



前回はWebページの中身を自動的に取得するPowerShellスクリプトに、Microsoft Edgeを使う方法を追加した。具体的には、ヘッドレスモードを使い、Microsoft Edgeを起動しなくても中身だけを取得できるようにした。今回は、この機能でも取得できないWebページに対応していく。
Microsoft Edgeヘッドレスモードとcurl
前回までに作成したWebコンテンツ自動取得PowerShellスクリプト「netcat.ps1」は次の通りだ。
#!/usr/bin/env pwsh
#========================================================================
# URLで指定されたリソースを取得
#========================================================================
#========================================================================
# 引数を処理
# -URL url WebリソースのURL
# -Agent agent リクエストで使うエージェントを指定
#========================================================================
Param(
[Parameter(Mandatory=$true)][String]$URL = "",
[String]$Agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
)
#========================================================================
# Webリソース取得に利用するアプリケーション
#========================================================================
$msedge='C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe'
$curl='C:\Windows\System32\curl.exe'
#========================================================================
# どの方法でWebリソースを取得するかを判断
#========================================================================
if (Test-Path $msedge) {
#================================================================
# Microsoft Edgeを使って取得
#================================================================
$method='msedge'
}
elseif (Test-Path $curl) {
#================================================================
# curl を使って取得
#================================================================
$method='curl'
}
else {
$method='none'
}
#========================================================================
# Webリソースを取得
#========================================================================
switch ($method)
{
#================================================================
# Microsoft Edgeを使って取得
#================================================================
'msedge'
{
$o1='--headless'
$o2='--dump-dom'
$o3='--enable-logging'
Start-Process -FilePath $msedge `
-ArgumentList $o1,$o2,$o3,$URL `
-Wait
}
#================================================================
# curl を使って取得
#================================================================
'curl'
{
& $curl --location `
-A $Agent `
-get $URL
}
}
このスクリプトでは、Microsoft Edgeとcurl.exeを使っている。Microsoft Edgeを使うことで取得できるページの幅が広がったが、まだ取得できないWebページは存在している。今回は、そうしたページを取得できるようにする方法を説明する。
Microsoft Edgeヘッドレスモードで取得できないWebページ
例えば「https://helpx.adobe.com/security/products/acrobat/apsb22-32.html」のページを閲覧してみよう。これは、次のようにAdobeが自社製品のセキュリティ脆弱性情報を公開しているページだ。
-
https://helpx.adobe.com/security/products/acrobat/apsb22-32.html

「Webページの中身をPowerShellスクリプトで自動的に取得できるようにしたい」というのは、要するに「Webページに掲載されているデータを自動的に収集して、プログラムを使って自動的に分析を行わせ、結果だけを人間が利用したい」ということだ。
セキュリティ脆弱性情報の処理は、そうした自動化が活きる作業の一つである。できるだけプログラムに自動処理させて、人間はリスクの高い情報だけを確認するようにしたい。
しかし、このWebページの情報を前回作成したnetcat.ps1で取得しようとすると、次のように期待しているのとは違う結果が返ってくる。
PS C:\Users\daichi> netcat.ps1 https://helpx.adobe.com/security/products/acrobat/apsb22-32.html
<html><head>
<title>Access Denied</title>
</head><body>
<h1>Access Denied</h1>
You don't have permission to access "http://helpx.adobe.com/security/products/acrobat/apsb22-32.html" on this server.<p>
Reference #18.d706573c.1658383856.5b1be733
</p></body></html>
PS C:\Users\daichi>
Webサーバに「Access Denied」と判断され、コンテンツの提供が拒否されていることがわかる。Microsoft Edgeという同じソフトウエアからアクセスしているのだが、ヘッドレスモードでアクセスした場合には拒否されていることになる。
Microsoft Edgeの開発者モードで分析
Webブラウザであろうとcurl.exeコマンドであろうと、Webサーバとのやり取りにはHTTPプロトコルが使われている。ということは、ウィンドウの状態のMicrosoft Edgeと、ヘッドレスモードのMicrosoft Edgeで、使っているHTTPプロトコルが異なるのではないか、という予測をすることができる。
しかし、HTTPプロトコル自体はかなりシンプルなもので、そこに違いがあるとは考えにくい。おそらく、HTTPリクエストのヘッダに指定する情報に違いがあるのだろう。この辺りは、Webアプリケーションの開発を行っている開発者であればある程度予測のつく内容だ。
ということで、Microsoft Edgeの開発者モードを開いて、このページを取得するときに指定されているHTTPリクエストヘッダの内容を確認してみる。
-
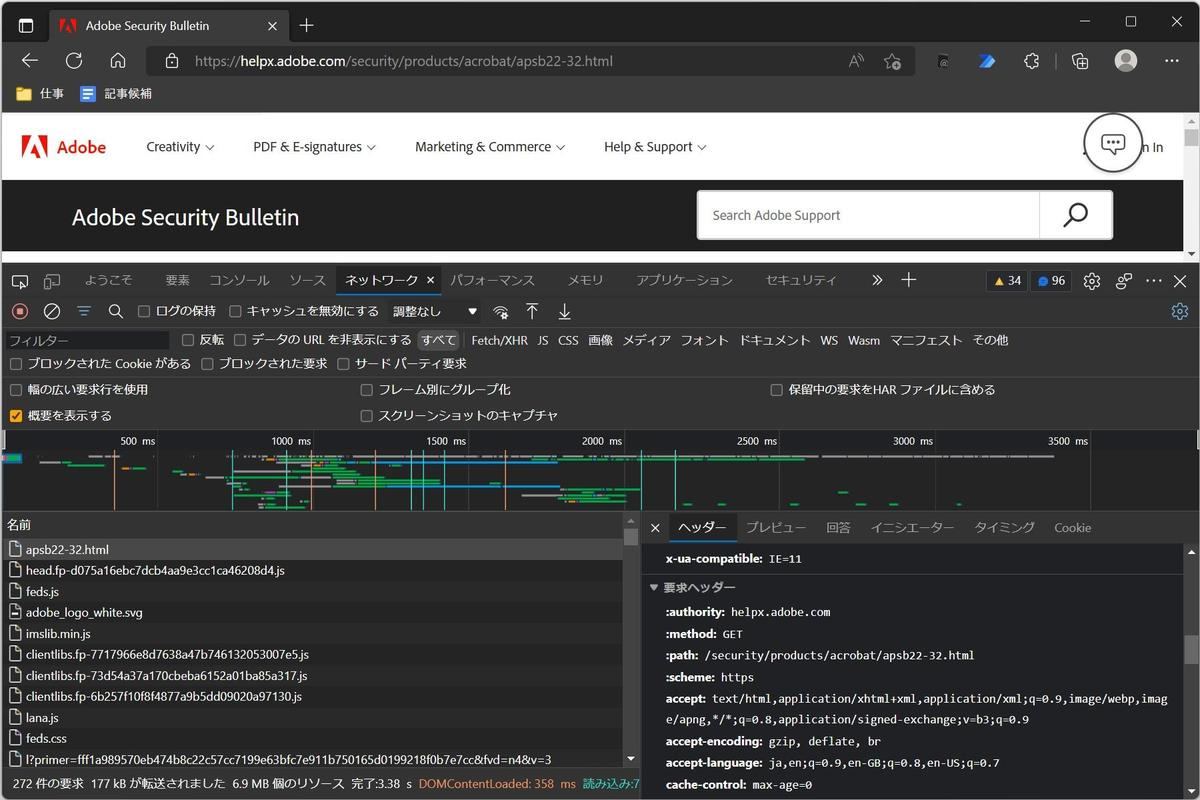
ページ取得時のHTTPリクエストヘッダを確認 - Microsoft Edge開発者モード

-
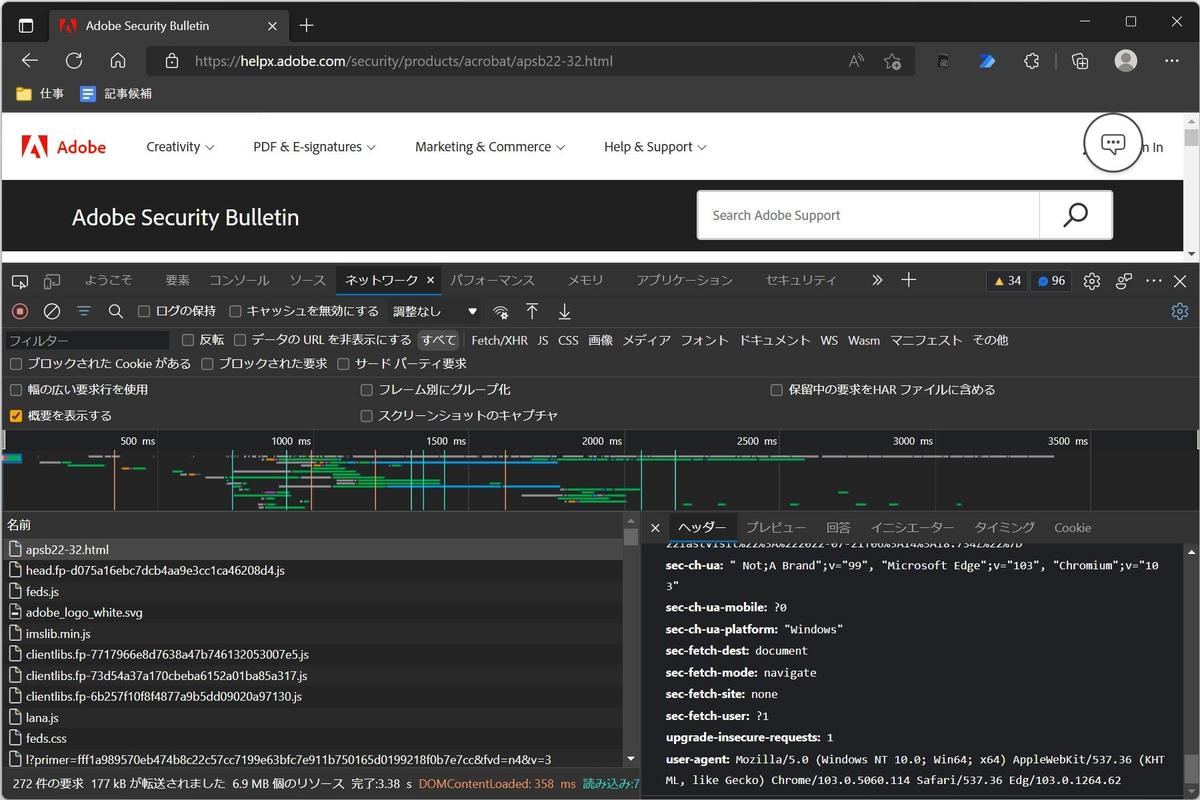
ページ取得時のHTTPリクエストヘッダを確認 - Microsoft Edge開発者モード

調べていくと、どうもMicrosoft Edgeをヘッドレスモードで使うとHTTPリクエストヘッダの「user-agent」の項目が足りないようだ、ということに行き当たる。つまり、以前取り上げたcurl.exeと同様、こちらでもuser-agentを指定する必要があるということだ。
Microsoft Edgeのヘッドレスモードでは、次のような感じでuser-agentを指定することができる。
--user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
指定するuser-agentの内容は、とりあえず以前curl.exeを使うときに指定した値と同じにしておけばよい。早速PowerShellスクリプトに反映させてみよう。


user-agentを指定したMicrosoft Edgeヘッドレスモード
Microsoft Edgeのヘッドレスモードにuser-agentを指定するようにしたPowerShellスクリプト(netcat.ps1)は、次の通りだ。
#!/usr/bin/env pwsh
#========================================================================
# URLで指定されたリソースを取得
#========================================================================
#========================================================================
# 引数を処理
# -URL url WebリソースのURL
# -Agent agent リクエストで使うエージェントを指定
#========================================================================
Param(
[Parameter(Mandatory=$true)][String]$URL = "",
[String]$Agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
)
#========================================================================
# Webリソース取得に利用するアプリケーション
#========================================================================
$msedge='C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe'
$curl='C:\Windows\System32\curl.exe'
#========================================================================
# どの方法でWebリソースを取得するかを判断
#========================================================================
if (Test-Path $msedge) {
#================================================================
# Microsoft Edgeを使って取得
#================================================================
$method='msedge'
}
elseif (Test-Path $curl) {
#================================================================
# curl を使って取得
#================================================================
$method='curl'
}
else {
$method='none'
}
#========================================================================
# Webリソースを取得
#========================================================================
switch ($method)
{
#================================================================
# Microsoft Edgeを使って取得
#================================================================
'msedge'
{
$o1='--headless'
$o2='--dump-dom'
$o3='--enable-logging'
$o4='--user-agent="$agent"'
Start-Process -FilePath $msedge `
-ArgumentList $o1,$o2,$o3,$o4,$URL `
-Wait
}
#================================================================
# curl を使って取得
#================================================================
'curl'
{
& $curl --location `
-A $Agent `
-get $URL
}
}
今回の変更はそれほど大きなものではない。先ほどの示したオプションを指定するようにオプションを追加しただけだ。指定するuser-agentは「Mozilla/5.0 (Windows NT 10.0; Win64; x64)」にしてあり、curl.exeで使っているのと同じにしてある。
実行すると次のようになる。
PS C:\Users\daichi> netcat.ps1 https://helpx.adobe.com/security/products/acrobat/apsb22-32.html
<!DOCTYPE html>
<html class="spectrum--medium wf-adobeclean-n4-active wf-adobeclean-n7-active wf-adobeclean-n3-active wf-adobeclean-i4-active wf-adobeclean-n9-active wf-active" lang="en-US" theme="system" font="loaded"><head>
...略...
<noscript><img src="https://helpx.adobe.com/akam/13/pixel_41a19677?a=dD1mMDA4NjQxMzIxYTc5ZjMyNGUxZjRmODViZjU3ZDMxMTFkOTljNTFjJmpzPW9mZg==" style="visibility: hidden; position: absolute; left: -999px; top: -999px;" /></noscript>
<script src="https://geo2.adobe.com/json/?callback=srpGeoLookupCback"></script></body></html>
PS C:\Users\daichi>
変更前と違い、Webページの内容が適切に取得できていることがわかる。
curl.exeのときも説明したが、Webサーバの中にはアクセスしてくるクライアントのuser-agentの値で処理を振り分けているものがある。適切なuser-agentを指定していないアクセスは、人間からのアクセスではないと見なしてアクセスを拒否するといった処理が行われる。そうしたWebサイトも少なくないため、自動的にWebコンテンツを取得しようとした場合には適切なuser-agentを指定することが大切だ。
今回の改良で、netcat.ps1で取得できるWebページが増えた。さらに汎用的に利用できるスクリプトにするために、次回以降も改良を続けていく。このスクリプトはほかのスクリプトのベースとしても使用できるので、改良する中でいろいろと体験しておくと後々役立つはずだ。










