
Interconnectが2次元Meshに変わるも、構造的には差はない
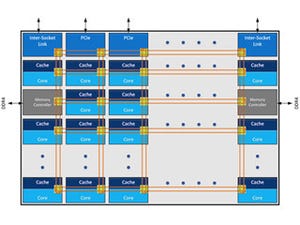
次がInterconnectである。こちらとかでも触れたように、Skylake-SPではコア間の接続に二次元Meshが採用された。確かに従来のRing Bus+Shared Unitの構造に比べると、よりスケーラビリティがある……というか、マシに見える。
ただMeshといいながらも、Interconnectを良く見てみると、いわゆるPoint-to-PointのInterconnectではなく、それぞれが全部Ring Bus構造に描かれている気がする。その意味では、Ring Busの構造そのものに差は無く、トポロジーが変わったというべきなのかもしれない(Photo11)。

|
Photo11:実際RingだろうがPoint-to-Pointだろうが変わらないといえば変わらないのだが。実は最初にMeshにしたと聞いて、ではBroadcastはどうするのだろう? と不思議に思ったのだが、Ringなら黙っていてもBroadcastになるから問題にならないということか |
各々のコアだが、CHA(Distributed Caching and Home Agent)とLLC(L3 Cache)、さらにSnoop Filterまで搭載された形になる(Photo12)。このCHAは、要するにUPIなど経由でのリクエストを受けてLLCの中身を送り出したり、逆にデータを受け取ったりという作業を担うもので、これをコア毎に搭載しているとする。また説明を読む限りは、各コアのSnoop Filterの管理もCHAの仕事に含まれているようだ。

|
Photo12:謎なのがSnoop Filterの実装方法である。L3の1.375MBの一部をSnoop Filterに割り当てるのか、それとも別にSnoop Filter用の領域が設けられているのか。ちなみにCHAはまずSnoop Filterを見て、他のコアがキャッシュしている領域を書き換えたい場合だけSnoopを出すような動きにすることでトラフィックを減らせる、ということらしい |
一部の製品ではソケット当たり1.5TBの大容量メモリが搭載可能
メモリコントローラ(Photo13)は6chをサポート。3chずつ2つに分割されてMeshと繋がる構造になっている。製品名にMが付く一部のモデルは128GB DIMMをサポートしており、これを利用すると6ch×2枚×128GB=1536GBということで、ソケットあたり1.5TBものメモリが利用可能である。

|
Photo13:とりあえず公式にDDR4-2666に対応した(以前はDDR4-2400まで) |
ちなみにark.intel.comを参照すると、Xeon PlatinumのハイエンドであるXeon Platinum 8180はRecommended Customer Price(希望小売価格)が10,009ドル、同じスペックながら1.5TB Memoryを利用可能なXeon Platinum 8180Mは13,011ドルと、3,000ドルほど上乗せされているあたり、これはそれだけの価値のある機能だとIntelは考えている様だ。
気になるのは対応メモリがRDIMM/LRDIMM/3DS-LRDIMMのみでUDIMM(Unbuffered DIMM)が無いことだ。もちろんXeonの場合はUnbuffered DIMMのような低信頼性のメモリは使っていられないから、サポートから外しているというのは分かるが、単にサポートから外しているだけではなく、本当に動かないという話もあるようで、特にCore-XのMCCベースとなるCore i9-7920X以上のモデルで、いろいろと苦闘しているという話がマザーボードメーカーあたりからもれ伝わってきており、大変だなという気がする。
ちなみに説明にあるXPT prefetchとD2C/D2Kや、新しいメモリエラー対策であるADDDCについても詳細は不明である。このあたりはDatasheetが公開されるまでお預けになる と思われる(現状は未公開)。
内部を2つのクラスタに分割して使う「SNC」
ところで、これは以前から可能な技術ではあるのだが、内部を2つのクラスタに分割して使うCoD(Cluster-on-Die)が、Skylake-SPではSNC(Sub-NUMA Cluster)としてサポートされる(Photo14)。以前だと2つのRing Busを繋ぐShared Unitの部分で分割する形だったが、今回は水平方向のMeshを論理的に分割するという形を取るようだ。

|
Photo14:Remote ClusterへのメモリアクセスのLatencyが減るというのは、要するに水平方向のMeshを使って、片方のClusterのMCからもう片方のClusterのMCへのリクエストを直接出せるということだと思われる |
ただし、ここで1つ疑問が生じる。論理的には水平方向のMeshは途中で分割されるのだが、物理的にはRingのままだから、あるCluster側のトラフィックがそのまま反対方向のClusterに流れ込むことも起こりうる。
おそらく、それぞれのコアにあるMesh Stopが流れてきたパケットのDomain No.を見て、自分のDomainと一致していなければ何もしない的な処理で対応していると思うのだが、トラフィックそのものとしては分割しても減らない訳で、このあたり悪影響を及ぼさないのだろうか?
メモリコントローラのBandwidthとLatencyのグラフがこちら(Photo15)だが、DDR4-2400の理論帯域が19.2GB/secなので、Xeon E5-2699v4(DDR4 4ch)の2Pだと15.36GB/secとなり、数字を見ると14GB/sec程度でているから効率91.1%でかなり高めである。

|
Photo15:やはりMeshのサイズが大きくなると、その分オーバーヘッドも増えるという、ごく当たり前のことで、SNC-2にするとMeshのサイズが半分になるから、それだけ効率が上げやすいという話に帰結する |
そのDDR4-2400を6ch使えるXeon Platinum 8180だと理論帯域が230.4GB/secで実測値が210GB/sec強だから、効率は91%前後でほぼ同等。DDR4-2666だと理論帯域256GB/secほどで、実測値は通常モードで235GB/secほどだからやはり91%ほどになる。
ところがSNC-2モードだと240GB/sec程になり、94%弱まで効率が上がっている。しかも同じ帯域ならSNC-2モードの方がLatencyも低め、というのはなかなか面白い。ちなみにCore→MemoryのLatencyの比較がこちら(Photo16)。全般的に、Latencyが増えないとは言わないまでも大きく変わりにくいのが特徴とは言えるかもしれない。

|
Photo16:NUMAのLocalだと80ns台、というのは筆者のテスト結果とは矛盾しない。NUMAのテストは行っていないが、Inte-Core Latencyの数字が擬似的に利用できる。LCCだと70ns台だから、HCCだともう少し増えるのは当然で、Localだと80ns台なのは不思議ではない |








{kind=link}