



Summitのノード構成
次の図はSummitのノードのブロックダイアグラムである。図の中央にある横方向に2つ並んでいる小さな箱が2個のPOWER9 CPUで、両端の縦に並んだ3個の箱がV100 GPUである。CPUと3個のGPU間、そして3個のGPU同士はNVLink2で直結されており、キャッシュコヒーレントにメモリをアクセスすることができる。
各GPUには16GBのHBMメモリが付き、各CPUには256GBのDRAMが付いている。
そして各CPUは16GB/sのPCI Express経由でInfiniBandのデュアルチャネルNICに接続されている。
-
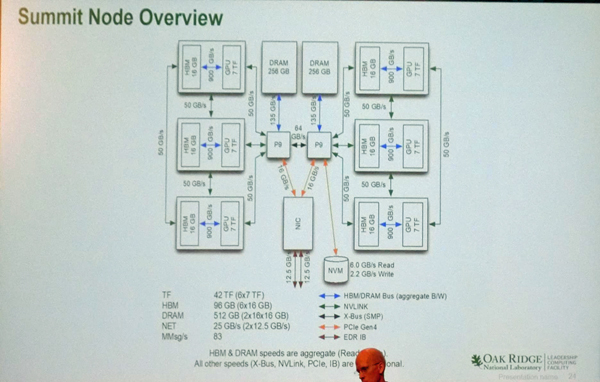
Summitノードのブロックダイアグラム。中央の2個の小さな箱がPOWER9 CPU。両側の3個の大きな箱がV100 GPUである。GPUとCPUは高バンド幅でキャッシュコヒーレントなNVLink2で接続されている

Titanではメモリアクセスが遅かったので、多くのアプリケーションは、GPUメモリだけを使い、メインメモリをあまり使っていないプログラムが多かったという。
しかし、POWER9はDRAMメモリチャネルを8チャネル備えているので、ピーク170GB/s、STREAMベンチマークで135GB/s程度のメモリバンド幅が期待できる。そして、2つのPOWER9 CPUを接続するX-Busは64GB/sのバンド幅を持っているので、反対側のCPUに接続されたメモリをアクセスする場合のNUMA効果を緩和することができる。と書かれているが、64GB/sではちょっと細いのではないかという気もする。
-

POWER9は8チャネルのメモリバスを持ち、ピーク170GB/s、STREAMベンチマークで135GB/s程度のバンド幅が期待できる。他方のCPUのメモリも64GB/sのX-Bus経由でアクセスすることができる

IOは、他のサーバに先駆けてPCI ExpressのGen 4をサポートしている。そして、MellanoxのGen 4をサポートしているHCAを組み合わせることで、それぞれのPOWER9 CPUからInfiniBand HCAに16GB/sの接続を実現している。
また、サーバに搭載したNVMeは6GB/sのRead、2.2GB/sのWriteバンド幅を実現している。
-

Summitの計算ノードは、PCI Express Gen 4をサポートしている。このため、IB HCAから各CPUに16GB/sで接続できる。また、計算ノードはSamsungのNVMeをサポートしている

SummitはTitanからどれくらい性能が向上したのか
次の表は、TitanとSummitの諸元を比較したものである。
まず、Summitのアプリケーション性能は、Titanの5-10倍になっている。一方、ノード数は4,608とTitanの1/4になり、ノードのFlops性能は42TFlopsと30倍になっている。ノードのメモリはDDR3 32GBからDDR4 512GBと容量だけでみても16倍で、さらにバンド幅も増えている。GPUメモリもGDDR5 6GBからHBM 96GBと容量16倍に加えてバンド幅が大きく改善されている。結果としてシステム全体の高速メモリはTitanの710TBから、Summitでは10PB以上となっている。
インタコネクトは、Titanでは6.4GB/sのGeminiを使っていたが、SummitではデュアルレイルのEDR InfiniBandで25GB/sとバンド幅が4倍になっている。しかし、Flops性能の向上の比率には追い付いておらず、並列計算のプログラミングが難しくなる傾向は継続している。
インタコネクトのトポロジは、Geminiは3Dトーラスであったが、SummitではノンブロッキングのFat Treeになっている。ベンダがCrayからIBMに変わったことと、ノード数が1/4に減ったことがFat Treeの選択に影響していると思われる。
ファイルシステムは、Titanでは容量32PB、バンド幅1TB/sのLustreであったが、Summitでは容量250PB、バンド幅2.5TB/sのGPFSとなっている。
そして、消費電力は、Titanが9MWに対してSummitは13MWと1.44倍となっている。アプリケーション性能が5-10倍で、メモリ容量が16倍の物量を考えると、やむを得ないという感じである。
-
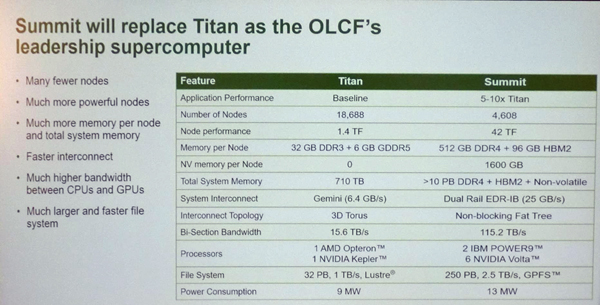
TitanとSummitの諸元の比較。アプリケーション性能は5-10倍。ノード数は1/4になっている。消費電力は13MWとTitanの1.44倍

TitanとSummitの性能比較
SummitではPOWER9 CPUと3個のV100 GPUはNVLink2で結ばれているので、GPUは256GBのCPUのメモリを自由にアクセスすることができる。また、3個のGPUのデバイスメモリもアクセスできる。NVLinkがなければ、各GPUは自分の16GBのHBM2メモリしかアクセスできず、他のGPUやCPUのメモリをアクセスするにはPCI Express経由の転送が必要であるが、Summitの場合は合計で約300GBのメモリを直接アクセスできる。それで足りなければ、1600GBの容量のNVMeメモリを使うことも可能である。
これらの機能は、大容量のメモリを必要とする大規模なAIやビッグデータの処理には非常に効果がありそうである。
なお、バンド幅が狭くなったり、レーテンシが長くなったりするが、64GB/sのX-Bus経由で反対側のCPUやGPUのメモリを使ったり、IB NIC経由で他のノードのメモリをアクセスすることは、もちろん、可能である。
-
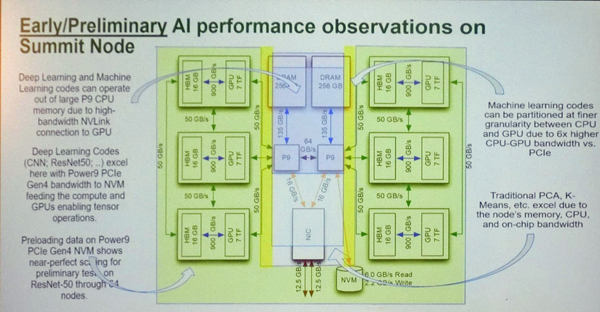
大容量のメモリを必要とするAI処理では、256GBのCPUメモリや1600GBのNVMeメモリを活用して、ノード外のメモリアクセスを最小にして、処理性能を改善できる

次の図は6種のディープラーニングコードをSummitDevシステムとSummitシステムで実行した場合の性能を示すものである。
なお、SummitDevはSummitのソフトウェア開発マシンで2個のPOWER8 CPUに4個のP100 GPUを接続したノードを持つマシンである。ここでのスピードアップの棒グラフは、Titanの性能を1としてSummitDevシステムとSummitシステムの性能(GOps/sなど)を示していると考えられる。そして、棒グラフに付けられた数字はTitanとの性能比率である。
6種のコードで多少の違いはあるが、SummitDevでは3.5-4倍の性能、Summitでは5.9-6倍の性能になっている。また、下のグラフは、学習の1エポックに掛かる時間をプロットしたもので、24GPUでは2000秒弱掛かっていたものが384GPUでは100秒程度に短縮されている。
-
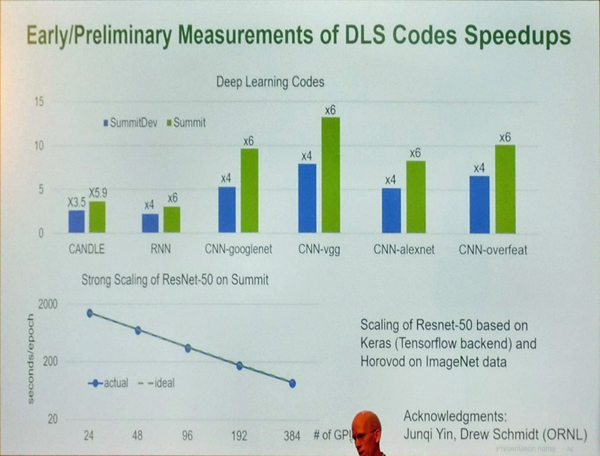
Summitでのディープラーニング処理性能の初期の測定結果。SummitではTitanの5.9-6倍にスピードアップされている。左下のグラフはノード数を24-384と変えて1エポックの学習時間をプロットしたもので、ほぼ理想的にスケールしていることが分かる

(次回は8月2日に掲載します)











