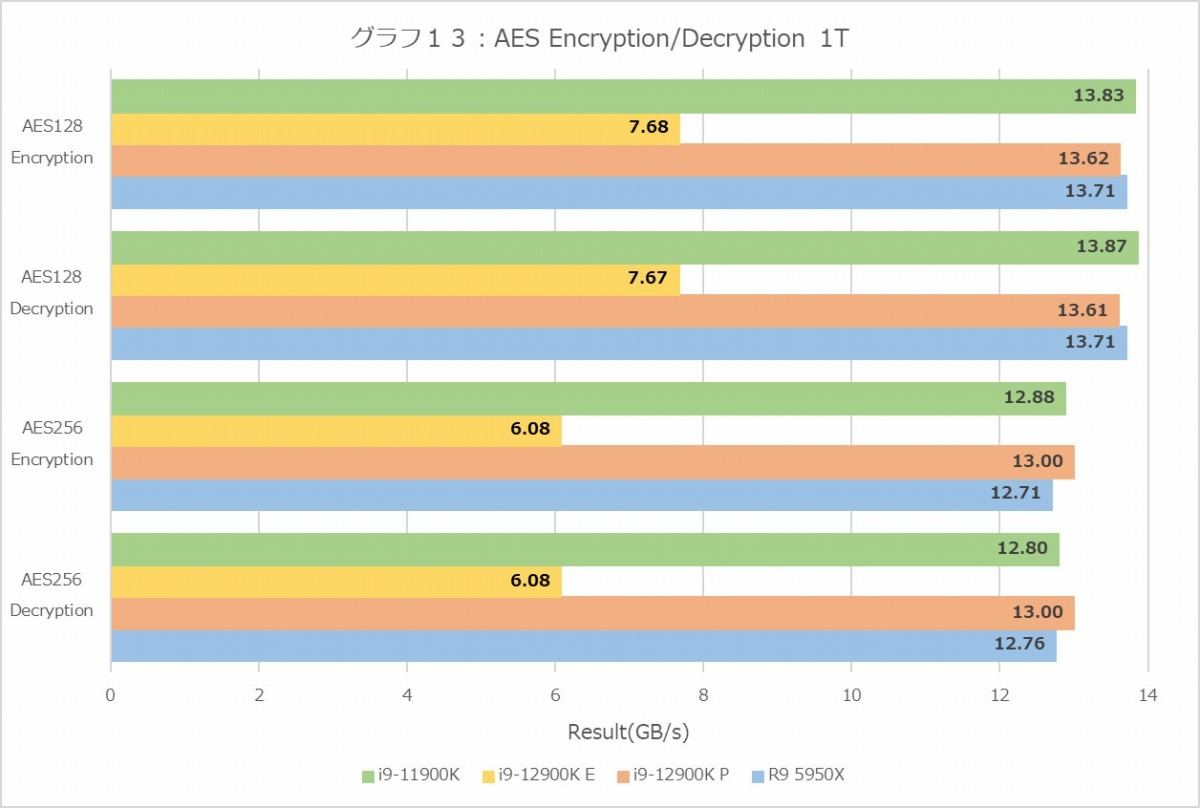
次のAES Encryption/Decryption(グラフ12・13)は、AES命令をサポートの性能評価と言えなくもないが、特にMT+MC(グラフ12)の場合はメモリ帯域も重要なファクターである。ここではDDR5を使えるCore i9-12900Kが圧勝しているわけだが、これはCore i9-11900KやRyzen 9 5950XはDDR4がボトルネックになっているという話であって、なので1T(グラフ13)だとほぼ同等であり、唯一E-Coreが大体半分程度のスループットになっているのは、恐らくE-Coreでは命令実行のスループットそのものが半分になっている(P-Coreでは1cycleで処理できるところが、2cycle掛かるとか)になっているものと想像される。「想像」というのは、まだAlder Lakeに対応したArchitecture Optimization Manualが公開されていないので確認できないためだ(これは後述)。
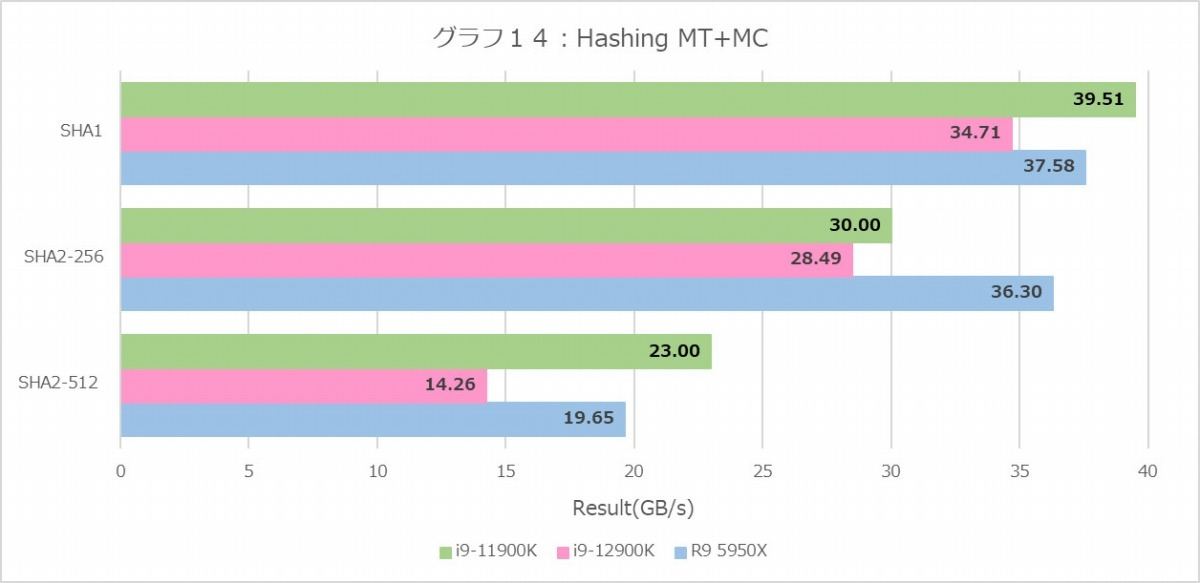
これに比べると専用命令の無いSHAではもう少し数字がばらついている。MT+MC(グラフ14)はまぁ理解できるが、今一つ理解できないのが1T(グラフ15)におけるCore i9-11900Kの異様に高いスコアである(もっともこれ、以前 https://news.mynavi.jp/article/20211104-2177568/images/209l.jpg も傾向として出ていたから、今回が初めてではない)。ただこれを除くと、E-CoreとP-Core、Ryzen 9 5950Xが大体横並びで、ただしSHA2-512のみE-Coreが異様に低く、逆にRyzen 9 5950Xが高いのは非常に納得できる。SHA2-512だとキャッシュラインで溢れる事が多く、結構メモリアクセス性能が効いてくる。E-Coreはおそらくこれがボトルネックになっており、逆にRyzen 9 5950Xは大容量L3でこれを補っている格好だ。
-
グラフ16

-
グラフ17

-
グラフ18

-
グラフ19

-
グラフ20

-
グラフ21

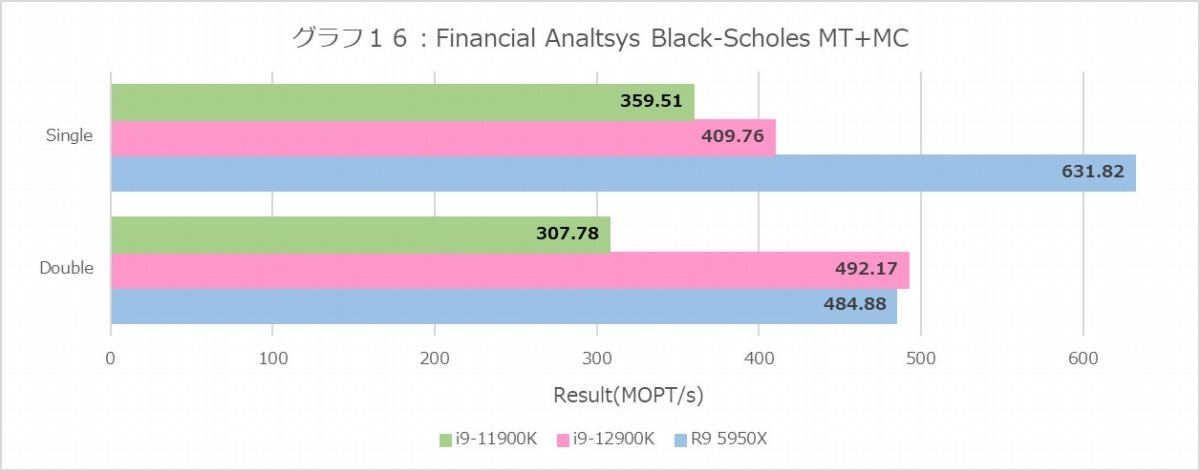
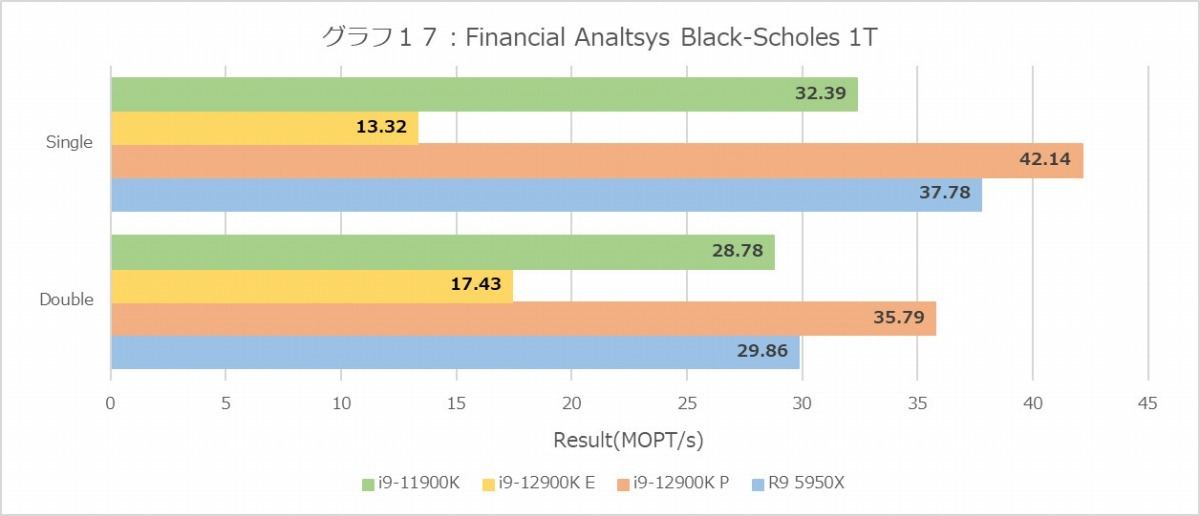
次はFinancial Analysis(グラフ16~21)。まずBlack-Scholes(グラフ16・17)、MT+MCでSingle FloatだとRyzen 9 5950Xが最速なのにDouble FloatだとCore i9-12900Kがやや上回る、というのはなかなか興味深い。E-Coreの性能が低いのはまぁここまで見た通り当然であり、P-CoreがRyzen 9 5950Xを明確に上回るあたりは、Vector Unitの性能差というよりはデコード段の性能差なのかもしれない。
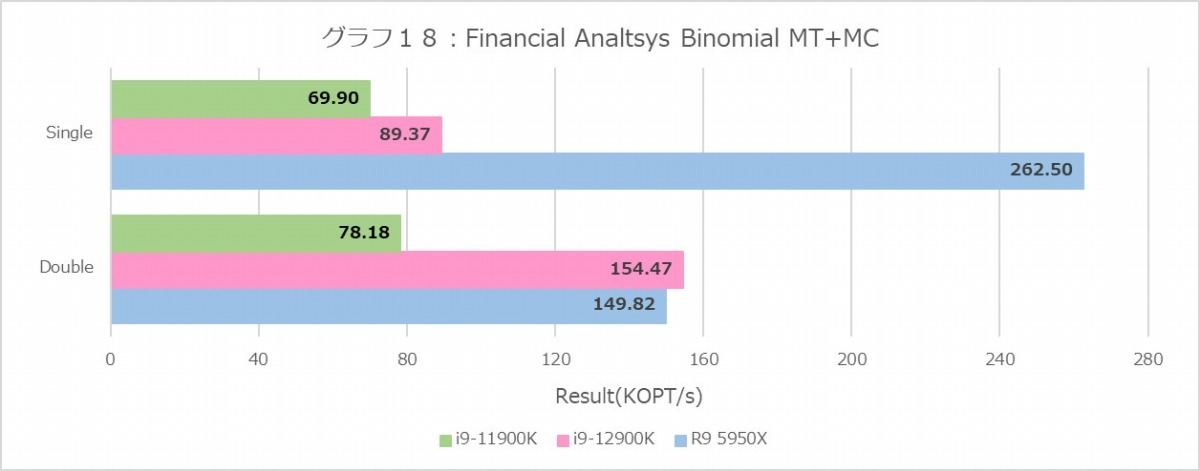
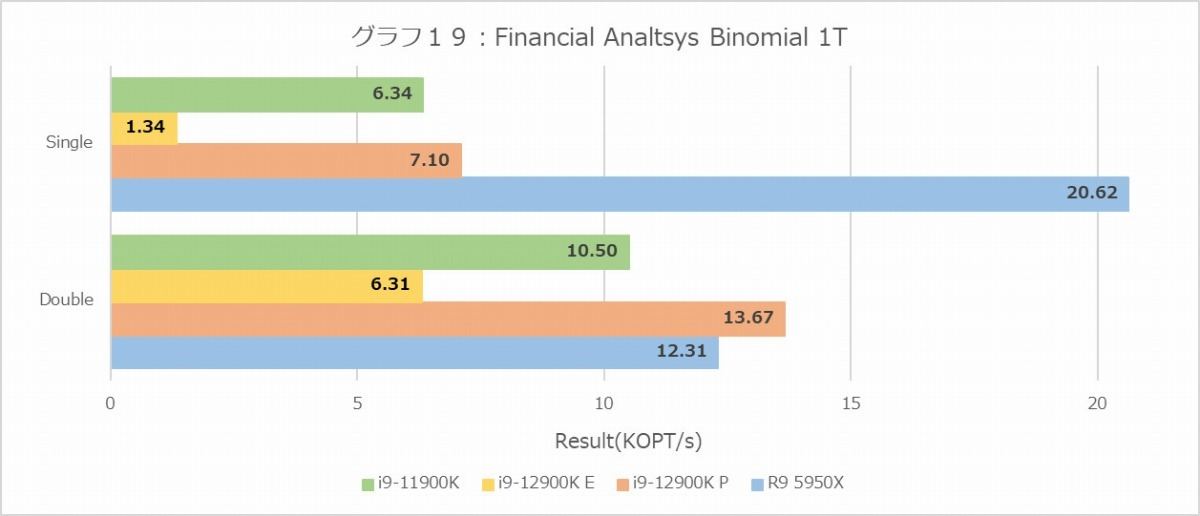
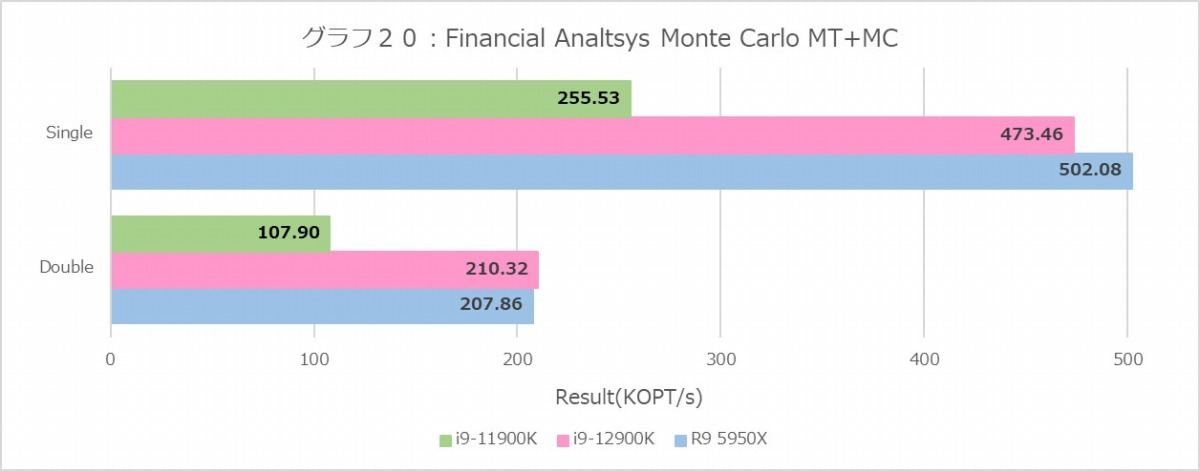
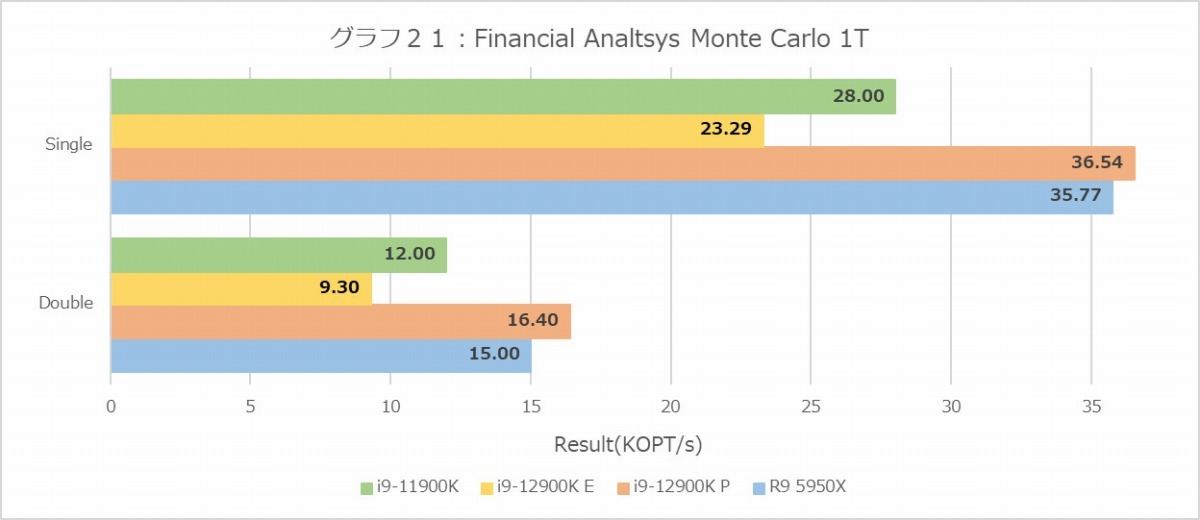
Binomial(グラフ18・19)は、ことSingle FloatだとRyzen 9 5950Xが飛びぬけており、ところがDouble Floatだと拮抗するという構図がMT+MCと1Tの両方で再現しているのは面白い。あとIntel系は、これはBlack-Scholesも同じだがDouble FloatがSingle Floatより高速というのも謎である。これに比べるとMonte Carlo(グラフ20・21)はまだ真っ当というべきか。傾向そのものはこれまでとよく似たもので、E-Coreはやはり性能がかなり落ちる事も同じである。
-
グラフ22

-
グラフ23

-
グラフ24

-
グラフ25

-
グラフ26

-
グラフ27

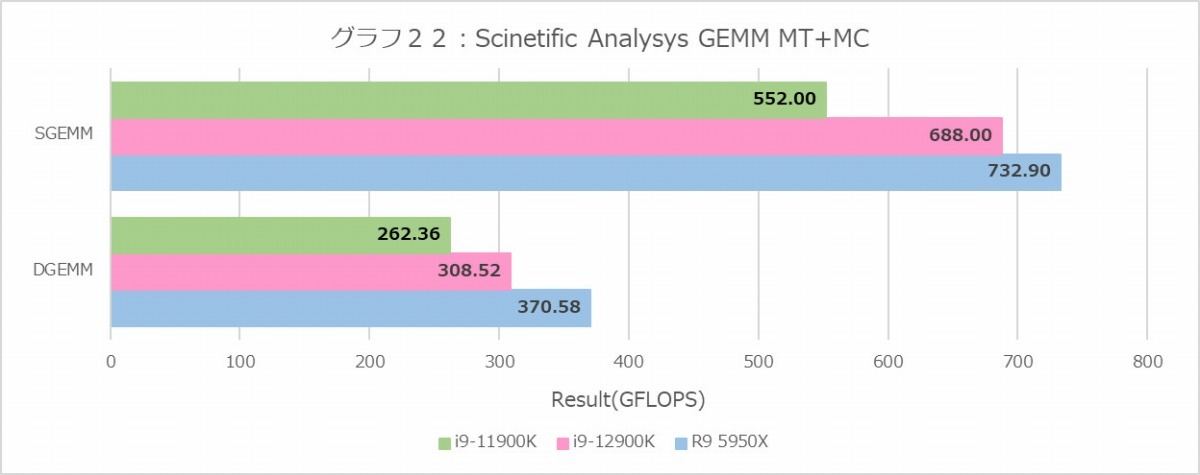
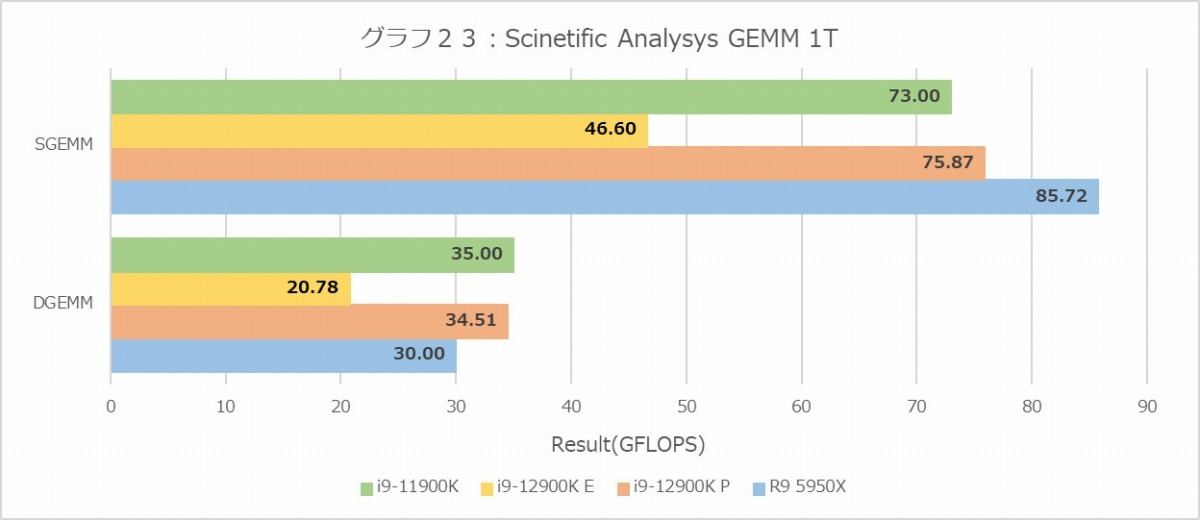
Scientific Analysis(グラフ22~27)であるが、まずGEMM(グラフ22・23)で言うと、MT+MCはRyzen 9 5950Xが有利、1TではDGEMMではP-Coreが健闘するものの、SGEMMではRyzen 9 5950Xがちょっと優勢というあたり。E-Coreの性能はP-Coreのざっくり半分程度なので、Core i9-12900K全体でもRyzen 9 5950Xに敵わないのはまぁ順当である。
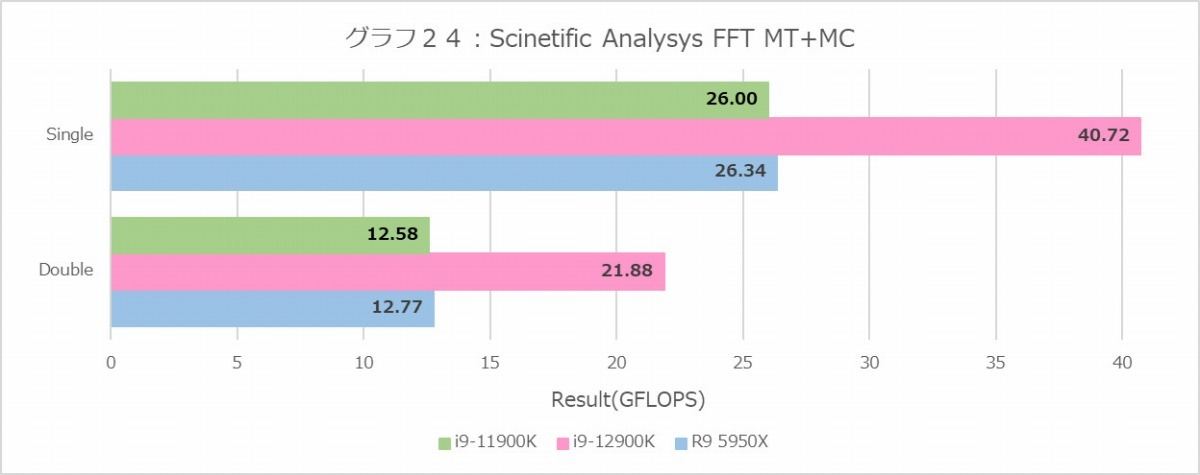
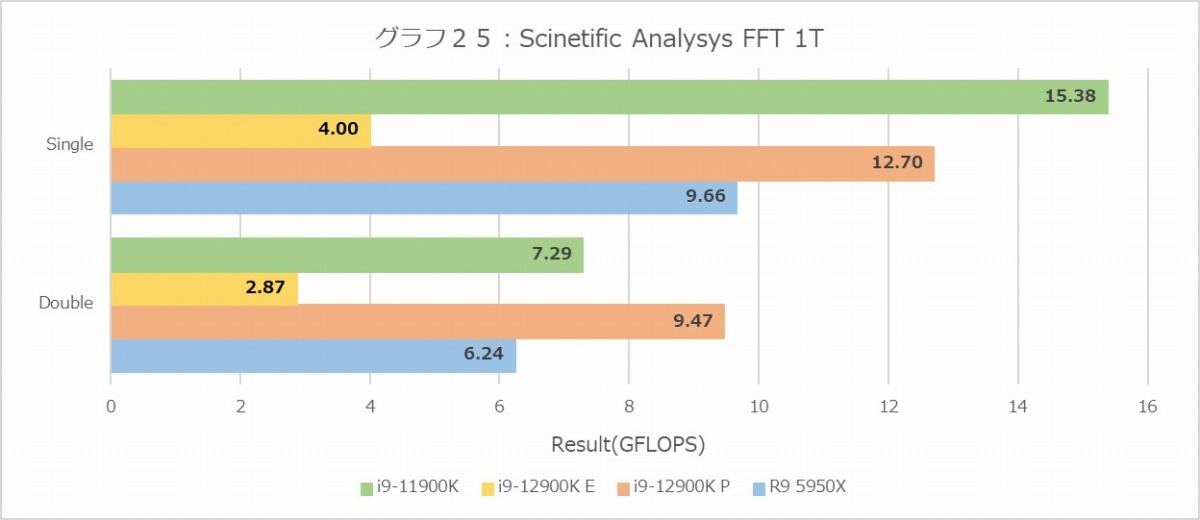
逆にFFT(グラフ24・25)で異様にCore i9-12900Kの性能が高いのは、主にメモリアクセスの帯域と考えられる。テストはSingle Floatで64MB、Double Floatで32MBのデータに対して行われる関係で、理論上はDouble FloatならばRyzen 9 5950XのL3にすっぽり入る筈だが、これを入れると他のものが全部入らなくなるわけで、実際にはそこまででFFTのデータを格納しきれておらず、足りない分は当然メモリアクセスになる。これはL3が30MBのCore i9-12900Kも事情は同じだが、そうなるとメモリの帯域差がそのまま結果に反映される格好になると思われる。1Tでもテストデータのサイズは変わらないが、MT+MCの時ほど激しくデータアクセスをするわけではないので、まだキャッシュが効きやすい結果がグラフ25、と考えれば良さそうだ。それにしても相変わらずCore i9-11900Kのスコアが高いのはどういう理由なのか?
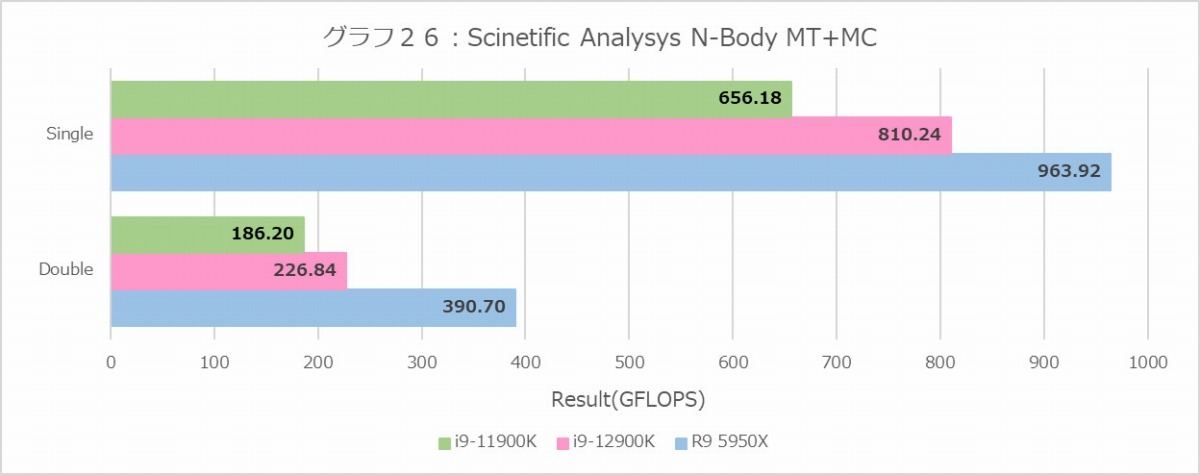
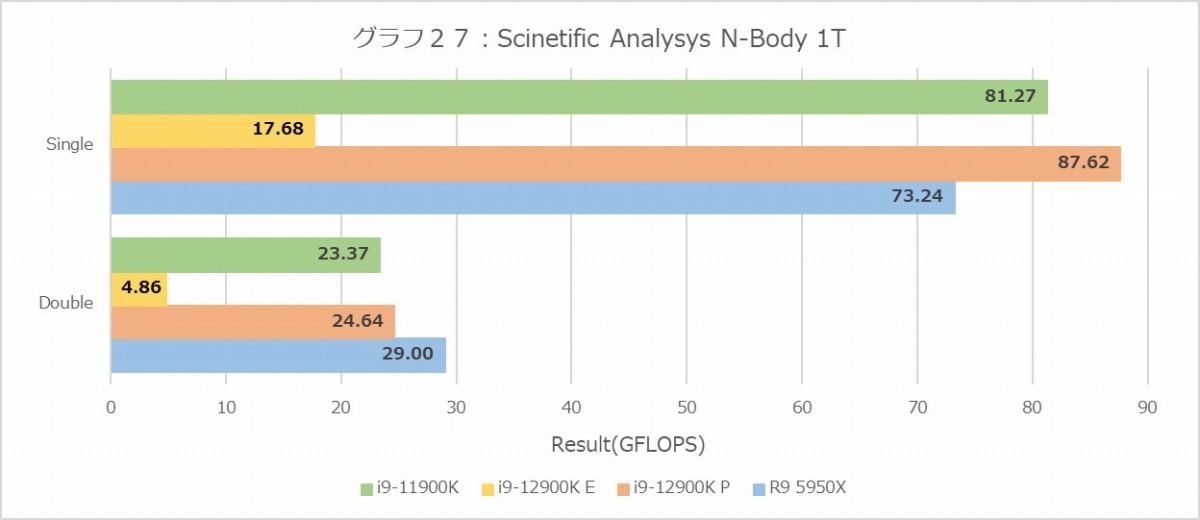
N-Body(グラフ26・27)は、FFTに比べるとまだ順当というか、比較的理解しやすい結果になっている。ちなみにここでのE-CoreとP-Coreの性能比は4倍以上になっており、そういう意味でもE-Coreにはあまりデータ処理系の作業をさせてはいけない、という事が理解できる。
-
グラフ28

-
グラフ29

-
グラフ30

-
グラフ31

-
グラフ32

-
グラフ33

AI/ML(グラフ28~33)は、Intel系の内蔵NPUであるGNAを使うようになっていないため、ちょっと非現実的なテストと言えなくもないのだが、まぁ演算性能の比較と割り切ればこれはこれでアリだろう。ちなみにGNAはIce Lake以降の全てのClient向けCPUに搭載されており、勿論Alder Lakeにも搭載されている。AMDはまだこの手のアクセラレータは特に搭載されていないが、これはこれで時間の問題という気もしなくはない。
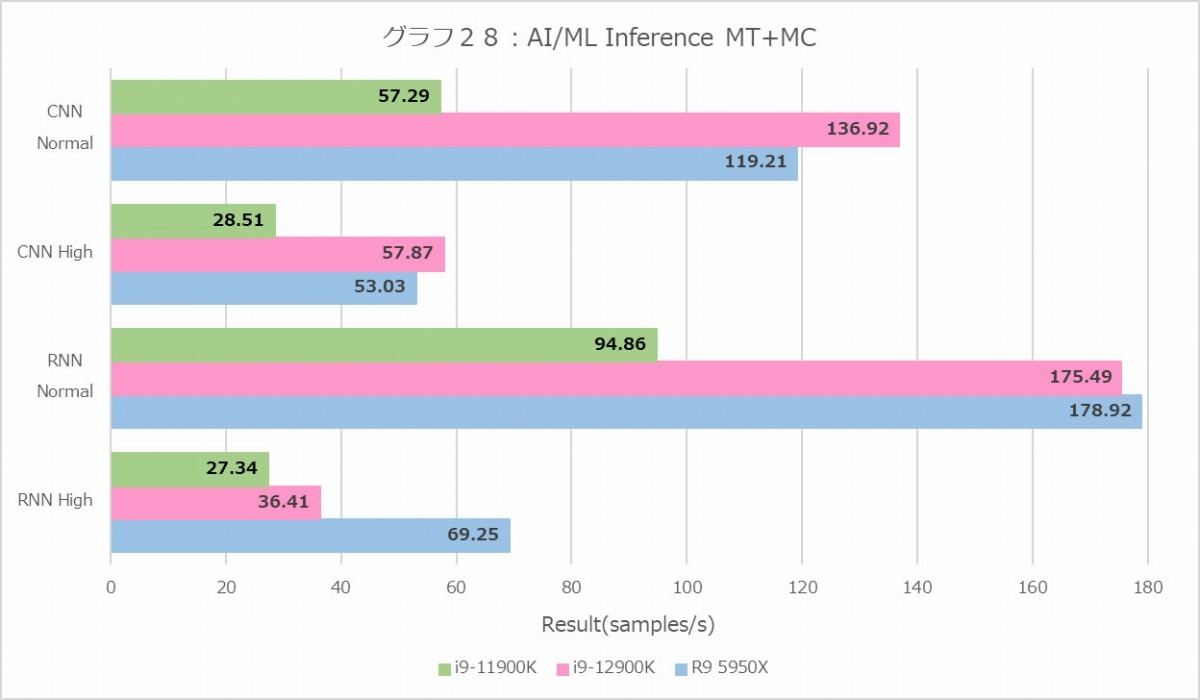
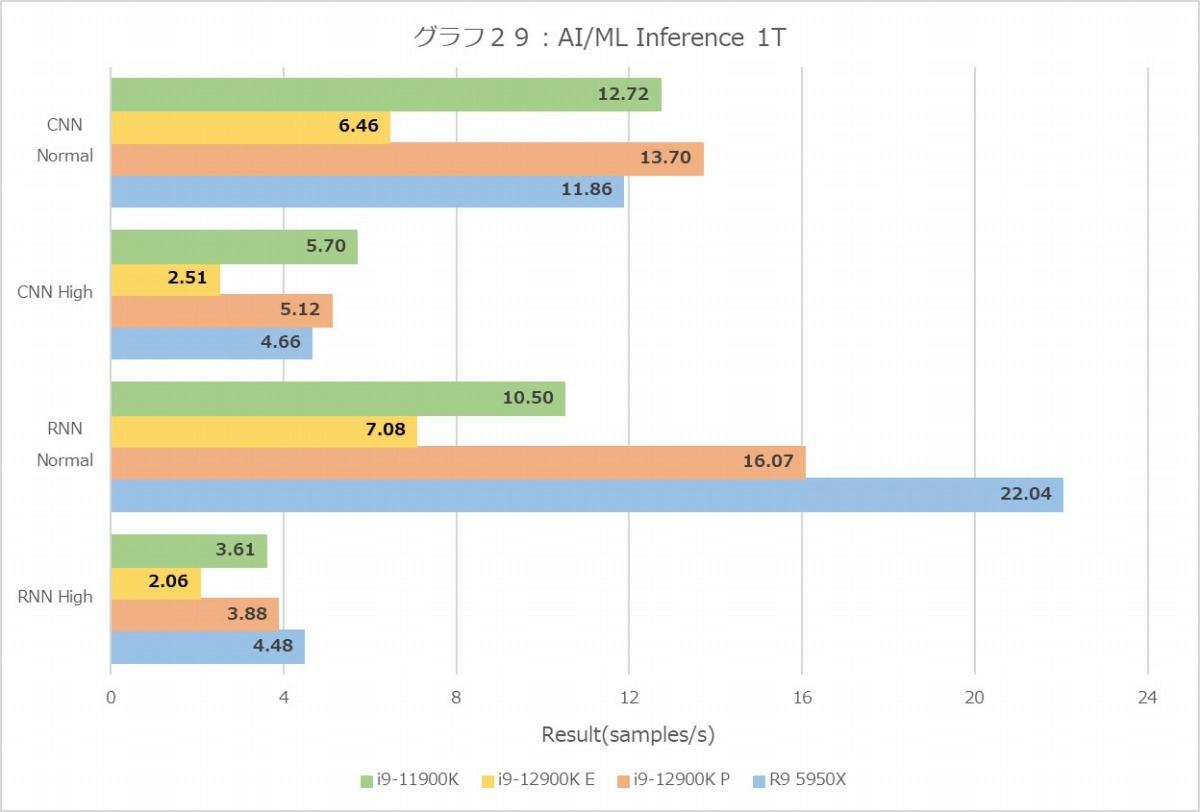
さて、まずInference(グラフ28・29)だが、CNNとRNNで性能が結構変わることが面白い。CNNではCore i9-12900K最速だが、RNNではRyzen 9 5950Xが最速である。これはNormal/High Precisionの両方で共通であり、1Tの場合でもこの傾向がはっきり示されているのはちょっと珍しい。
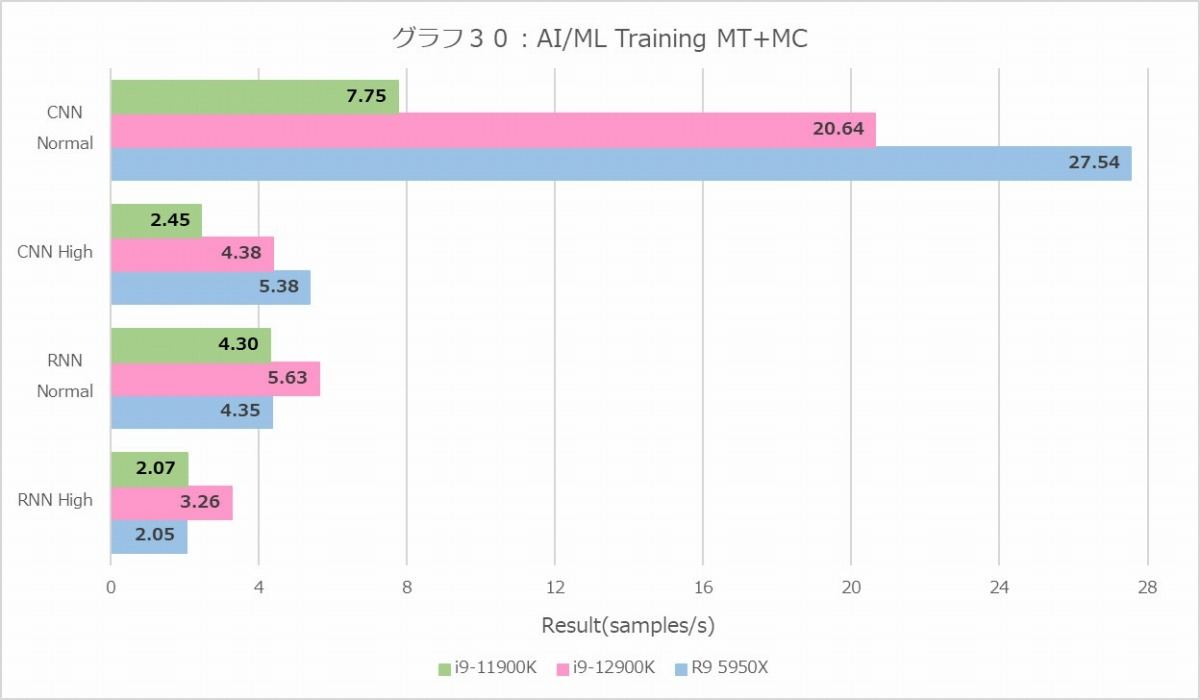
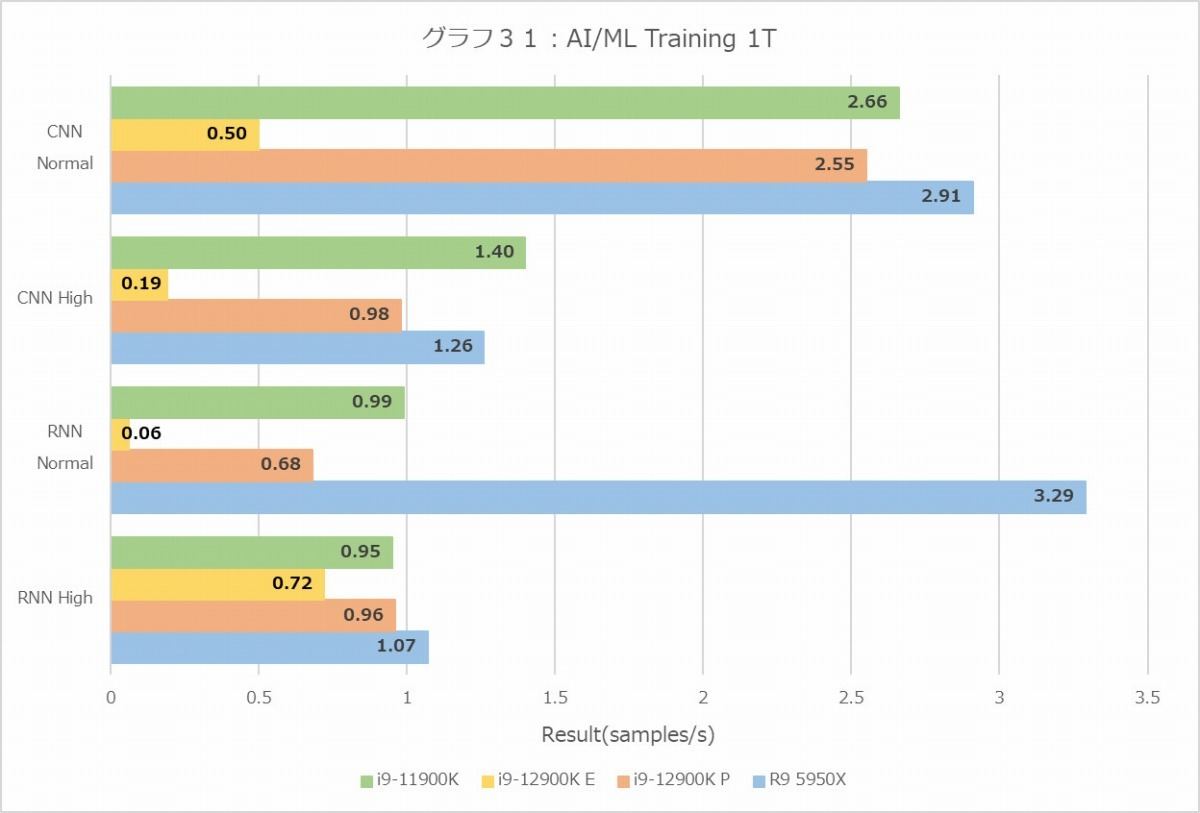
一方Training(グラフ30・31)では、Ryzen 9 5950Xの性能の高さが際立つ格好になっている。Inferenceとは逆にRNNだとMT+MCではCore i9-12900Kにやや引けを取る結果になっているが、1Tではこちらも最速である。逆に言えば1Tで最速なのに、なんでMT+MCでは性能が芳しくないのか? という話だが、これはおそらくはメモリアクセス性能が効いてきているものと思われる。Trainingの場合、Inferenceよりもはるかにメモリうを必要とし、全Threadをフルに動かすとL3キャッシュ程度では収まらないと思われるためだ。そう考えると、特にRNNでCore i9-11900KとRyzen 9 5950Xのスコアが同程度なのが腑に落ちる(どちらもDDR4-3200)。
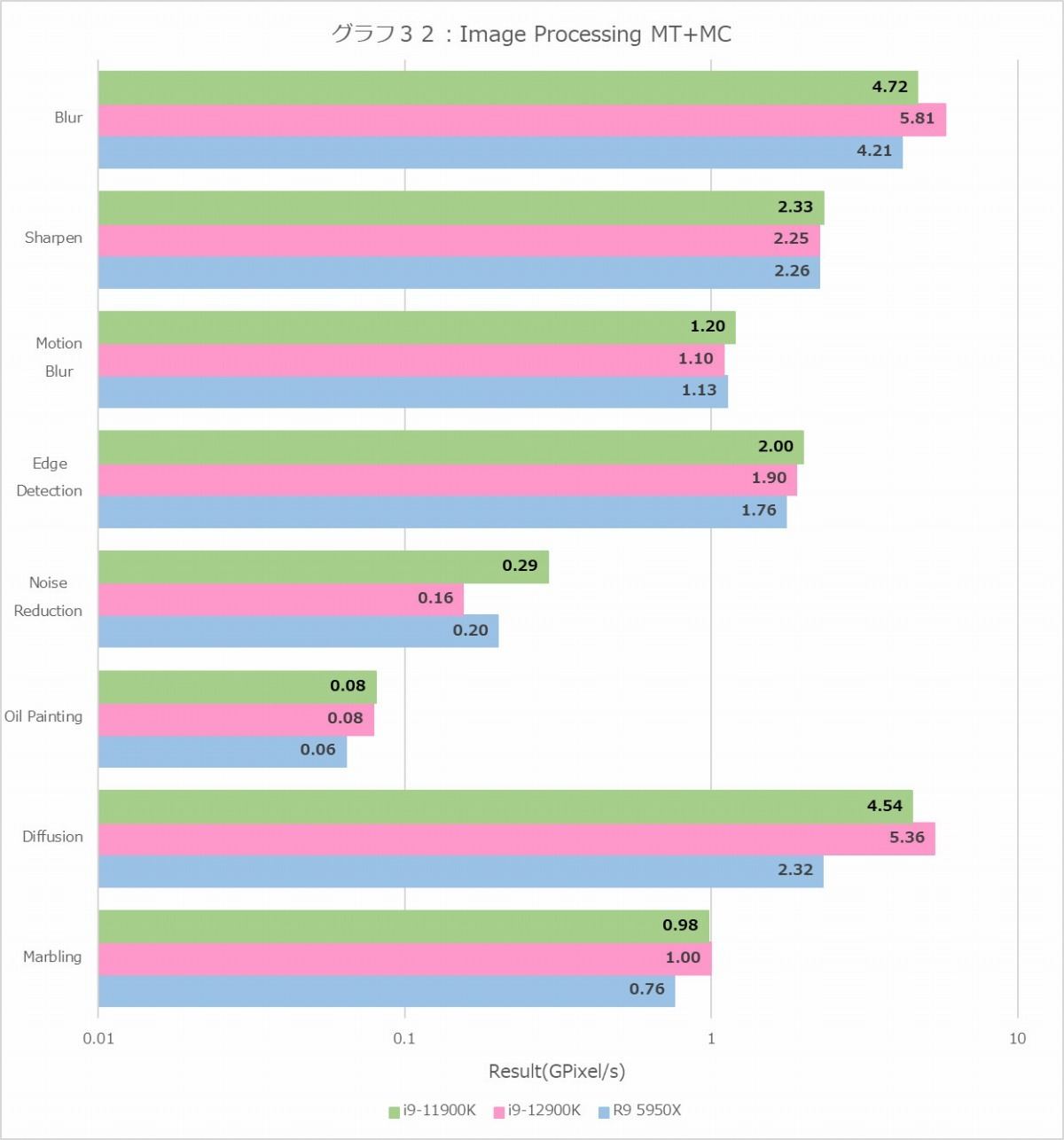
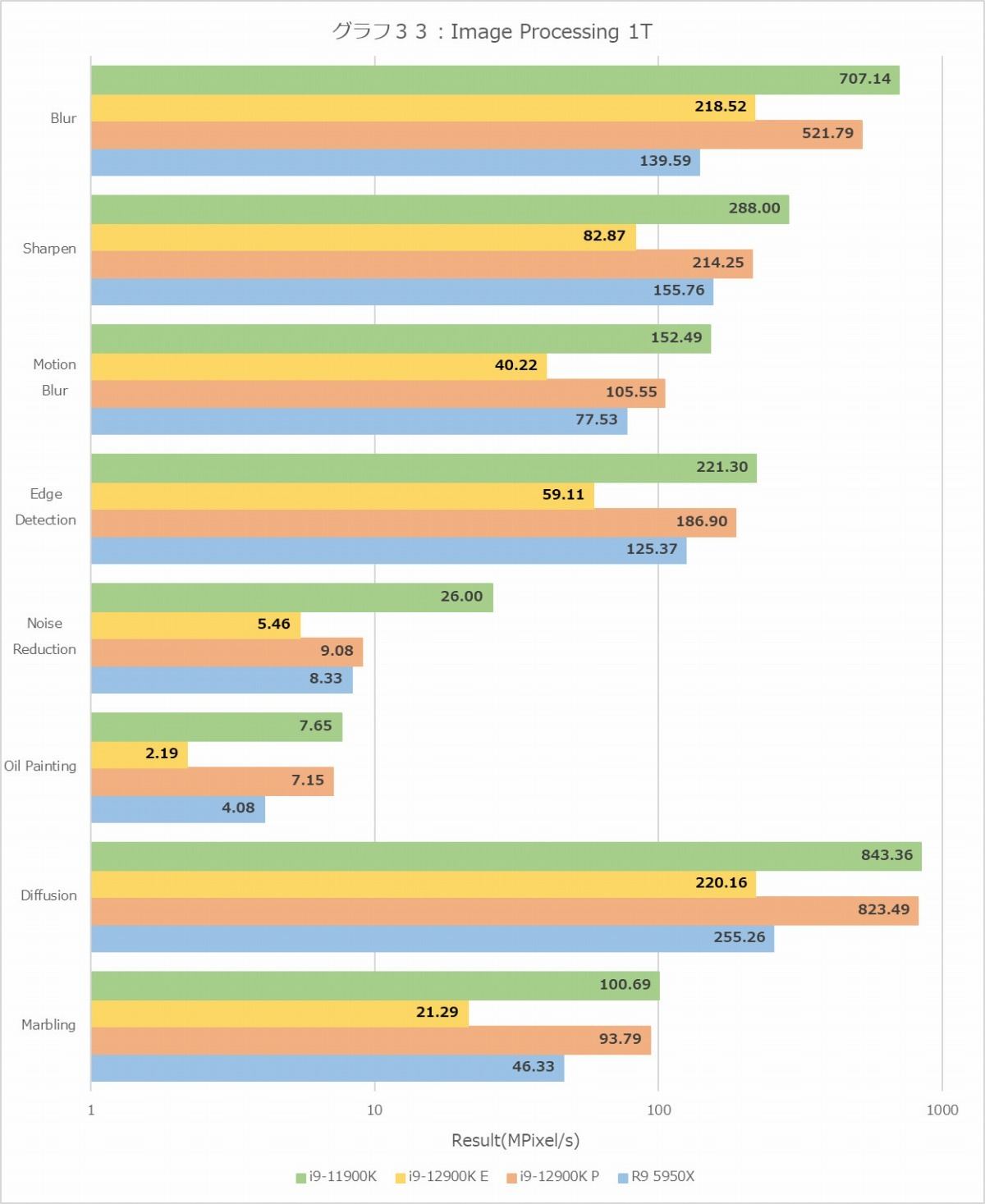
性能比較の最後はImage Processing(グラフ32・33)である。MT+MC(グラフ32)で言えば、勿論行う処理によって多少凸凹はあるが、概してCore i9-12900Kが高い性能を出している。ただ1T(グラフ33)を見ると、P-Coreの性能はすべてのケースでCore i9-11900K以下、というあたりはどういう理由なのか、もう少し分析をしたいところである。E-Coreは? というと、例えばNoise ReductionだとP-Coreの半分強なのに対し、DiffusionとかMotion Blurだと1/4程度という具合に性能のばらつきがかなり大きいのも特徴的である。E-CoreはSkylakeよりも効率が良いという話であったが、効率はともかくとして絶対性能という意味ではSkylakeにはちょっと遠いんじゃないか? と思わせる結果であった。
-
グラフ34

-
グラフ35

-
グラフ36

-
グラフ37

-
グラフ38

-
グラフ39

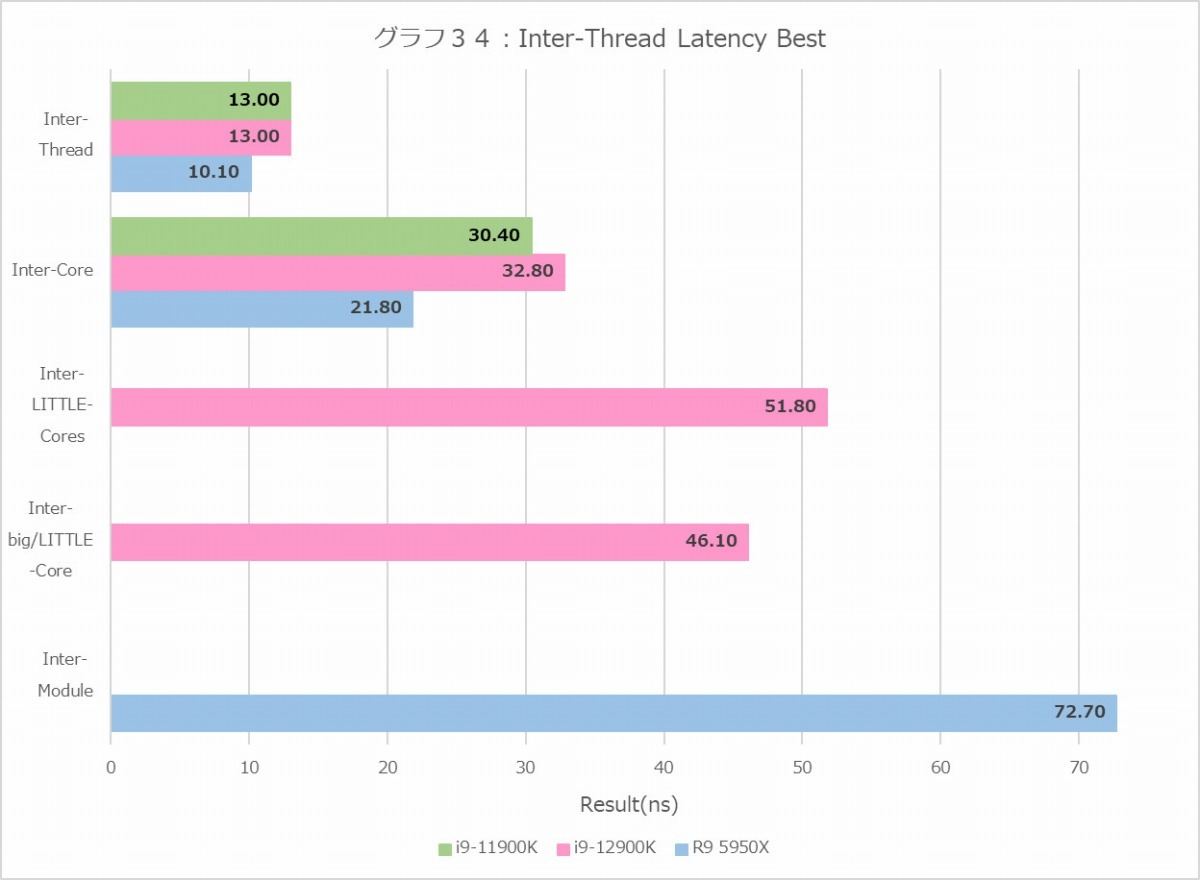
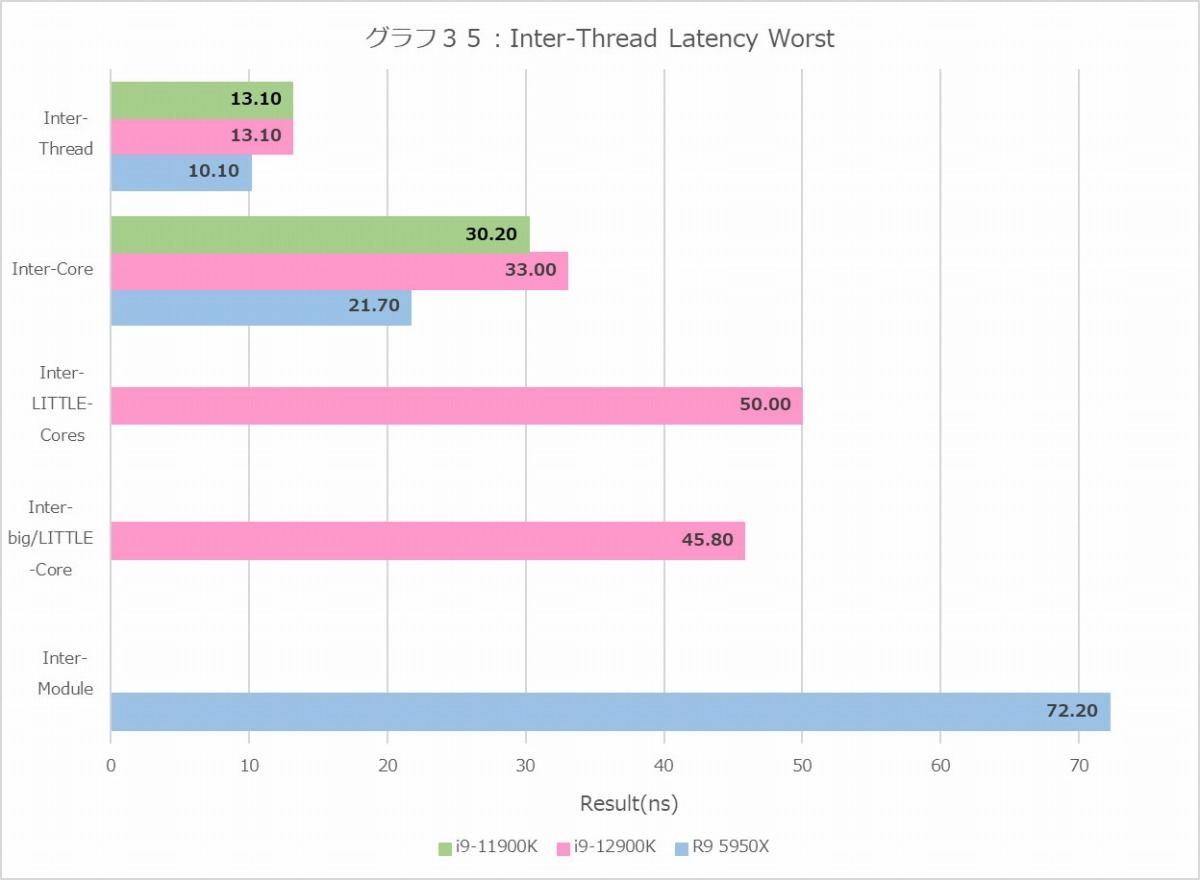
次はInter-Thread Efficiency(グラフ34~39)である。まずグラフ34・35がLatencyの平均値である。Inter-Threadに関して言えばBest/Worst共にCore i9-12900KはCore i9-11900Kと同程度で、Ryzen 9 5950Xよりは3ns程度(ということは、10cycle前後?)遅い結果になっている。そしてこの段階ではE-CoreとP-Coreの間に差は見られない。面白いのはInter-Coreである。Core i9-12900KはP-Core同士がここに出てくるが、これも32.8~33nsとCore i9-11900Kの30ns台よりやや余分に要しているし、Ryzen 9 5950Xの21.7~21.8nsと比較しても結構遅い。そしてP-CoreとE-Coreの通信だと46ns前後、E-Core同士だと50~51.8nsと更に遅くなることだ。E-Coreは4コアづつのクラスタになった形で配されるので、これを跨ぐ際にLatencyが余分にかかるのかもしれない。Inter-ModuleはRyzen 9 5950Xだけで、これはもう2つのダイの間の通信だから、一番Latencyが多いのは自明である。
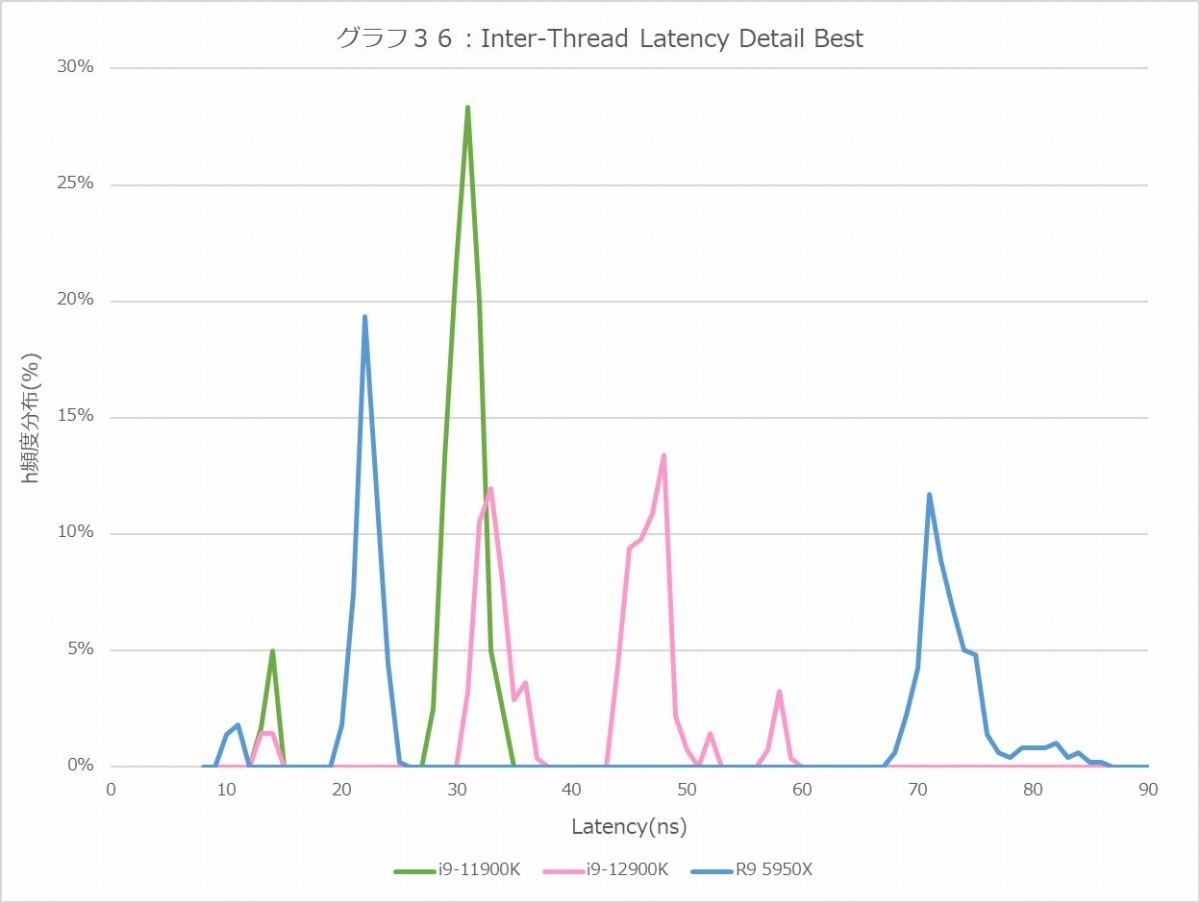
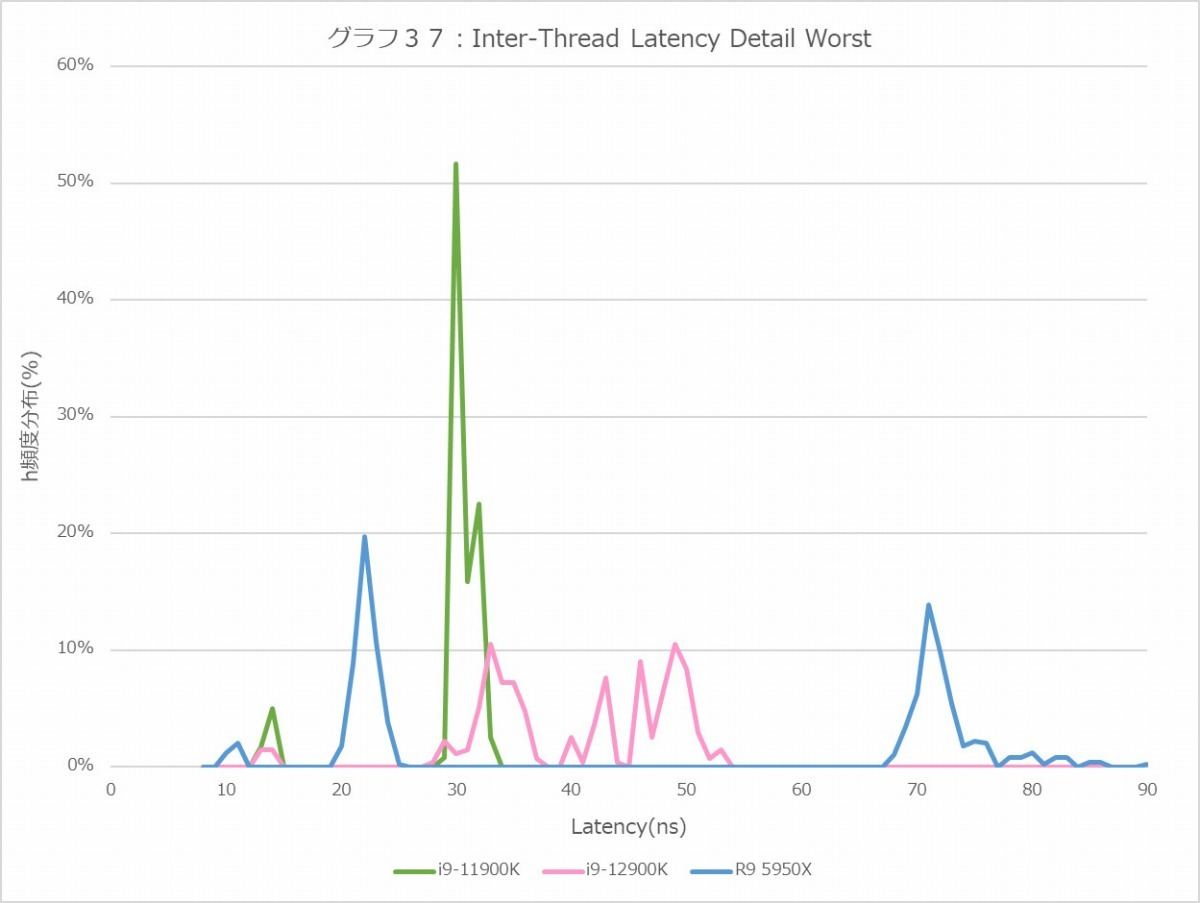
ただそのLatencyについて頻度分布(グラフ36・37)を見ると、Core i9-12900Kでは特にInter-Core Latencyが結構バラつきが大きい事が見て取れる。勿論バラつきの幅の絶対値で言えばRyzen 9 5950XのInter-Moduleの方が大きいのだが、こちらはOff-Chipで、しかも2 Pass(CCD #1→IOD→CCD #2)になることを考えれば納得できるが、逆に物理的には1ダイの中に納まっているにも関わらず、特にP-Core/E-CoreとかE-Core同士で結構遅いあたりはちょっと理由が不明である。あるいはE-CoreではL2が4コア単位で共有になっているあたりが理由だろうか?
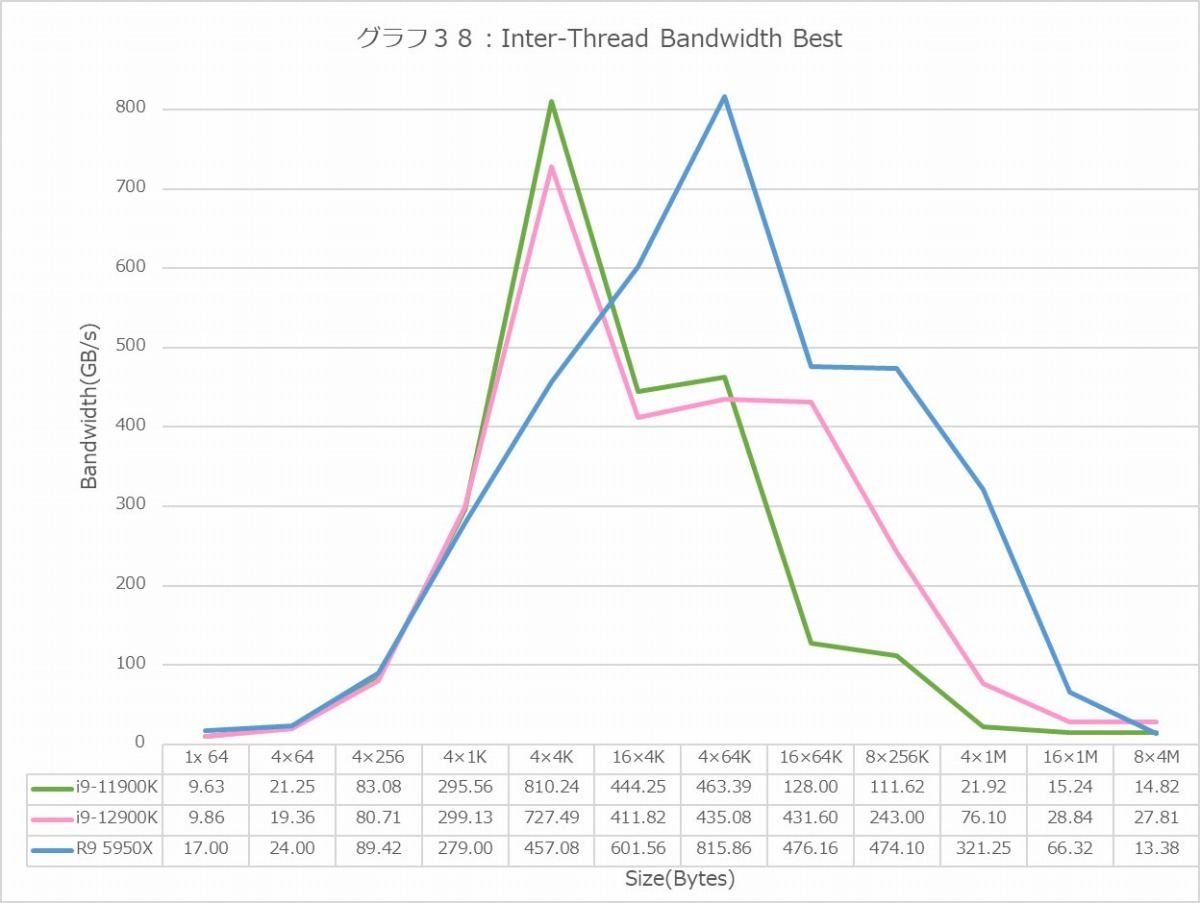
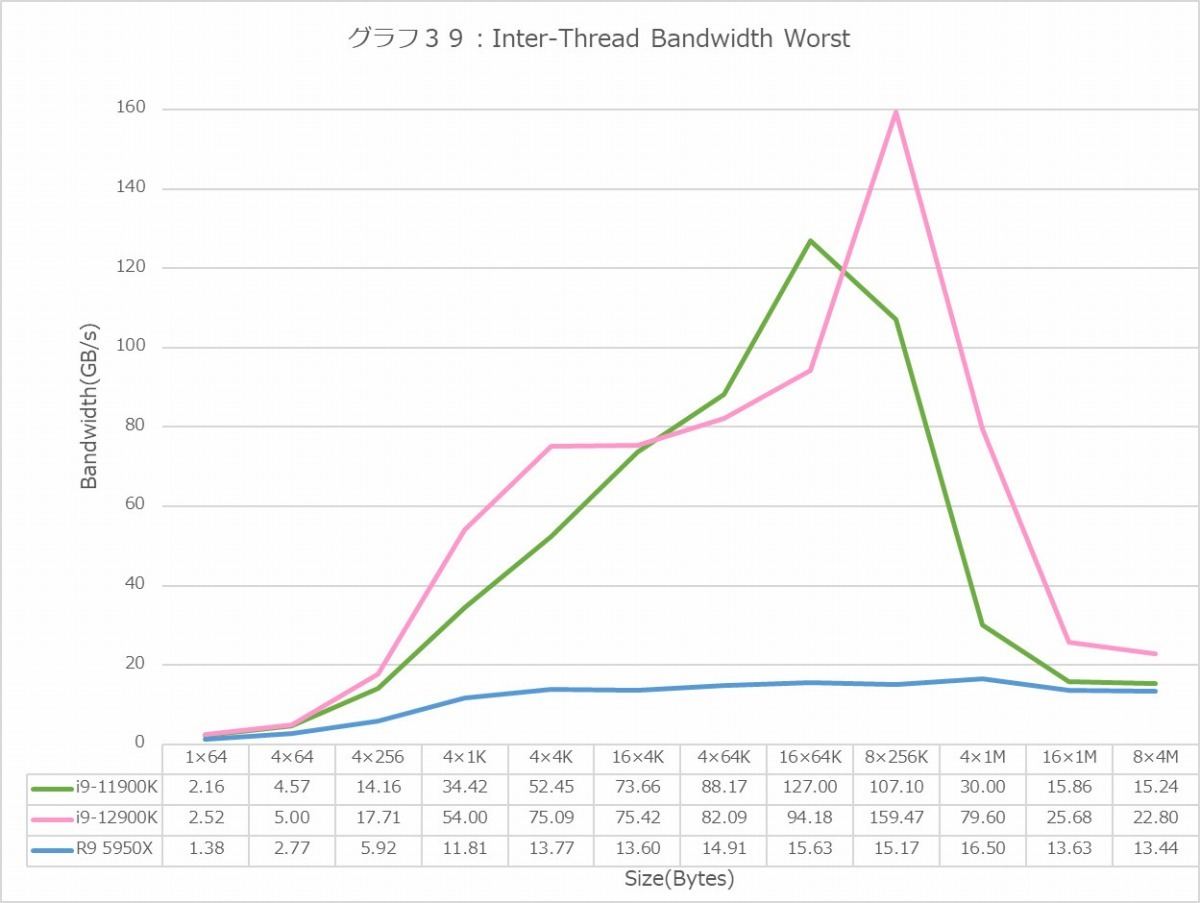
グラフ38・39はInter-Thread Bandwidthである。Inter-ThreadのBestとWorstで、実はLatencyはそれほど差が無いのだが、このBandwidthは大きく影響を受ける。実際結果を見るとその傾向が良く判る。
それはともかくとしてグラフ38を見ると、Intel系は16KBあたりがPeak Bandwidth、Ryzen 9 5950Xは256KBあたりがPeak Bandwidthになっているのは従来から同じであるが、改めてそのピークを見るとCore i9-12900KよりCore i9-11900Kの方が僅かながら上回っているあたりは、むしろこれE-Coreが足を引っ張っている可能性がありそうだ。
グラフ39だとRyzen 9 5950Xは全てInter-Moduleでの帯域となるので、常時15GB/sec弱という帯域に落ち込むのはまぁ致し方ないところ。それはともかく、ここではグラフ32と逆にCore i9-12900Kの方がやや帯域を稼げているが、これはコアの数そのものが増えているから、その分が上乗せになっている(要するにE-Coreの分)という事だと考えれば良いかと思う。
-
グラフ40

-
グラフ41

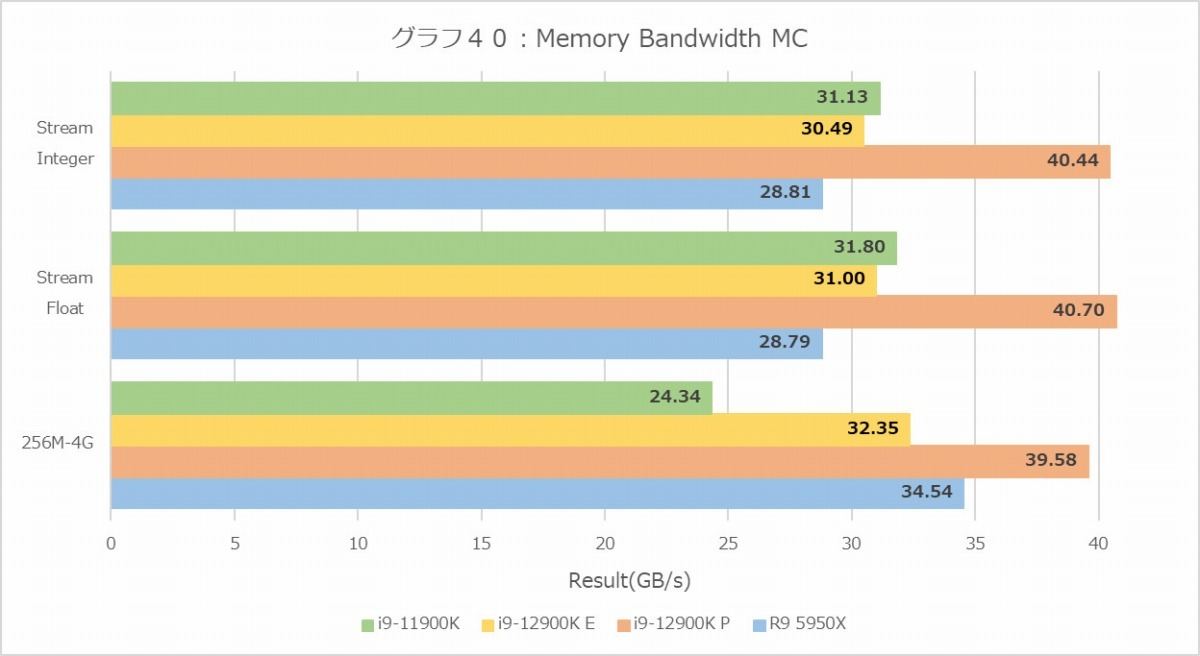
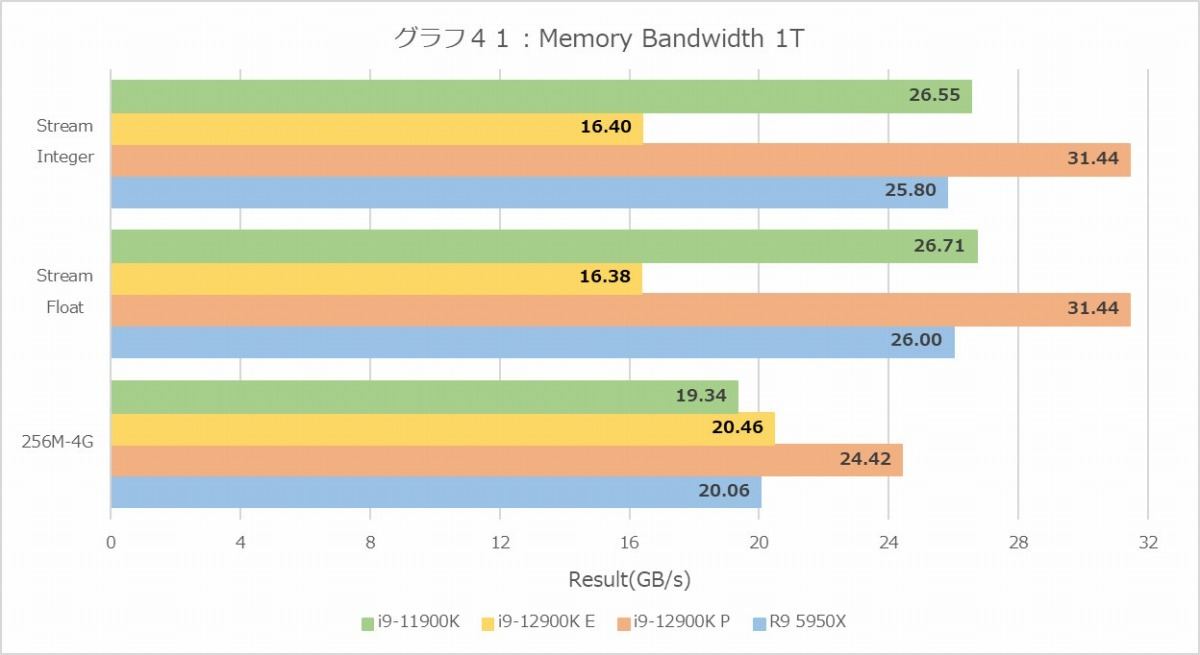
さて、ここからは前回のSandraではテストできなかったメモリ回りである。まず最初はMemory Bandwidth(グラフ40・41)。こちらではMT+MCは無くなっており、MC及び1Tの結果になっている。まずMC(グラフ40)で見ると、やはりStreamや256MB~4GBのMemory Bandwidth AverageでCore i9-12900Kは40GB/secを叩き出し、30GB/sec台のCore i9-11900KやRyzen 9 5950Xを大きく引き離している。もっともよく見ると、P-Coreは確かに飛びぬけて性能が高いが、E-Coreはそれほどでもないというか、Core i9-11900KやRyzen 9 5950Xと同程度である。
考えられる要因2つあって、一つはLoad/Storeユニットの性能の差である。E-CoreはLoad Unit×3、Store Unit×2だが、AVX512を扱う必要が無いから恐らくデータ幅は256bitである。他方P-CoreはLoad Unit×2、Store Unit×2で一見数は少ないように見えるが、AVX512を扱う必要があるから、これもおそらくデータ幅は512bitである。なので、頑張っても768bit/cycleのE-Coreと1024bit/cycleのE-coreでは絶対性能が違うため、E-Coreを使ってもDDR5の帯域を利用しきれない、という話。
もう一つの可能性は、Ring Busに対してのボトルネックである。E-Coreの場合4コアまとめて一つのクラスタになっており、共有L2キャッシュを経由する。なので、E-Coreが8コアフルに動いても、実際には2つの共有L2キャッシュからRing Busへの帯域がメモリリクエストの上限になる。対してP-Coreは、それぞれのコアがRing Busに直接接する形になる。要するにRing BusへのI/F(Ring Stop)の数がボトルネックになるという可能性だ。現時点ではどちらがボトルネックか判らない(両方の可能性もある)が、1T(グラフ41)の場合でもE-Coreの性能はP-Coreの3/4程度、というあたりは前者の影響は間違いなくありそうである。
-
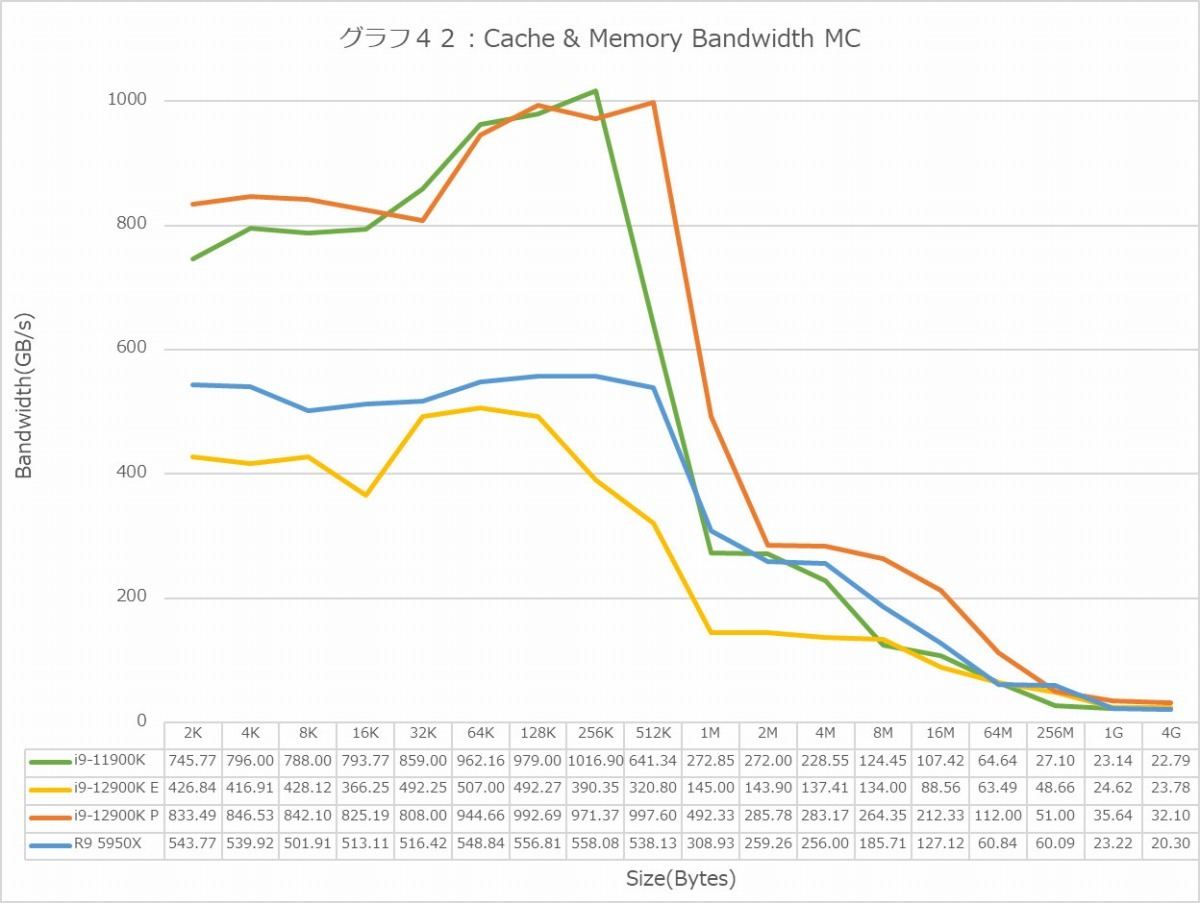
グラフ42

-
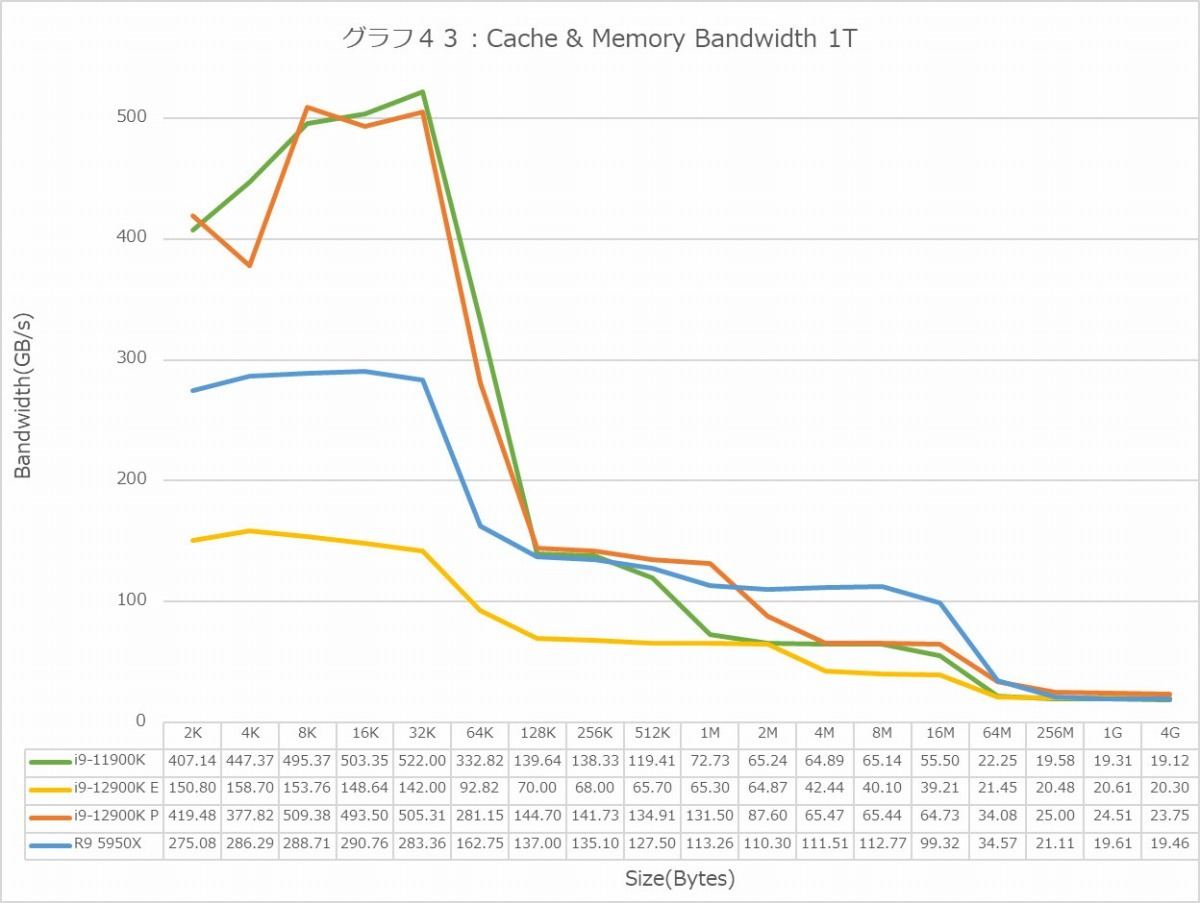
グラフ43

加えて言えば、E-Coreはキャッシュの帯域そのものも低く抑えられているようだ。グラフ42・43がCache & Memory Bandwidthであるが、ちょっと先に1T(グラフ43)を見ると、L1 D-Cacheの帯域は概ね160GB/sec弱。先に書いたようにAVX512は必要ないのでAVX2向けに32Bytes/cycleの帯域がL1 D-Cacheに用意されていると考えるべきで、仮にE-Coreの最大動作周波数である3.9GHzで動いているとすると理論上は125GB/sec程度になるが、これが160GB/secということは、ピークでは5GHz駆動ということになるが、これはCore i9-12900Kの仕様と合致しない。E-CoreのMax Turboは3.9GHzなので、ということはL1 D-Cacheの帯域は40Bytes/cycleということになるが、これもちょっと信じがたい。実際には32Bytes/cycleで3.9GHz駆動なのにも関わらず、何かベンチマークがおかしくて最大で160GB/sec出る事になってしまった、という方がまだ信じやすいのだが、このあたりを検証する方法が無いのでここでは措いておく。ついでに言えば、L2は概ね68~70GB/sec程度。ということは、L1とL2は16Bytes前後で接続されている模様だ。
さて、これがMCになるとどうなるか、が非常に面白い。グラフ42でL1領域だと最大でも428GB/sec。8コアで、かつ3.9GHz動作だと13.7Bytes/cycle程度。まぁ多少動作周波数は下がって3.3GHz程度だとすれば、16Bytes/cycleということになる。なんで半減してしまったのか? という話だが、複数コアが動く場合はフルにL2が律速段階になってしまっているようだ。どうしてそういう仕組みになっているのか、はいくつか検討したが満足のいく仮説は立てられなかった。そろそろIntelにはAlder Lakeに対応したOptimization Reference Manualをリリースしてほしいところだ(現状は2021年6月付のみで、Ice Lakeまでの対応となっている)。
ちなみにP-Coreの方はほぼCore i9-11900Kと同じで、強いて言えばL2が512KB→1.25MBに大幅に増量されたことで、ピークがややずれた(512KB→1MB)ほか、L3も30MBに増量した事で、16MB/64MBにおけるBandwidthも多少上乗せになった程度である。
-
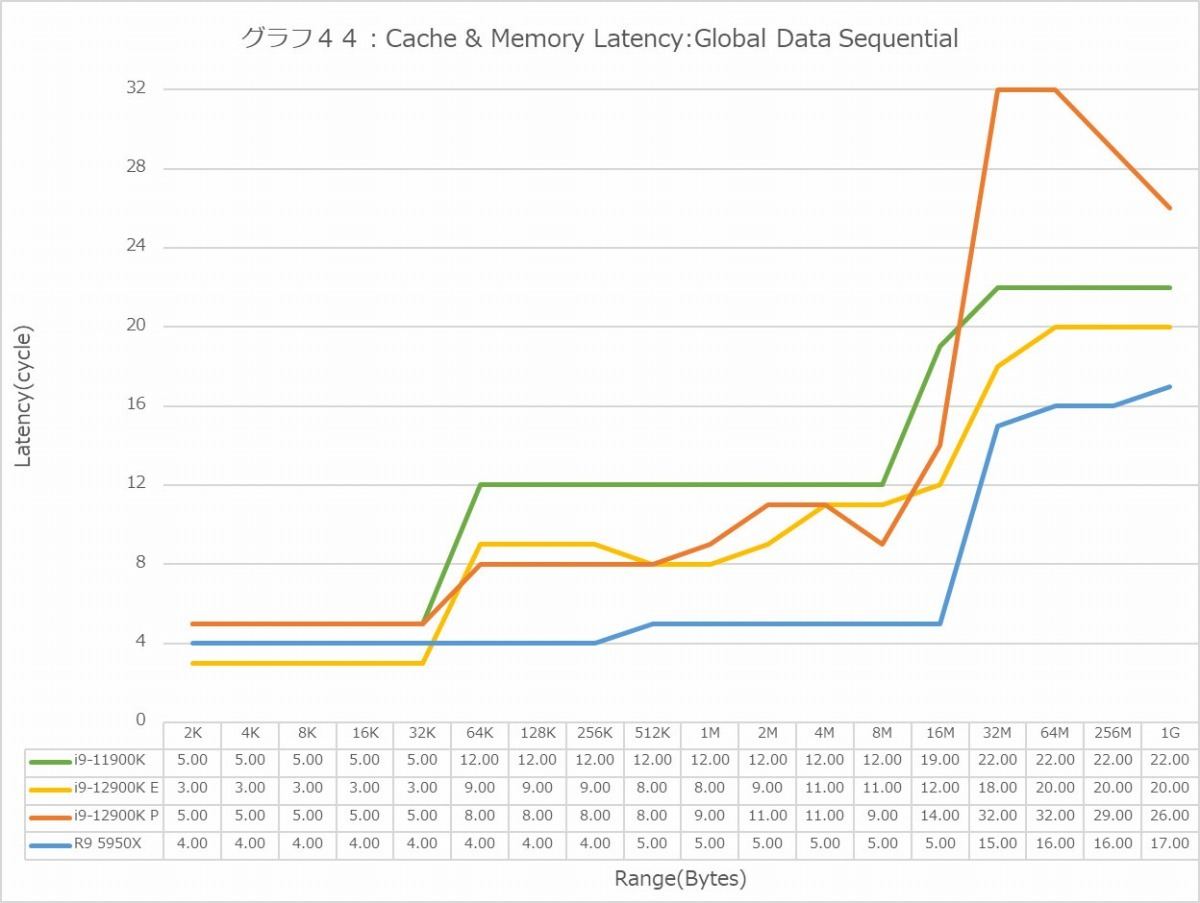
グラフ44

-
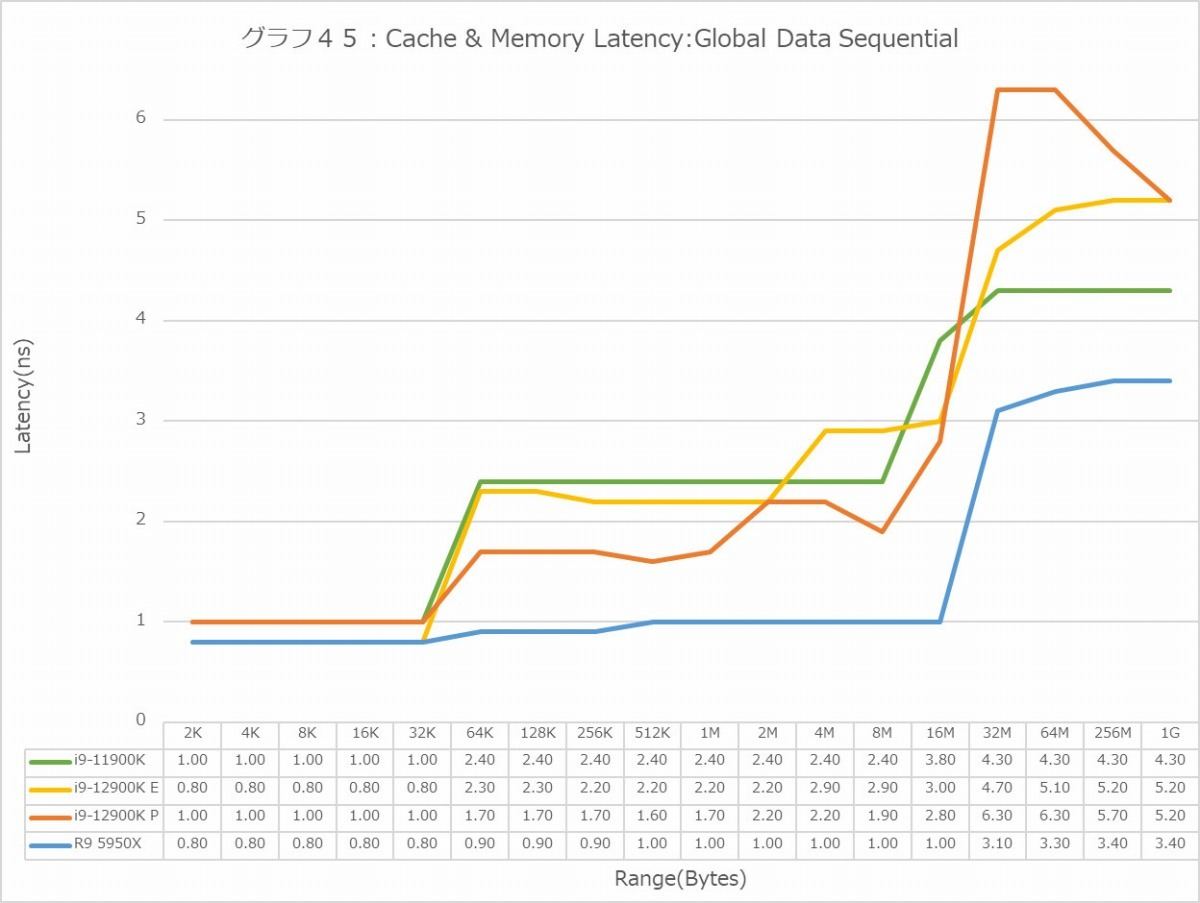
グラフ45

-
グラフ46

-
グラフ47

-
グラフ48

-
グラフ49

-
グラフ50

-
グラフ51

-
グラフ52

-
グラフ53

-
グラフ54

-
グラフ55

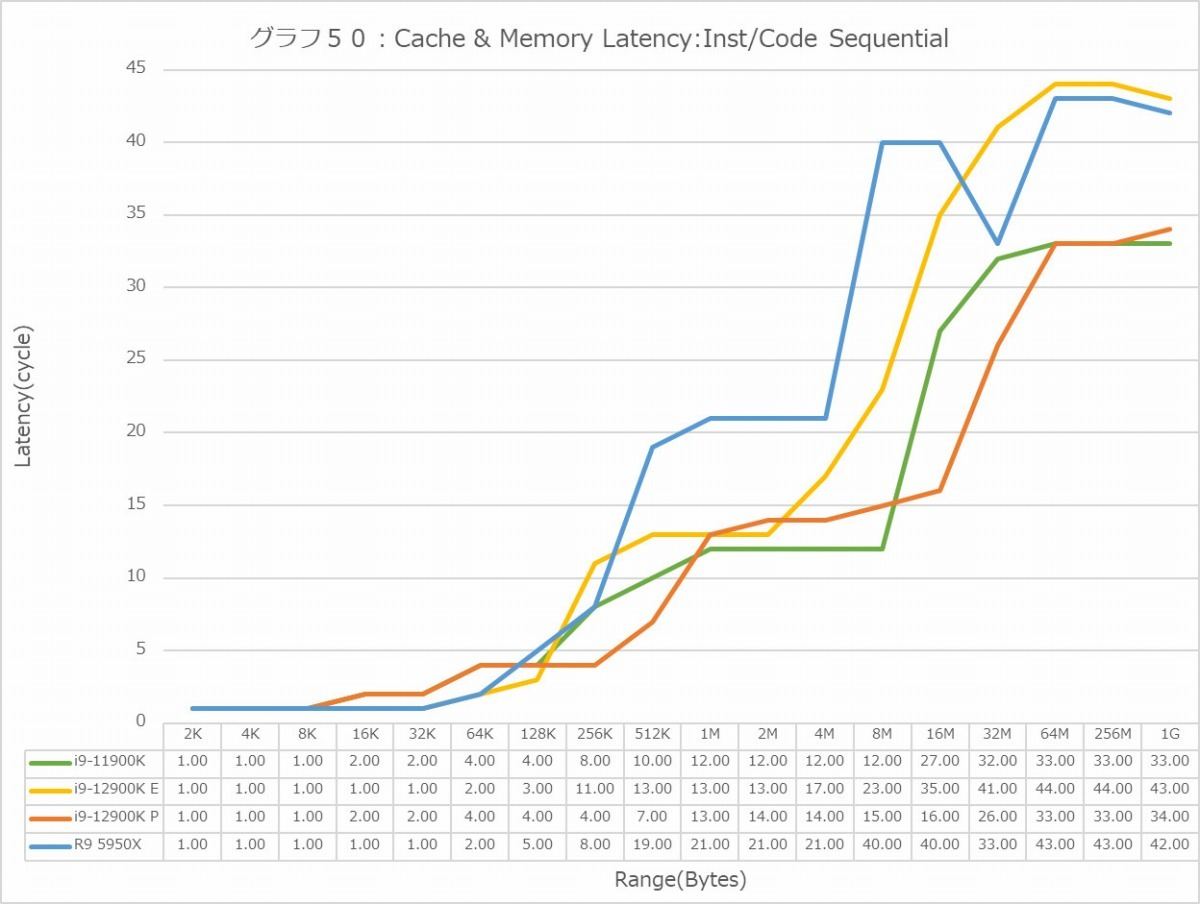
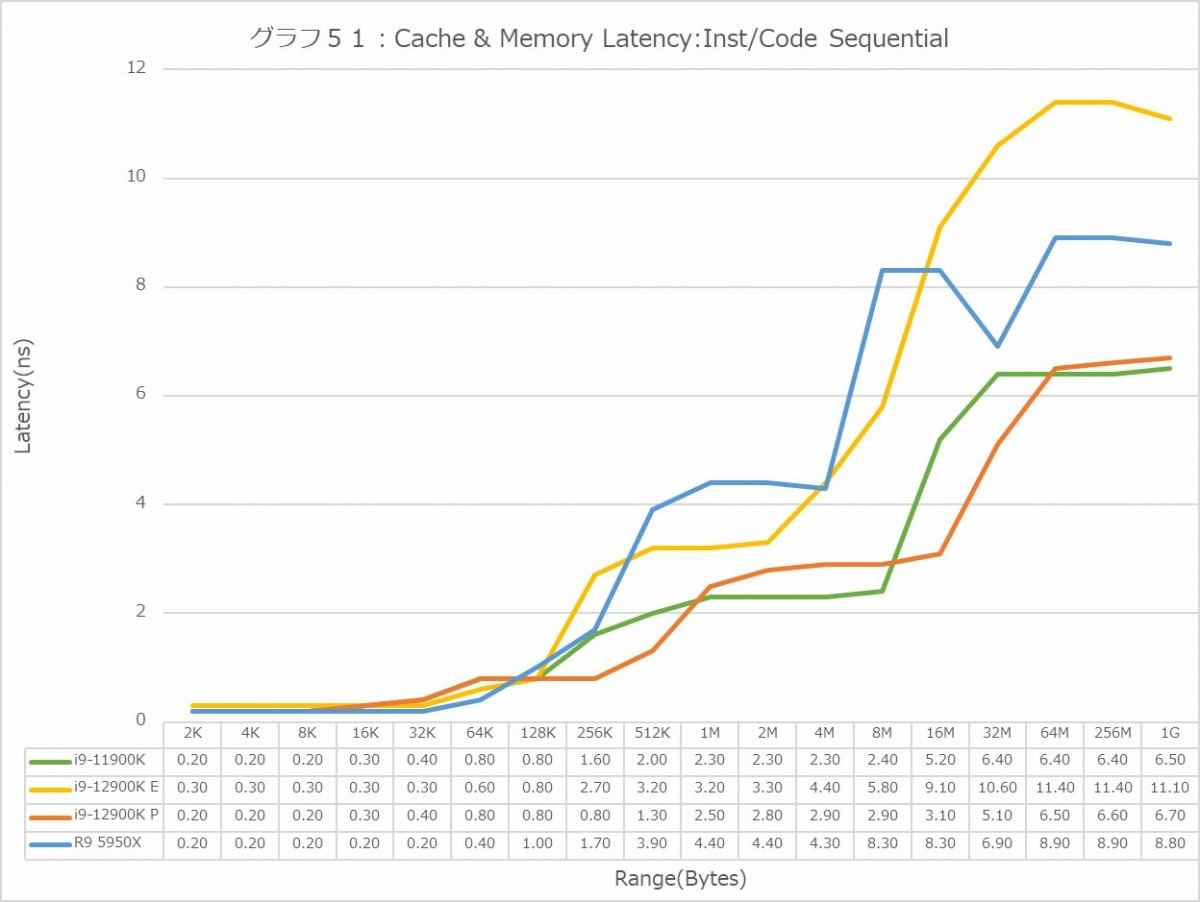
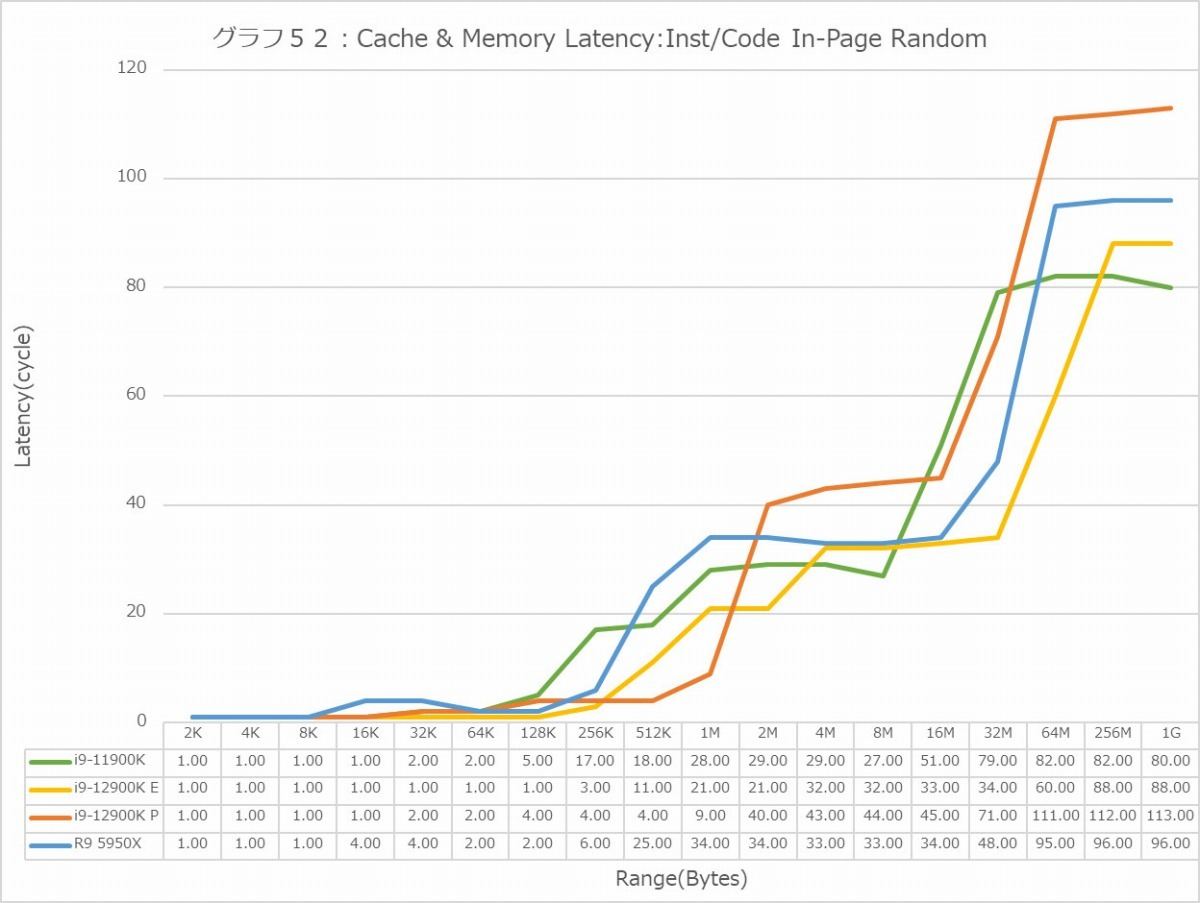
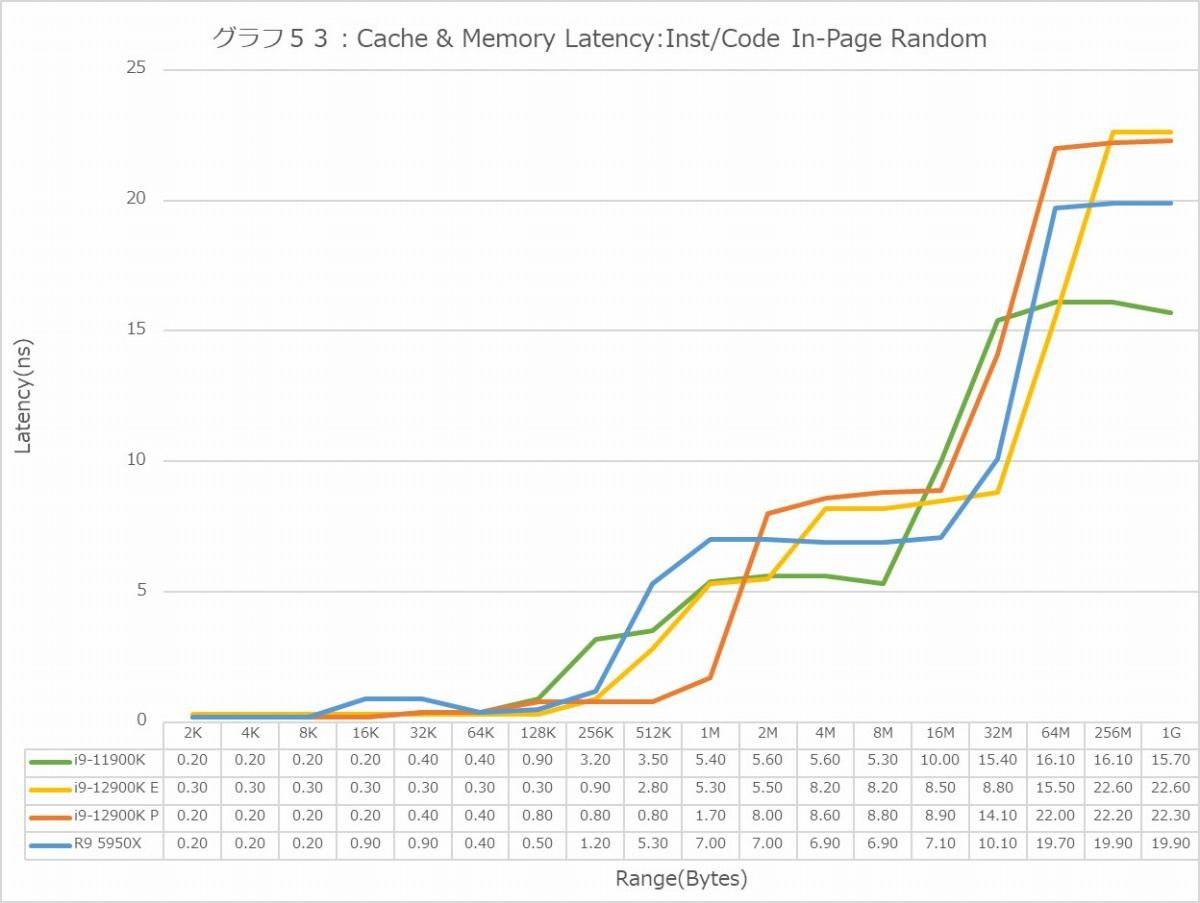
グラフ44~55がLatencyである。Global DataとInst/Code、つまりデータキャッシュと命令キャッシュに対して、Sequential/In-Page Random/Full Randomの3種類のパターンでのアクセスを行った結果である。で、グラフが2つづつあるのは、L3 Hitまでの領域はLatencyをcycle数で判断するのが正確で、L3 MissはMemory Accessとなるのでこちらは実時間(ns)で比較するのが正確だからだ。グラフはcycle数、実時間の順で並べてあるので、最初のグラフはL3まで、その先は次のグラフで判断していただきたい。
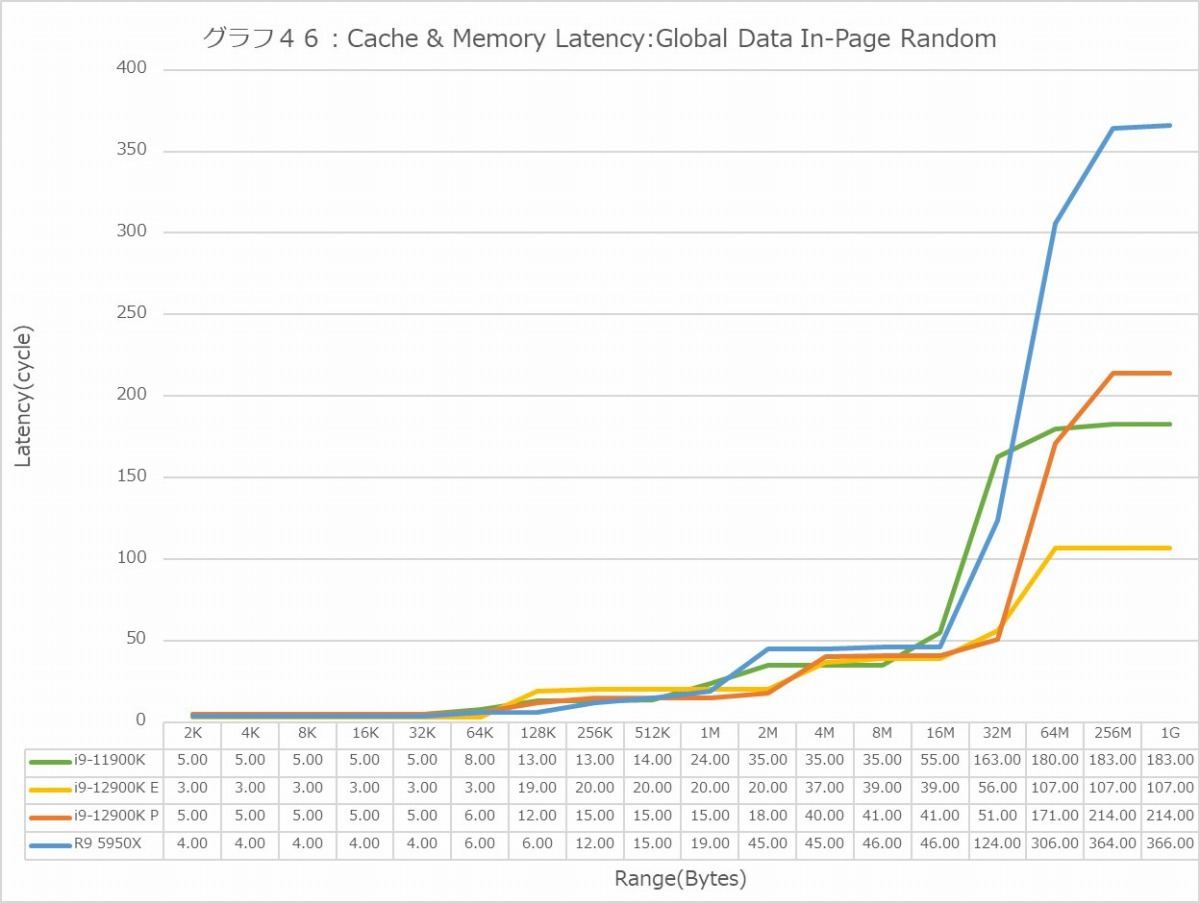
まずはGlobal Data(グラフ44~49)。Sequential(グラフ44)を見ると、L1でE-Coreが3cycleまで下げているのは中々面白い。一方P-Coreは5cycleでCore i9-11900K並み。Ryzen 9 5950Xは4cycleで、丁度中間である。L2になると、P-Coreは容量が増えたにも関わらずLatencyを3~4cycle減らしており、一方E-Coreは共有L2という事もあってかちょっとP-Coreより多めだが、それでも9cycle程度でかなり優秀である。L3は更にLatencyが増え11cycleだが、それでもCore i9-11900Kより1cycle減らしている訳で、全般的にL2/L3キャッシュ周りの低Latency化に注力した感じだ。謎なのは8MBから先。本来P-CoreもE-Coreも同じメモリコントローラ経由でのアクセスだし、実際1Gあたりになるとどちらも5.2nsなのだが、その手前で妙にP-CoreのLatencyが増えているのは不思議である。ただCore i9-11900Kの4.3nsに比べると1nsほどLatencyが増えるのはDDR5に起因するのか、Memory Controllerの作りの問題なのかはこれだけでは断言できない。またSequentialに関して言えば、Ryzen 9 5950Xの優秀さが光る格好で、メモリアクセスも一番Latencyが少ない。
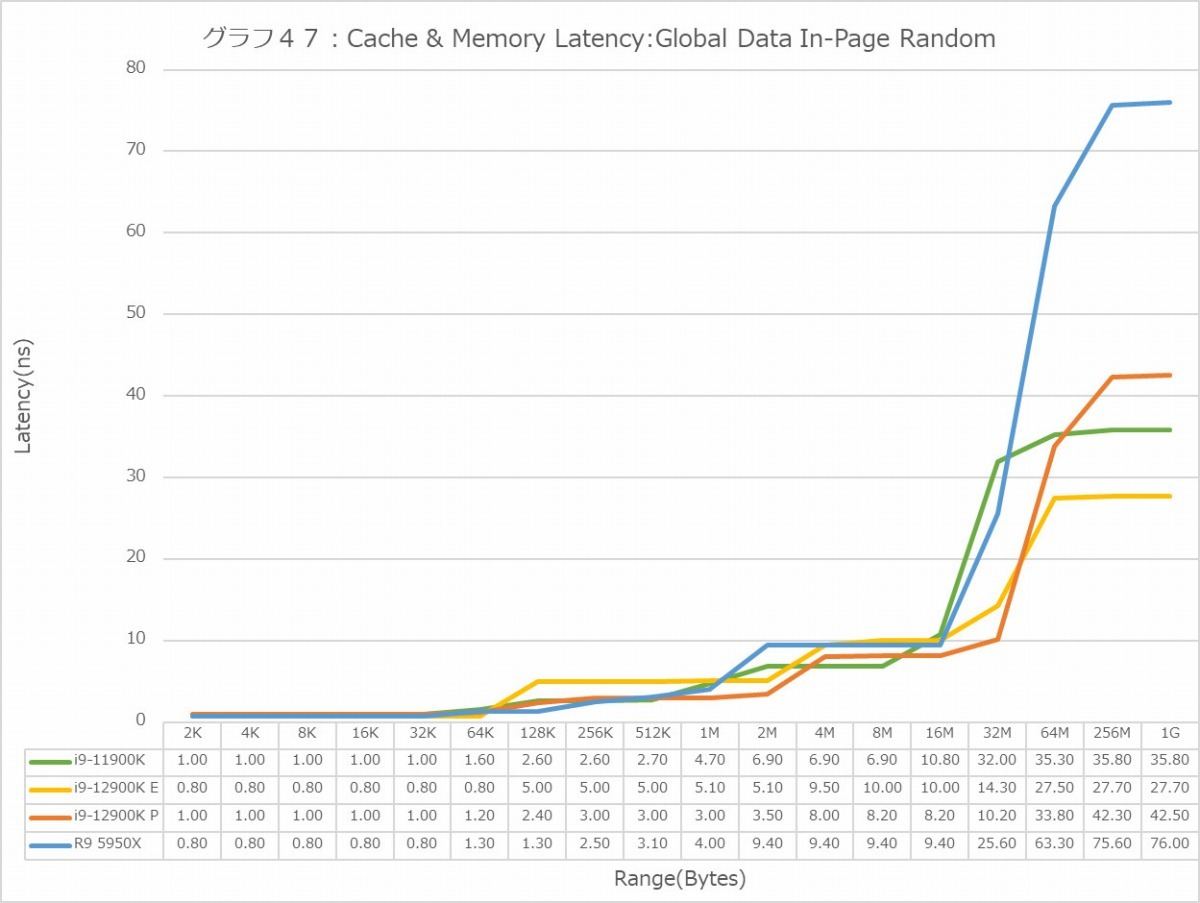
In-Page Random(グラフ46・47)になると、L1は変わらないがL2ではE-Coreが急激にLatencyを増やしているのは、やはり共有L2という構成に起因するものだろうか? ただL3に関しては、むしろE-CoreよりややLatencyがすくないのは不思議なところ。このIn-Page RandomではRyzen 9 5950XのLatencyがL3~Memoryで急に大きくなっている様にも見えるが、実際はIntel系が低く抑えている、というべきか。あとMemory領域ではE-CoreとP-CoreのLatencyが明確に違うのは、Load/Storeユニットの動作に起因するというよりも、P-Coreの共有L2の動作に起因するのかもしれない。
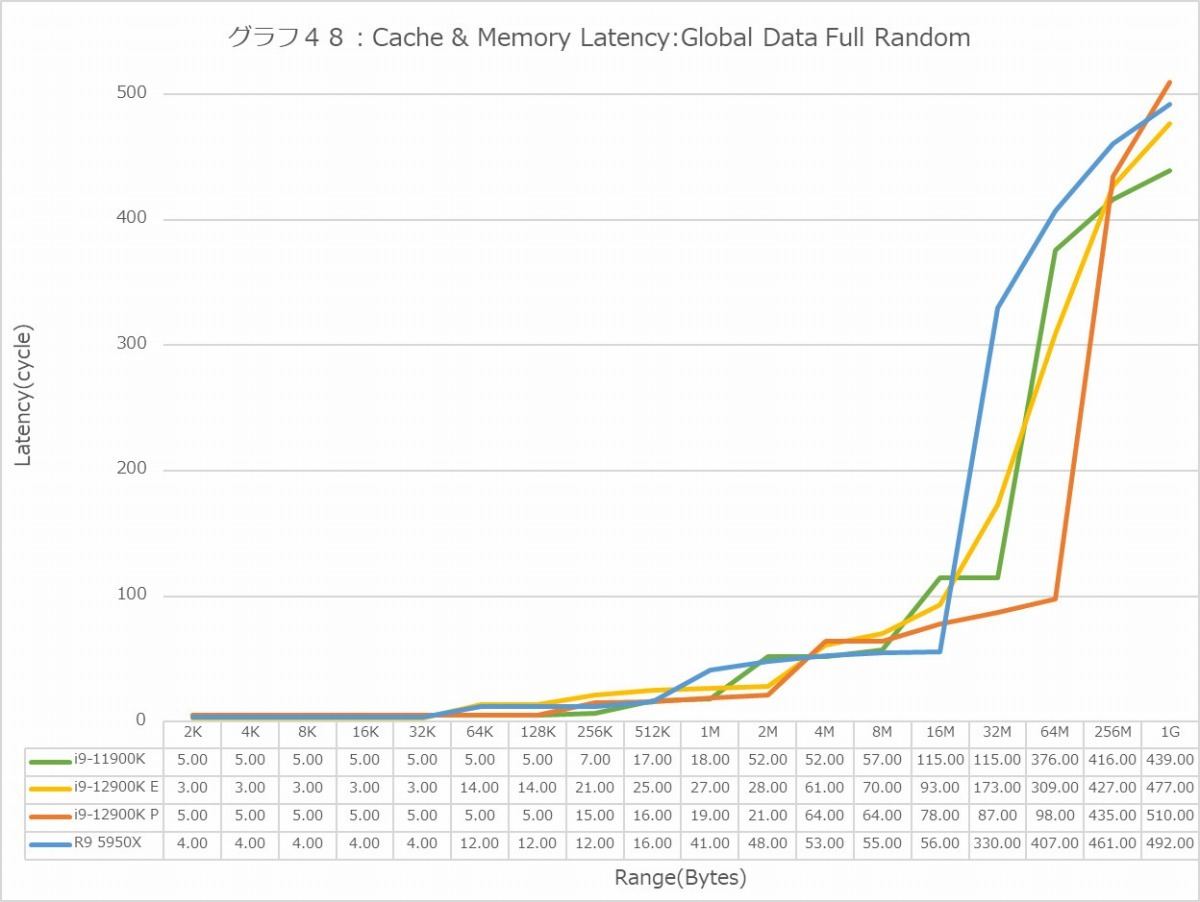
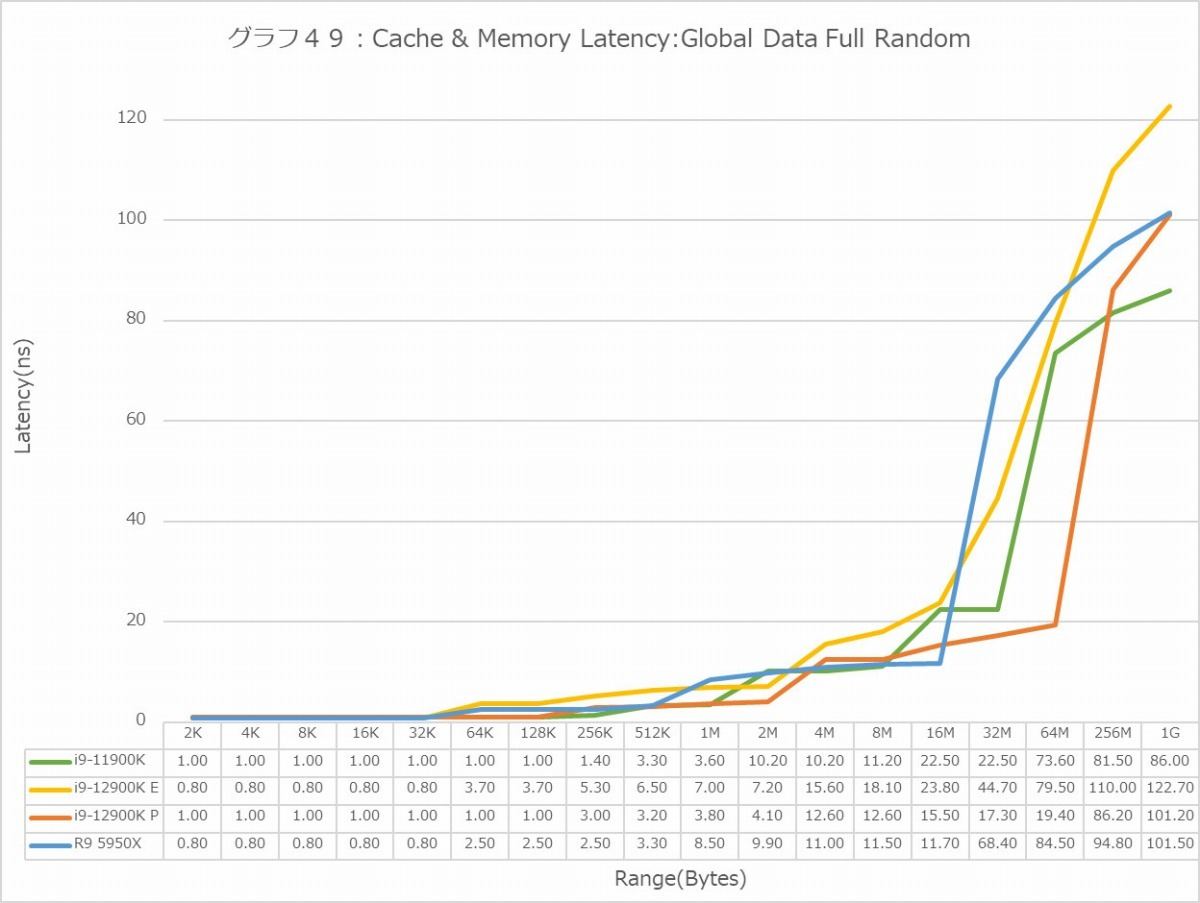
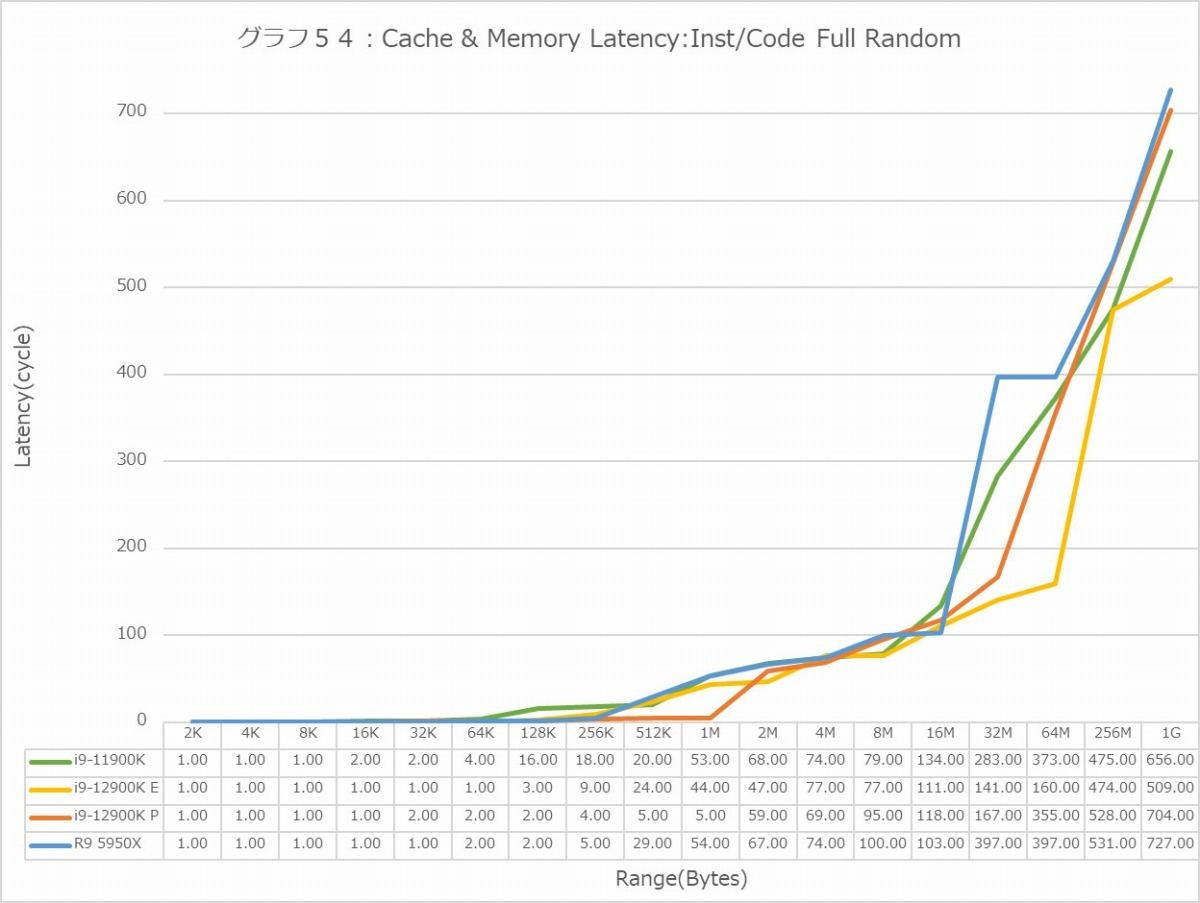
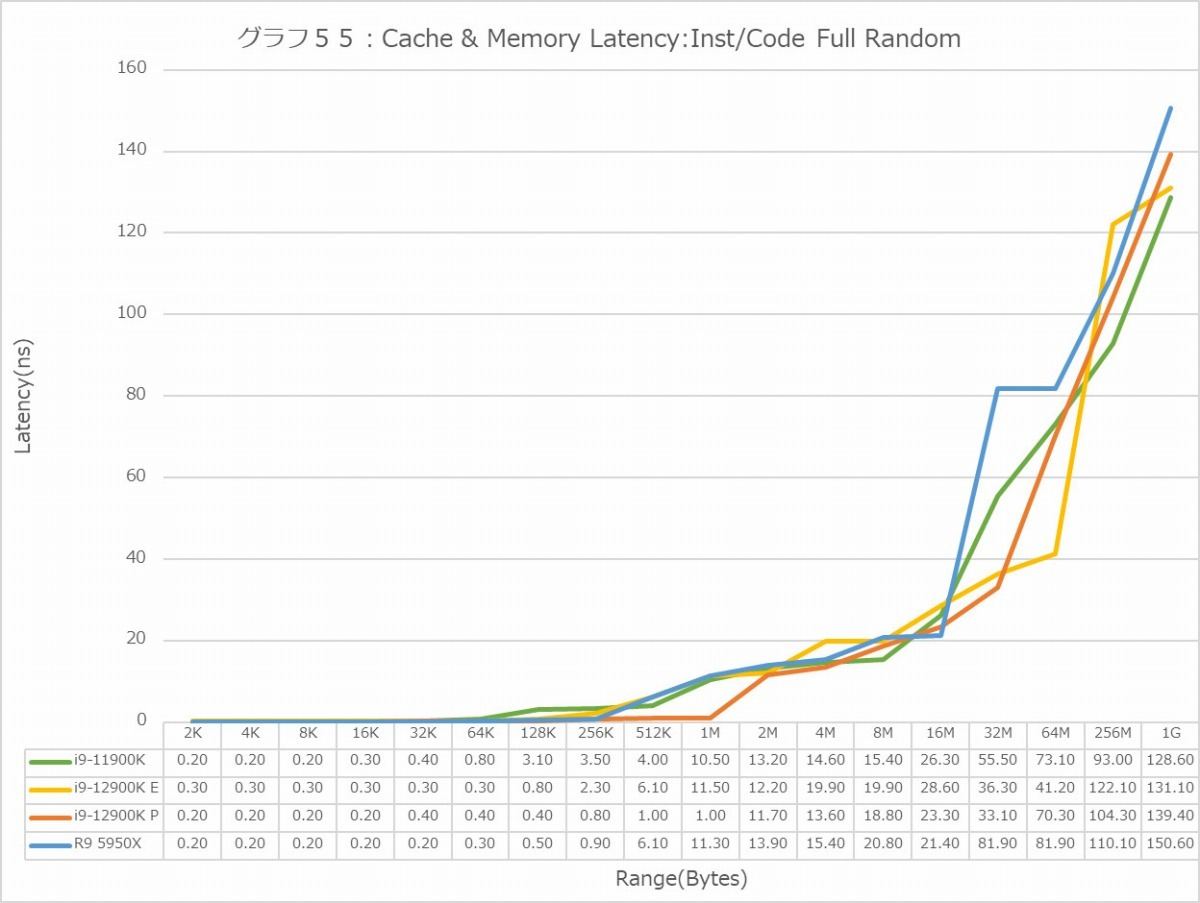
Full Random(グラフ48・49)では逆にRyzen 9 5950XのLatencyはそれほど極端に大きくはなく、逆にE-CoreのLatencyの大きさが目立つ格好になる。特に1GBだと、Latencyそのものは500cycle前後に見えるが、実際にはE-Coreのみ120ns台のLatencyになっているのはちょっと不思議である。
一方Inst/Code Cache(グラフ50~55)。Sequential(グラフ50・51)でL1はさすがにどのコアも1cycleでこれは不思議ではない。ただL2に入ると結構バラつきが出てくる。意外に暴れるのがRyzen 9 5950Xであり、逆にP-CoreはL2までは非常に優秀である。ここでもE-Coreは結構大き目の印象であり、特にMemory Accessになると11ns台までLatencyが増えるのはちょっと不思議である。
In-Page Random(グラフ50・51)になると差が減る印象である。強いて言えば、L3 Missから急速にP-CoreのLatencyが増えるのがちょっと不思議であり、逆にE-Coreは低め安定という感じだが、Memory Accessになるとどちらも22ns台で、16ns弱のCore i9-11900Kよりちょっと大きいのは、やはりMemory Controllerの違い(なのかDDR4/5の違いなのかは定かではないが)に起因するのであろう。
Full Random(グラフ54・55)ではL2におけるP-CoreのLatencyの低さがちょっと目立つ。これはL3も同じで、Ryzen 9 5950XはもとよりCore i9-11900Kと比較しても少ないのは優秀と言える。ただMemory Accessに関して言えば、Core i9-11900KよりややLatencyが増えているのは、もうそういうものだという感じである。
-
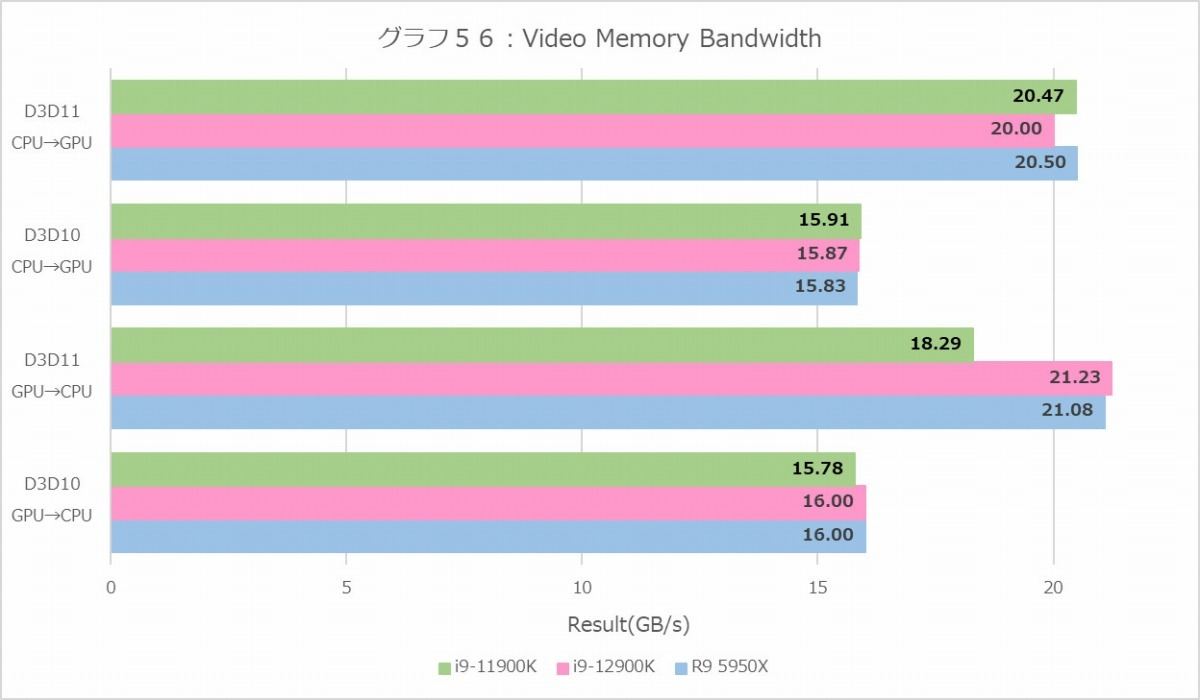
グラフ56

最後にVideo Memory Bandwidth(グラフ56)を。要するにPCIeの速度であるが、これはもう見ての通りで大きな差はない。Core i9-12900KはPCIe Gen5対応になってはいるが、その本領が発揮されるのはPCIe Gen5対応の拡張カードを利用した場合のみであり、PCIe Gen4対応のGeForce RTX 3080では差が無くて当然である。逆に言えば、PCIe Gen4カードを装着するとPCIe Gen4と変わらない振る舞いをする、という事が確認できた格好だ。








