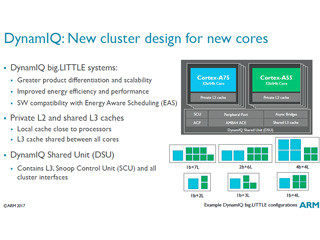
このように各ユニットはValidなデータが到着して、処理する仕事がある時だけ目覚めて、電力を消費する。なお、sleep状態でもファブリックは動かしておく必要はあり、電力はゼロにはならないが、消費電力を抑えることができる。なお、sleepには、比較的消費電力は大きいが短時間で処理を再開できるfast wakeupのスリープと、より低電力のdeep sleepの2つのスリープがある。

|
|
粗粒度のユニットは、通常はスリープ状態で、Validな入力が来るとアクティブになる。処理が終わってSleep命令を実行すると、スリープして低電力状態に戻る |
DPUとCPUのインタフェースはAXI(Advanced eXtensible Interface)を使う。8-64クラスタをまとめたものをCompute Machineと呼び、これをAXIで接続する。AXIとDPUのインタフェースは、下の左の図のようにFIFOを経由してiRAMにアクセスしている。

|
|
8-64個のクラスタをまとめたものをCompute Machineと呼び、この単位でホストCPUと通信するAXIのインタフェースを設ける |
DPUはPEが最小単位で、それが16個集まってクラスタになっている。そのクラスタが8-64個集まったものがCompute Machineである。そして、チップには32個のAXIのポジションがあるが、角の8個のところにはCompute Machineが置けないので、1チップのCompute Machineの数は24個となっている。

|
|
8-64クラスタをまとめてホストCPUと通信するAXIを設けたものをCompute Machineと呼ぶ。左下の図に見られるように、何種類かのサイズのCompute Machineが混在している |
DPUのメモリ階層は、次の図のようになっている。AXIの1つのチャネルに最大64個のクラスタが接続できる。各クラスタとAXIとの接続は20GB/sのバンド幅を持つ。そして、AXIは最大32チャネルを持つことができる仕様になっている。
AXIチャネルとCPU、4個のHMC、2チャネルのDDR4はAXI4 NOCで接続される。HMCメモリのバンド幅は60GB/s、DDR4のバンド幅は15GB/s、PCI Expressのバンド幅は30GB/sである。

|
|
DPUのメモリ階層。AXIの各チャネルに最大64クラスタが接続でき、AXIのチャネルと、CPUとHMCやDDR4メモリなどがAXI4 NOCで接続される |
DPUは、クラスタの内部は同期回路であるが、クラスタ間では非同期のGALSとなっている。通常のすべて同期型のクロックの場合は、クロックスキューでサイクルタイムが抑えられてしまうが、DPUのクロックはグローバルには非同期であるので、クラスタは6-10GHzという非常に高いクロックで動かして性能を上げることができる。

|
|
DPUの各クラスタ内部は同期回路であるが、クラスタ間は非同期のGALSとなっている。このため、クラスタは6-10GHzという高いクロックで動作する |
WaveFlowのソフトウェアスタックは、次の図のようになっている。まず、汎用サーバで走るWaveFlow Session ManagerでデータフローグラフをDPUに収容できる規模に分割する。また、DFグラフのスループットの最適化を行う。
実行にはBLAS1、2、3やCONV2D、Softmaxなどのライブラリが使われるので、それらをリンクする。そして、Wave ComputingのWave Deep Learning Computerで実行させる。
さらにオフラインでコンパイラやリンカを使って、自前のライブラリを開発したり、シミュレータなどのツールを使ってデバグや性能改善のためのチューニングを行う。

|
|
DPUのソフトウェアスタックは、ホストで動作するWaveFlowセッションマネージャとWave Computingのハードで動作するExecution Engine、別途用意するAgent Libraryからなる。また、オフラインで使用するWave Flow Graphコンパイラ、リンカ、シミュレータがある |
WaveFlow Agent Libraryは、TensorFlow用のものはWave Computingから提供されるが、顧客は必要に応じて、WaveSDKを使って追加を行うこともできる。

|
|
WaveFlowエージェントライブラリは、別途、コンパイルして作っておき、実行プログラムにリンクして使う。TensorFlow用のライブラリはWave Computingから提供される |
WaveFlow SDKは次の図に示すようなコンポーネントから構成されている。LLVMのフロントエンドとWFG(Wave Flow Graph)コンパイラでDPUの実行ライブラリを作り、WFGリンカで実行プログラムをリンクする。そして、WFGシミュレータやアーキテクチャシミュレータを使って、デバグやチューニングを行う。SDKの核をなすのはWFGコンパイラとWFGリンカであるが、これらの詳細は、2017年11月の「ICCAD 2017」で発表される予定である。

|
|
WaveFlow SDKの構成要素。WFGコンパイラとWFGリンカについては、11月のICCADで発表予定 |
次の図は16PEの1つのクラスタで積和を計算する例である。左の表は横方向のマスがPE0からPE15で、縦方向が時間で、それぞれのタイミングでどのような命令を実行するかがか書かれている。右側の図は、その計算を行うネットワーク接続が描かれている。

|
|
16PEの1クラスタで積和計算を行う例。左の表は、各PEがそれぞれのサイクルに実行する命令を書いたものである。右側の図は、積和計算を行うグラフである |
次の図の上側の図はInception V4ニューラルネットのグラフを描いたものである。左下の図にその一部をデータフローグラフで描いている。そして、セッションマネージャがこのグラフを各DPUチップに納まるように分割して割付を行う。

|
|
Inception V4ネットの構造と一部を拡大した詳細なグラフ。それを64 DPUを持つコンピュータにマッピングする |
64個のDPUを使う1ノードのデータフローコンピュータで、224×224×3色の1.28M枚のイメージの学習を、AlexNet、GooglLeNet、Squeezenetで行った結果を次の表に示す。AlexNetでは、学習のための推論の速度は962,000イメージ/秒で、90エポックの学習時間は40分であった。2012年のAlexNetの発表論文では、NVIDIAのGTX 580 GPUを2台使って5~6日掛かったのことであるので、それに比べると200倍くらい速いということになる。
GoogLeNetでは、学習のための推論速度は420,000イメージ/秒で学習時間は1時間45分、SqueezeNetでは、学習のための推論速度は75,000イメージ/秒で、学習時間は3時間であった。Seq2Seqの学習は論文に書かれたパラメタを使って7時間15分かかっている。

|
|
ImageNetの1.28M画像を使って90エポックの学習を行う場合の、学習速度と学習時間をAlexNet、GoogLeNet、SqueezeNetで比較したものである。64DPUでAlexNetの学習を40分で行っている。AlexNetの論文ではGTX 580 GPUを2個使って5~6日掛かっており、200倍程度速い |