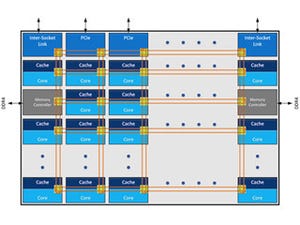
チップ間の接続はUPIに
次がUPIの話。UPIはUltra Path Interconnectの略だそうで、Bandwidthそのものは9.6GT/sec→10.4GT/secだからそれほど増えていないが、電力効率を最大21%向上させ、更にアイドル時電力を半減させたといったあたりが特徴とされる。

|
Photo17:これを見る限り、UPIはQPIの延長にあるパラレルバス(Single Ended/Uni-Directional)で、これを双方向分装備する形であるが、電圧レベルの変更と、新しい省電力モードを搭載したというあたりだろうか。ただ全く違う構成の可能性が否定された訳ではないのだが、Photo12を見ると"2x UPI x20"なんて書き方をしているところを見ると基本QPIと一緒なのでは? という気がする |
面白いのは2 UPIと3 UPIの両方の構成があることで、2 UPIだと最大4 Socket、3 UPIだと最大8 Socketが可能になるというあたりだろうか。昨今のトレンドを考えると、4 Socketとかこれを超える構成が必要とされるケースは極めて少なく、2 Socketで繋ぐ限りはどちらでも差はないのだが、UPIの本数によるラインナップの違いが、依然として残ることになる。
I/O周りは、3つのMesh Stopの下に3つのPCI Express x16のコントローラとDMI、それとCBDMAのコントローラがぶら下がる形になる。それぞれのMesh StopにPCIe x16が1つずつで、後はCBDMAとDMIがそれに付属する形だ。
構造自体は分からなくもないのだが、Root Complexが3つというのはServer Workloadとかには適切な一方、Desktop向けに例えばSLIなりCrossFireなりで複数のグラフィックスカードを繋ぐような用途だと、Mesh経由でRoot Complex同士の通信が煩雑に発生することになり、ちょっと不利ではあるかもしれない。
ところでPhoto18の下に、VMDがRoot Complex毎に搭載されるとあるが、その中身がPhoto19である。PCIe x16レーンを4本のx4レーンに分割し、各々のOn/Offが出来るほか、自身の配下にあるNVMeデバイスをPCIeデバイスではなくStorageデバイスとして見せかける機能を持つ。

|
Photo18:DMIのI/FはTraffic Controllerを含めてPCIe x16レーンと共用、というのは仮にこのPCIe x16がフルで使われているとDMIの側の性能はあまり期待できないという事にもなる |

|
Photo19:こうした機能を見ると、PCIeの目的が当初の汎用I/O向けから、どんどんStorage接続用I/Fに変化しつつあることを実感する |
これにより、NVMeデバイスをアクセスする際に、PCIe経由でリクエストを出すのではなく、普通にSATA/SASデバイスの様にソフトウェアから扱えるようになり、これを利用したRAIDなどが簡単に構築できるようになるというものだ。
次が省電力周りの話である。まず動作周波数制御であるが、Skylake-SPではより緩やかに動作周波数を下げる仕組みが入ったとする(Photo20)。もっともこれはAMDのZenコアの様に、倍率そのものを微細化した(Zenコアは25MHz単位)のではなく、あくまでもP0とP0nの落とし方を緩やかにした、というだけの違いの様だ。続くSpeed Shift Technology(Photo21)そのものはSkylake世代で入ったもので、今回も特に違いはない。

|
Photo20:要するにSkylake-SPではTurbo→Normalへの移行を、1bin(100MHz)いきなり落とすのではなく、少しずつ落とす様にプロファイルを変更したという事らしい |

|
Photo21:これは動作周波数の制御を、既存のACPIのP0/P1/...の切り替えに頼らず、CPU側で制御できるようにしたもので、よりワークロードにあわせた形で動作周波数を変更できる(かつ切り替えが高速化される)というもの。ただしフルに使うにはOS側のサポートも必要である。最近だとWindows Server 2016などでもこれをサポートしており、Xeonでもこれをちゃんと利用できるようになった |
RASに関係する部分であるが、Intel RunSure Technology自身は以前から提供されている。今回の追加は、AEDCとLMCE、それとAdaptive DDDC+1の3項目であるが、詳細は明らかにされていない。メモリコントローラのところにあったXPT prefetchやD2C/D2K同様、Datasheetの公開が待たれるところだ。

|
Photo22:Run Sure Technologyそのものは2014年のIntel Xeon E7 v2で初導入されている。今回の場合、Xeon Platinumには当然これは入っているだろうが、Xeon Gold以下でこれがどの程度実装されているかは不明 |
Omni-Path InterconnectをCPUに統合
最後がOmni-Path Interconnect絡みの話である。元々この世代からOmni-Path InterconnectをCPUに統合するという話はあったが、一部のSKUでこれをサポートすることになった。こちらの右下に"with integrated Intel Omni-Path Architecture Fabric"と書かれた枠に7製品がラインナップされているのがそれである。

|
Photo23:このOmni-Path Fabricに関してはあまり基板上で配線を引き回す訳にもいかないようで、割とCPUソケットのすぐそばにQSFPモジュールが装着される形になるようだ。この結果が"Platform design requires an expanded keep-out zone and additional board components to accommodate both processors"という注意書きに繋がる訳だ |
図で見ると、PCIe x16レーンを一つ専用し、その先にQSFPモジュールを繋げて使う形で、さすがにSilicon Photonicsを内蔵するというわけには行かなかったようだ。またこれがPCIe x16をまるごと使うので、利用できるのはPCIe x16を4組持つHCCのXeon PlatinumとMCCのXeon Goldに限られているのは無理ないところか。
それはいいのだが、ここで突如として登場したのが"Skylake-F"である。この単語、ほかのスライドで一切出てこない。要するにSkylake-Fは"Skylake-SP+Omni Fabric"の意味だと思うのだが、以前(2015年頃)の報道ではSkylake-Fは25製品ほど登場するはずだった。さらにその後にはStorm Lakeと言われるMCM構成の製品が出るなんて話もあった。この話そのものは消えた様なのだが、コード名としてのSkylake-Fのみは残ったという事だろうか?
Throughput Computingに振った製品に
ということでIntelの資料を元に、簡単にSkylake-SPの内部を紹介した。何というか、ベースであるSkylakeコアそのものはあまり変わっていないが、製品としての方向を大分Throughput Computingに振った感がある。
もちろんCloudだのBig Dataだののトレンドを考えるとこれは間違いではないと思うのだが、極端に製品の方向性が変わったなというのが率直な感想である。このあと市場でEPYCと競うことになる訳だが、既存のシェアをどこまで守りきれるのか、非常に興味あるところだ。