京コンピュータの次を開発するFlagship 2020プロジェクト

Flagship 2020プロジェクトについて講演する佐藤三久アーキテクチャ開発チームリーダー
京コンピュータは2011年の6月と11月のTOP500で世界一となった日本のフラグシップスパコンであるが、すでに7年近くを経過し、昨年11月のTOP500ランキングでは10位に下がっている。
この京コンピュータの次世代スパコンを開発するFlagship 2020プロジェクトで、Post-Kと呼ばれるスパコンの開発が行われている。このPost-Kコンピュータについて、理化学研究所(理研)で開催された「New Horizons of Computational Science with Heterogeneous Many-Core Processors」と題するワークショップにおいて、Flagship 2020プロジェクトのアーキテクチャ開発チームのリーダーを務める筑波大名誉教授の佐藤三久氏が講演を行った。
次の図に書かれているように、Flagship 2020プロジェクトのミッションは、京コンピュータに続く日本のフラグシップスパコンを開発し、社会的、科学的な問題の解決に役立つ広範なHPCアプリケーションを開発して、フラグシップスパコンで実行することである。
このFlagship 2020プロジェクトの開発主体は理研AICSで、ベンダーパートナーは富士通である。また、米国のDoEを始めとして、国際的な協調を行うという。
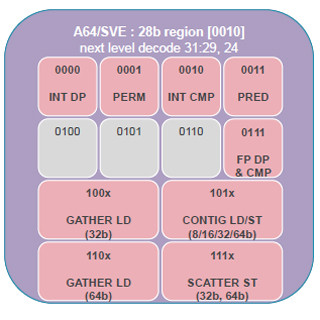
そして、現状は、基本設計が終わり、詳細設計と実装に入っている状態である。CPUのアーキテクチャとしては、Arm V8とArmのSVE(Scalable Vector Extension)を採用することを決め、シミュレータやコンパイラを使って性能評価を行っている状態という。
下に描かれた工程表では、Post-Kシステムは2021年の後半から2022年に稼働する計画になっている
-

Flagship 2020のミッションは、日本の次期フラグシップスパコンを開発し、社会的、科学的な問題の解決に役立つアプリの開発、実行を行うことである (このレポートのすべての図は、ヘテロメニーコアワークショップにおける佐藤氏の発表スライドを撮影したものである)

Post-Kの構成を読み解く
Post-Kでは、京コンピュータの時と同様に、次の図のように、各分野で代表アプリを選定し、それらに対して性能が出せるように、アーキテクチャや実装とアプリのチューニングをすり合わせるコデザインを行う。
-

Flagship 2020ではこれらの9種のアプリケーションを選定し、性能を高めるコデザインを行っていく

Post-Kシステムのハードウェアは、メニーコアのプロセサノードを6Dのメッシュトーラスネットワークで接続する。チップの集積度が向上したり、ネットワークのバンド幅が向上するなどの改良は行われるのは間違いないが、基本的な考え方は京コンピュータと変わっていない。
ストレージは3レベルとなり、京コンピュータと比べると、SSDの層が追加されている。高バンド幅を持つ、SSDの追加は最近の傾向に沿ったものである。
Post-Kは、GPUなどのアクセラレータは搭載しない。米国の次期フラフシップスパコンであるSummitが、NVIDIAのGPUを搭載するのとは考え方が異なる。
ソフトウェアでは、マルチカーネルのOSを採用する。1つは汎用のLinuxで、もう1つの計算ノード用のMcKernelは、理研AICSで開発して搭載する。そして、ファイルシステムにはSSDの階層を追加し、3階層のストレージをサポートするファイルIOミドルウェアを開発する。
-

ハードウェアの全体構造の図は、このレベルでは京コンピュータとほとんど同じに見える。OSはLinuxを使うが、計算ノードには低ジッタのMcKernelを開発して搭載する

Post-KのCPUは重量級の高性能48+コア構成を採用
そして、CPUチップは、48+(2または4)コアであることが明らかにされた。48コアが計算コアで、それにLinux OSを動かしてファイルIOやネットワークでの通信を行う2または4コアが追加される。この図では、12個の計算コアに1個の制御用コアというグループが4個あり、それぞれにメモリが接続されている。そして、4個のグループをNoC(Network on Chip)を介して接続する構造になっている。
現在、TOP500 1位の中国の太湖之光スパコンのSW26010チップでは、256コアが軽量のインオーダ実行の計算コアで、4コアがアウトオブオーダ実行の制御用のコアとなっている。より微細な半導体プロセスを使うPost-Kチップが52コアしか集積しないということは、相当、重量級の高性能コアを使うものと考えられる。
高性能コアを使うので、制御用のコアを区別する必要はなく、全部が同じコアを使う。つまり、物理的にはホモジニアスなマルチコアチップで、使い方で計算コアと制御コアというヘテロジニアスな構造で使用することになる。
重量級のアウトオブオーダ実行コアを計算コアとして使う京コンピュータは、HPLを実行するTOP500では10位に下がったが、メモリバンド幅が効くHPCGベンチマークや、グラフ処理のGraph500では世界の1位をキープしており、実用アプリの実行性能では高いランキングにある。実アプリの性能との相関が下がっていると言われるHPLではなく、指標として選択したアプリケーション群の性能を向上させるには、軽量コアよりも高性能コアだけを使う方が良いという判断と思われる。
軽量計算コアを多数搭載したり、GPUを搭載したりするスパコンが主流であるが、高性能の重量コアを(比較的)少数使うPost-Kがどのような性能を発揮するかは興味深い。
-

Post-Kプロセサは50あるいは52コアと比較的コア数が少なく、構成の重量級コアを使うと考えられる。この図では、13コアをグループとしてメモリが付けられ、NoCを介して4つのグループが結合されている

Post-Kプロセサは、Arm V8アーキテクチャでベクトル拡張のSVEをサポートすることはすでに述べたが、演算としてFP64、FP32とFP16をサポートし、SIMDベクトルレジスタは512bit長とSVEの範囲内では最長のレジスタを装備している。また、コア間の同期をとるためにバリアやセクタキャッシュなど、富士通独自の拡張を追加している。
SIMDベクタの長さは、京コンピュータでは128bitであったが、Post-Kでは512bitと4倍になっている。また、ディープラーニングなどに使われるFP16をサポートする点が新しい。
京コンピュータでは6次元メッシュ/トーラスのTofuネットワークを開発し、商用のFX100スパコンでは改良型のTofu2を使ったが、Post-Kでは、さらに改良を加えたネットワークを使う。
-

Post-Kでは命令アーキテクチャがArm V8+SVEに変わった。ベクトル長が512bitに拡張された点と、FP16がサポートされた点が新しい