
Ponte Vecchio
Ponte Vecchioに関しても、アーキテクチャなどについてはこちらで説明した以上の話はHot Chips 33では出てこなかった。ただHot ChipsのTutorial Sessionの中でパッケージング技術に関するセッションがあり、そこで色々な話題が出てきたので、そのあたりをまとめてご紹介したい。
さてまずはXe-coreから。Ponte VecchioというかXe-HPC向けではXe-CoreではVector Engineの数は8つとXe-HPG向けに対して半減しているが、各々のEngineの扱えるデータ幅は倍増して512bitになっている。この画像のキャプションでは「粒度がHPC向けだと16コアでは大きすぎる、ということだろうか?」と書いたが、冷静に考えるとAVX512に合わせてデータ幅を512bitに広げたかったのだと思う。IntelはoneAPIを利用して、CPU/GPU/FPGAで統一されたプログラミング環境を構築しようとしているが、この際にデータの幅が異なるとこれをそろえるので一苦労することになる。512bit幅にしておけば、CPU側のAVX512で扱う事もできるし、Ponte Vecchioで扱う事も容易になる。実際にはCXL経由で煩雑にCPUとの間でデータのやり取りをすることを考えれば、512bit幅にそろえる方が得策と判断したのだろう。
またこちらの画像のキャプションで「やはりMatrix EngineはTF32は使えてもFP32は使えない模様。」と書いたが、とりあえず現時点でのMatrix EngineはPhoto04にもあるように、FP32はサポートされていない。ちなみにこのMatrix Engine、Raja Koduri氏によれば「別にAI/ML命令だけでなくoneAPI経由汎用の行列計算エンジンとして使える」との事だったが、扱えるデータ型がなにしろAI/ML命令向けのみなので、第3世代のTensor CoreでFP64をサポートしたNVIDIAのAmpereの様に、これで算術向け行列演算を行うというのは現実的には厳しいようだ。
そしてこちらの画像のキャプションで「HPC向けのXe HPCでRay Tracing Unitを搭載する理由は今一つ判然としない。」と書いたが、これについてはJeff McVeigh氏(VP&GM, Data Center XPU Products & Solutions)より「HPC向けにもRay Tracingは必要だ。例えば大規模なシミュレーションの結果の可視化などで利用される。Ray Tracingの技術も進化しており、単に高速でというだけでなく、超高精画質を得る方向性もある。単にVisualizationのみならずContents CreationとかAI/MLなどでも利用される可能性がある」という返事を頂いており、ちゃんと意味を持ってRay Tracing Unitが搭載されている事が明らかになっている。
ところでXe-HPCというかPonte VecchioではStackという構成が用意されるが、これがPonte Vecchioにおける最小単位となる模様だ。Ponte Vecchioはこちら(Photo08)の様に、2つのStackが間にEMIBで繋がる様な構成になっているが、さてHotChipsでこのPonte Vecchioのパッケージについて行われた説明がこちら(Photo09)。ダイサイズとかは後でまた触れるとして、問題はPVC 2Tというコード名である。これについてはMcVeigh氏曰く「我々は異なるPower Enveropeに対応するために、1 Stack版のPonte Vecchioを予定している」と明確に返事があった。
-

Photo08: 実はこの図はあんまり正しくない。明らかに余分なTileがSliceあたり8つ存在する。

-
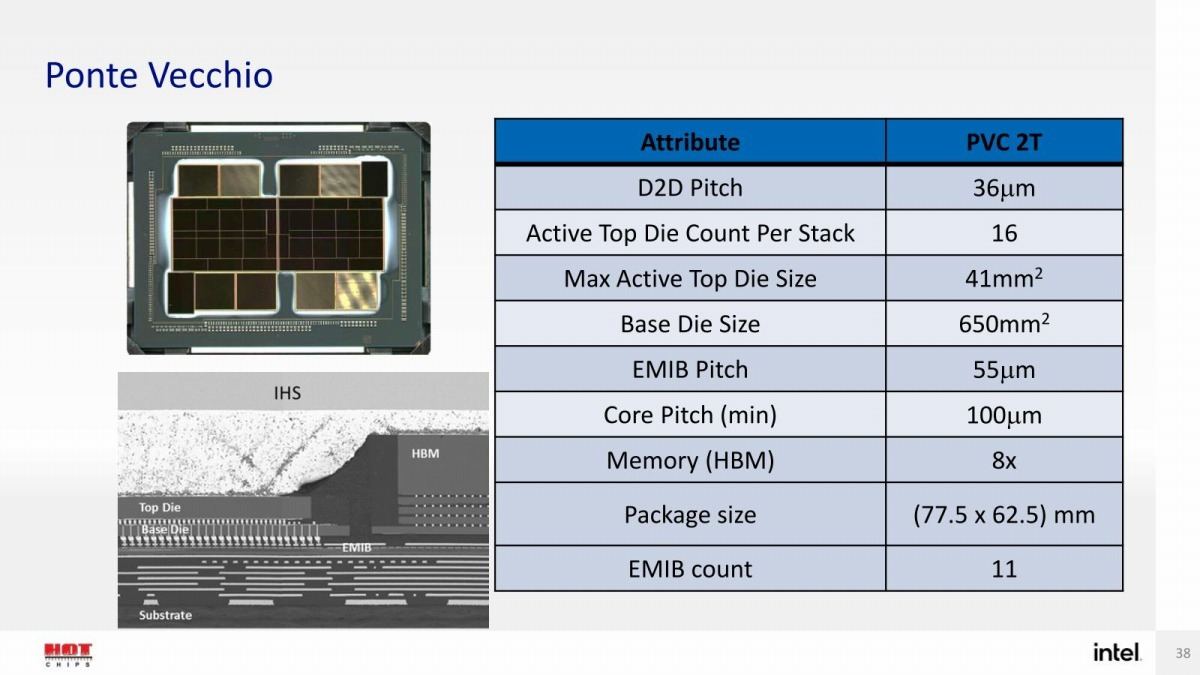
Photo09: この前には、まるで4つのTileが搭載された派生型もあるかのようなスライドが示されたが、こちらについてはKoduri氏が自ら「いやこれはDigital Legoみたいなもので、実際には4 Tileの構成のPonte Vecchioは存在しない」と否定していた。

ちなみにPonte Vecchioのパッケージ写真自体は今年1月にKoduri氏がTwitterに上げており、その意味ではHotChipsが初出という訳ではない。またこちら(Photo10)には"47 Tiles"とあるが、その内訳も今年3月にKoduri氏がMentionしている。
-

Photo10: 「5種類のプロセスノード」に関しても実は謎である。

こちらによれば
Compute Tile×16
Rambo Cache×8
Xe Base Tile×2
EMIB×11
Xe Link×2
HBM2e×8
となっており、つまりStack 1つあたり
Compute Tile×8
Rambo Cache×4
Xe Base Tile×1
EMIB×5
Xe Link×1
HBM2e×4
で、更に2つのStackを繋ぐのにEMIBが一つ使われる、という訳だ。さてこれを実際のダイ写真に当てはめると、ちょっと「?」となる。Photo11はKoduri氏がMnetionしたパッケージ写真の上半分に色々書き加えたわけだが、赤枠で囲った8つのTileが現時点で説明が皆無である。もっともPhoto10を見ると"Active Tile"が47とあるので、この赤枠で囲った部分は単に寸法合わせのPassive Die(つまり単に配線が繋がってるだけ)の可能性はある。縦方向はHBM2eメモリで寸法が決まるから、無駄でもなんでもHBM2eの分の高さを確保しないといけない。同様の理由で7nm世代のVegaはえらく無駄なダイの使い方になっていた訳で、そうした理由で無駄なTileが挟まっている可能性はありそうだ。
-

Photo11: 実はここはTileはなくて、Base Tileがそのまま見えているだけでは?とも思ったが、妙にはっきり境界線が見えているのでその可能性も少なそう。

先のPhoto09の表示に戻ると、Max Active Top Die SizeというのはこのPhoto11で黄色く囲んだCompute Dieが1つの寸法、Base Dieというのは、Compute Tile×8+Rambo Cache×4、それにこの赤枠で囲った用途不明な8つのTile全体のサイズの事を指す。と思われる。つまりこれらが大きな一つ(650平方mm)のBase Dieの上に載り、ここはFoverosで垂直方向に接続される。そしてBase Dieの外に4つのHBM2eとXe-Linkが配され、これはBase Dieとの間でEMIBで接続されるという訳だ。この構造、断面図がPhoto09の左下にあるので判りやすいと思う。
ちなみに製造プロセスとして公開されているのは、Compute TileがTSMCのN5、Base TileがIntel 7となっている。また今回は公開されていないが、2020年のHotChipsで、Rambo Cacheは旧10nm Enhanced SuperFin、現Intel 7で製造されることが明らかになっている(Photo12)。Xe LinkはTSMCのN7であり、あとはEMIBのプロセスとPhoto11で示したPassive Tile(これはなんでもいいので、例えばIntelの14nmとかかもしれない)をあわせて5種類のプロセス、というあたりなのかもしれない。
-
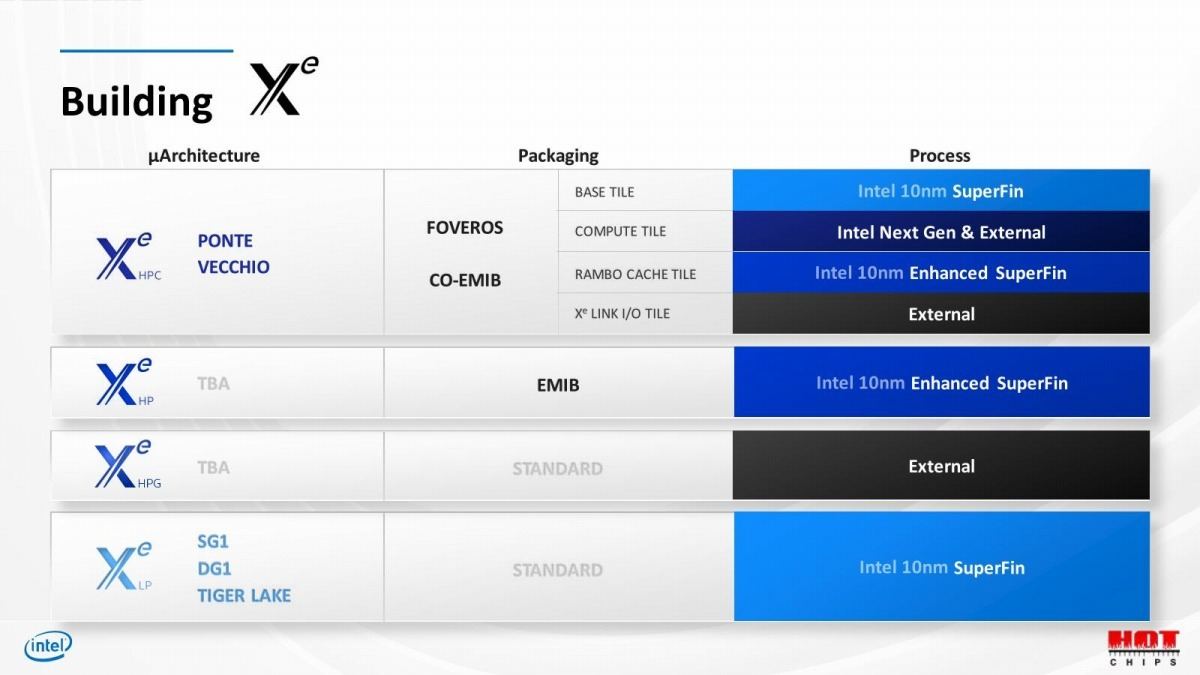
Photo12: ただこの表だとBase TileはIntel 7ではなくIntel 10nmだった筈で、その意味ではRambo CacheもひょっとするとIntel 7ではなくTSMC N5とかになってる可能性も無くはない。

Xe-LinkについてはPhoto13に示すように、最大8本のXe-Linkが出る形になる。ちなみにこのLinkは最大8つのStackを相互接続する以上の事は想定されておらず、より大規模なシステム向け(Scale out構成)の場合は、外部に別途Interconnectを利用する事になる。これもMcVeigh氏曰く「現状のXe-Linkは用途が限られており、またXe-HPC向けでしか利用されない」(つまりXe-HPG向けのマルチGPU接続などに使う事は出来ない)とはっきり明言している。
-
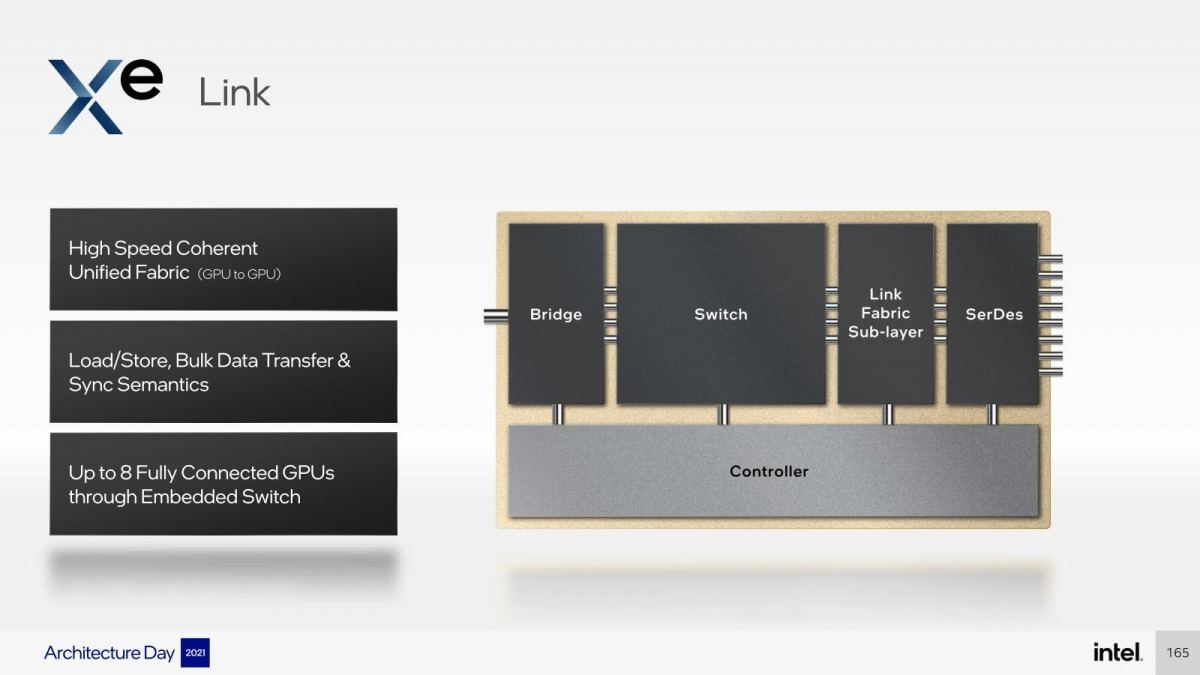
Photo13: 8本の双方向Link全体でおそらく最大90Gbpsの帯域と思われる。

さて、Ponte VecchioはAurora向けに、2つのSapphire Rapidsと4つのPonte Vecchio OAM(=8 Stack分)を一つのモジュールとして提供するとしており、つまりXe-Linkはこのモジュール内のSliceの相互接続に利用される形になるのだが(Photo14)、自身を含めて8つのStackを相互接続するには、7本のLinkがあればよい。では残り1本のLinkは何だろう? という話である。
-

Photo14: この"8x System Compute Rate"が処理単位(というか、1ノードの計算能力)の基本となるという構想だろう。

当初筆者はこれ、PCIe/CXL Bridgeに接続されるものと考えていたが、ANL(米アルゴンヌ国立研究所)のAuroraのInterconnectページを見ると、"Aurora will use Slingshot fabric connected in a Dragonfly topology with 8 fabric endpoints per node."なる文言がある。Auroraは主契約者こそIntelだが副契約者(つまりIntelの下請け)にCray Inc(現HPE)が入っている。Intelは個々のノード(つまりこれだ)内の接続には責任を持つが、ノード間の接続はCrayのSlingshotと呼ばれる独自Interconnectを利用する形だ。ここで出てくるDragonFlyは、複数のLocal Cluster同士を相互接続する、いわばInterconnectのバックボーンのアーキテクチャである(Photo15)。このDragonFryへのアクセスポイントがノード(つまりAurora Subsystem)に8つある、というのはおそらく8本のXe-Linkのうち1本はSlingShotのI/Fに接続される形になっているのではないかと思われる。Photo16は以前も紹介したスライドだが、この中で囲った赤枠の部分がSlingShotのI/Fではないかと筆者は推定している。
-
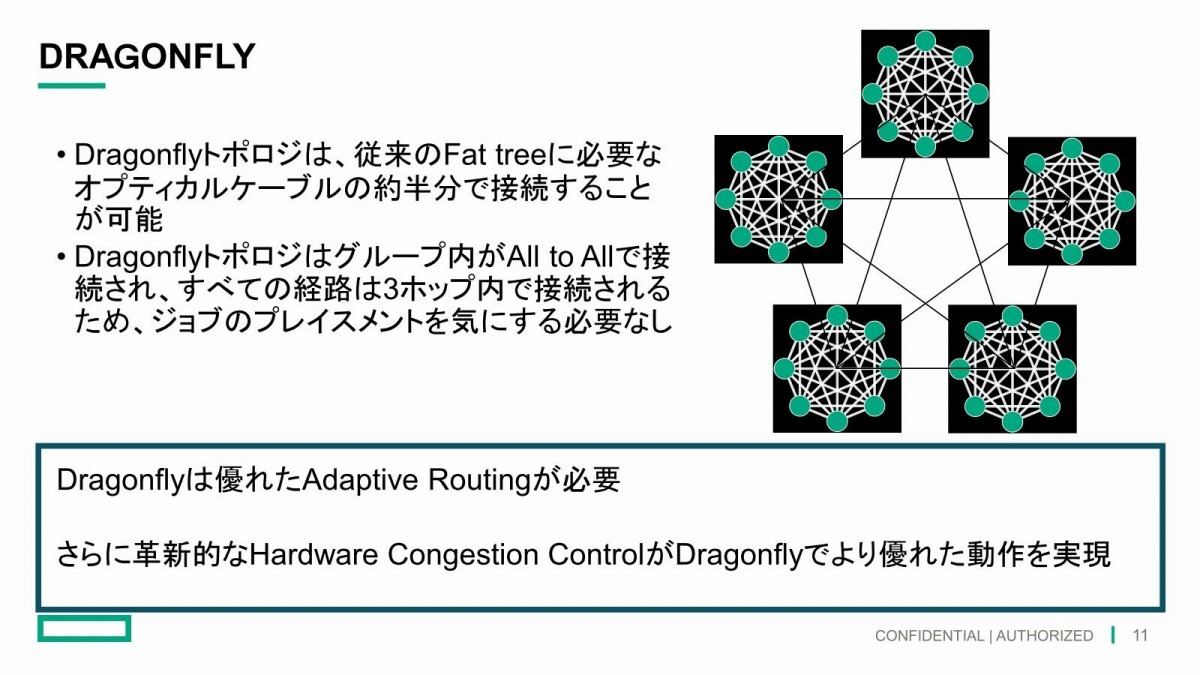
Photo15: SlingShotは実際のInterconnectの物理的なI/Fで、そのSlingShotを利用してノード間の接続を行うトポロジーの方式がDragonFlyとなる。

-

Photo16: PMICとかPCIe/CXL Bridgeにしてはあまりに大きすぎるので、他の用途は考えにくい。このOAMが4枚で8ポート分のSlingShot接続が可能になる。PCIe/CXLについては、Base TileにI/Fが搭載されるのかもしれない。

ちなみに実際にAuroraがどういう形でクラスタを組むのかはまだ明確ではないが、仮にFP64で1 ExaflopをPonte Vecchioだけで実現しようとすると、2500余りのノードが必要になる。Sapphire Rapidsの分も加味するともう少しノード数は減りそうだが、2000未満とう事はないだろう。これをフラットに相互接続するのは自殺行為なので、例えば40ノード位を一つのグループ(この中もDragonFlyで相互接続)し、そのグループ同士を別のDragonFlyで相互接続といった事が考えられる(あるいは3階層かもしれないが)。Auroraでは、Rosettaと呼ばれる64ポートのSlingShot Switchを利用するそうで、8ノードを相互接続できることになるが、おそらくは4~5ノードをノード同士の接続に、残りをDragonFlyを利用しての相互接続に割り当てる、という感じかと思う。
ところで性能。Photo16にも出ているが、A0 Siliconを利用しての結果だとFP32で45TFlops以上の性能とされる。1枚のOAMというのはつまり2 Stack/8 Slice/128 Xe-Coreであり、1個のXe-Coreが256 FP32 Ops/Cycleであることから逆算すると、このA0 Siliconの動作周波数はおよそ1.37GHz前後とされる。とりあえず1.4GHzほどで動いているので、45TFlops「以上」とされているのだと思われる。HotChips 33ではこれに加えてResNet-50を実施した場合の性能も示された(Photo17)が、これはIntelが2019年に買収したAIプロセッサベンダーであるHabana LabsのGoya(Inferenceが15000 image/sec以上)やGaudi(Trainingが1600 image/sec以上)を軽くぶっちぎる性能になっており、逆にこれらのInference向けプロセッサの存在意義が問われかねないところだ。
-

Photo17: もっともこれ、今は絶対性能よりも消費電力効率とか価格なども厳しく問われる時代なので、このあたりがPonte Vecchioはネックになる可能性はあるのだが。

ということで、遅くなったがIntelのGPUに関する動向である。これ以上細かい話は、おそらく製品発表時まで出てこない気はするのだが、10月末に開催されるIntel Innovationイベントでもう少し位は何か出てくる事を期待したいところだ。








