


前回のスクリプト改良で、Microsoft Edgeのヘッドレスモードを使って取得できるWebページの種類が増えた。しかし、このままだと実はページャと共に使えない。今回は、この問題を解決する方法を実装する。
Microsoft Edgeのヘッドレスモードで取得できるWebページが増加
前回作成したPowerShellスクリプト「netcat.ps1」は次の通りだ。Microsoft Edgeのヘッドレスモードの動作に「User-Agent」の指定を行うことで、取得できるWebページの種類を増やした。curl.exeのときと同じ方法だ。
#!/usr/bin/env pwsh
#========================================================================
# URLで指定されたリソースを取得
#========================================================================
#========================================================================
# 引数を処理
# -URL url WebリソースのURL
# -Agent agent リクエストで使うエージェントを指定
#========================================================================
Param(
[Parameter(Mandatory=$true)][String]$URL = "",
[String]$Agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
)
#========================================================================
# Webリソース取得に利用するアプリケーション
#========================================================================
$msedge='C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe'
$curl='C:\Windows\System32\curl.exe'
#========================================================================
# どの方法でWebリソースを取得するかを判断
#========================================================================
if (Test-Path $msedge) {
#================================================================
# Microsoft Edgeを使って取得
#================================================================
$method='msedge'
}
elseif (Test-Path $curl) {
#================================================================
# curl を使って取得
#================================================================
$method='curl'
}
else {
$method='none'
}
#========================================================================
# Webリソースを取得
#========================================================================
switch ($method)
{
#================================================================
# Microsoft Edgeを使って取得
#================================================================
'msedge'
{
$o1='--headless'
$o2='--dump-dom'
$o3='--enable-logging'
$o4='--user-agent="$agent"'
Start-Process -FilePath $msedge `
-ArgumentList $o1,$o2,$o3,$o4,$URL `
-Wait
}
#================================================================
# curl を使って取得
#================================================================
'curl'
{
& $curl --location `
-A $Agent `
-get $URL
}
}
これでかなり多くのWebページを自動取得できるようになったのだが、実はページャと一緒には使えない。今回はその原因を調べるとともに、解決方法を実装する。
ページャで補足できない
netcat.ps1でWebページの内容を取得して閲覧できるのだから、これをパイプラインでページャにつなげて、インタラクティブに中身を確認したいというのは当然出てくる要望だ。例えば、次のようにnetcat.ps1の出力を「more」に接続して使うといった使い方だ。
-
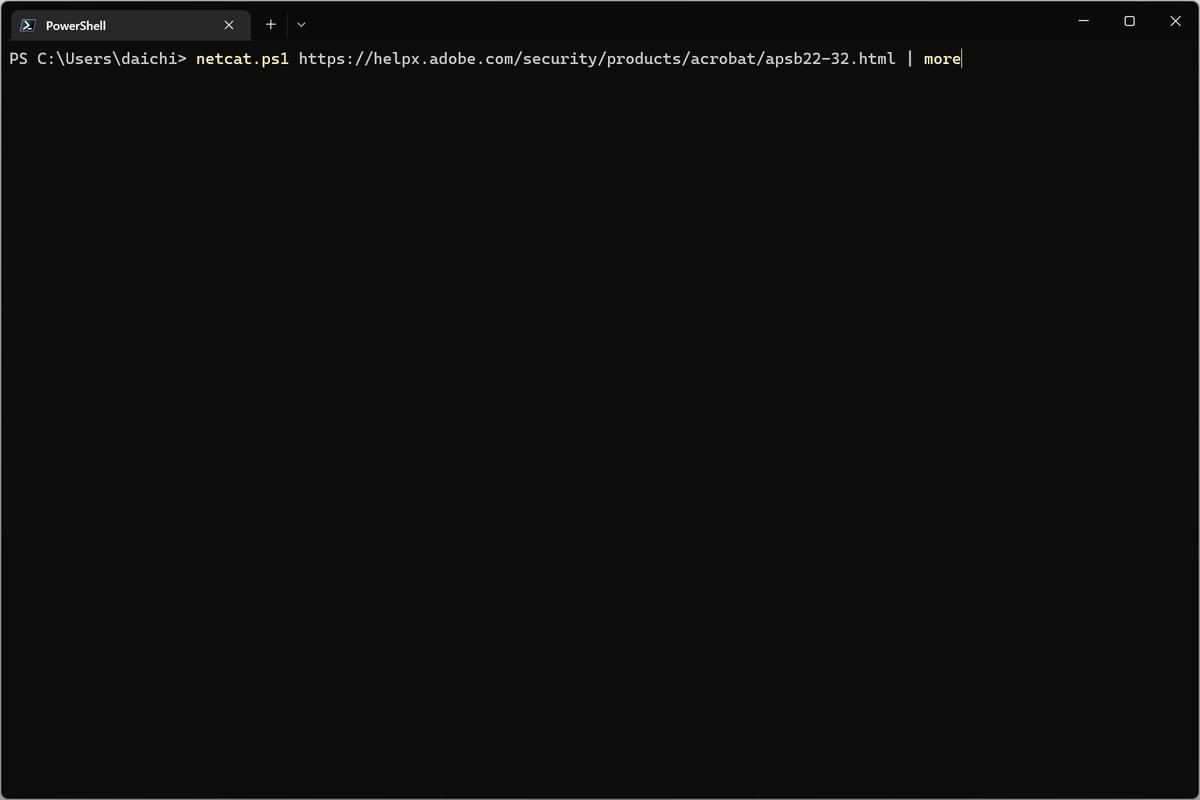
netcat.ps1の出力をmoreにつなげる

しかし、このコマンドを実行すると、次のようにページャは機能せず、netcat.ps1の出力が行われて処理が完了してしまう。
-
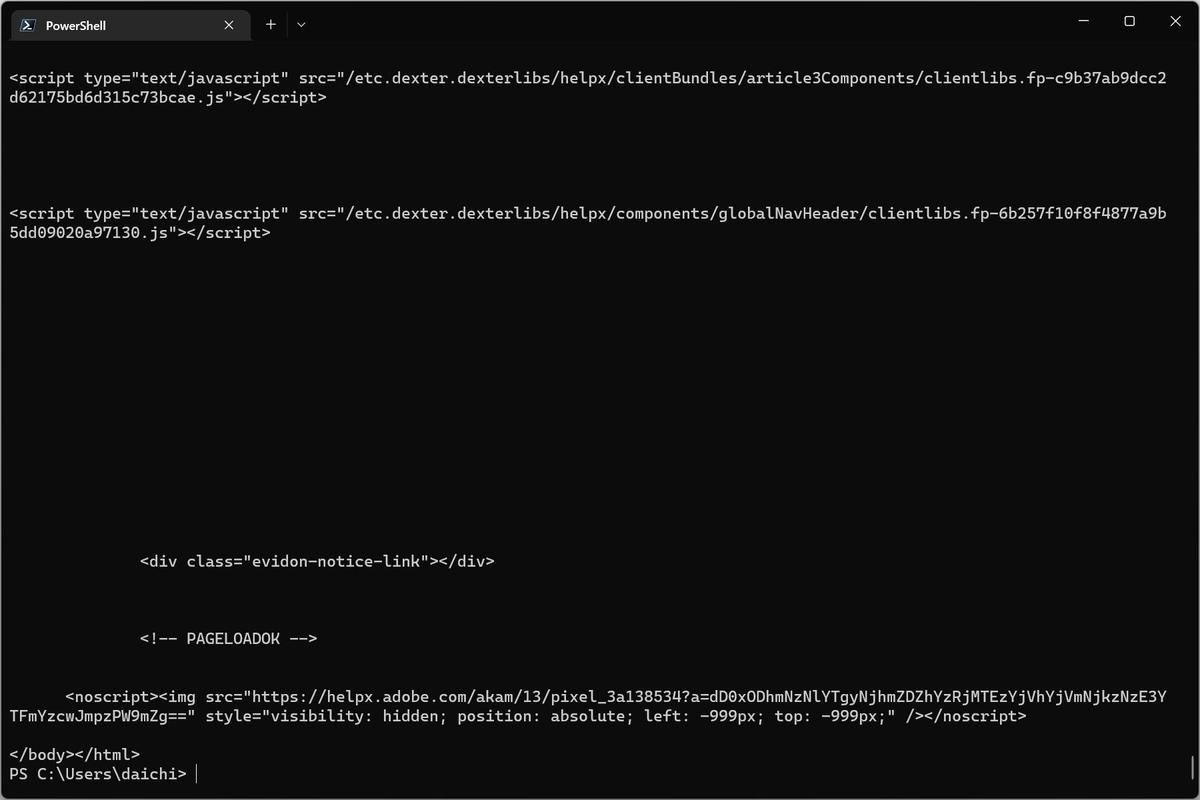
実行してみるとmoreが機能していないことがわかる

期待している動作はこうではない。まず、次のようにnetcat.ps1を実行する。
-
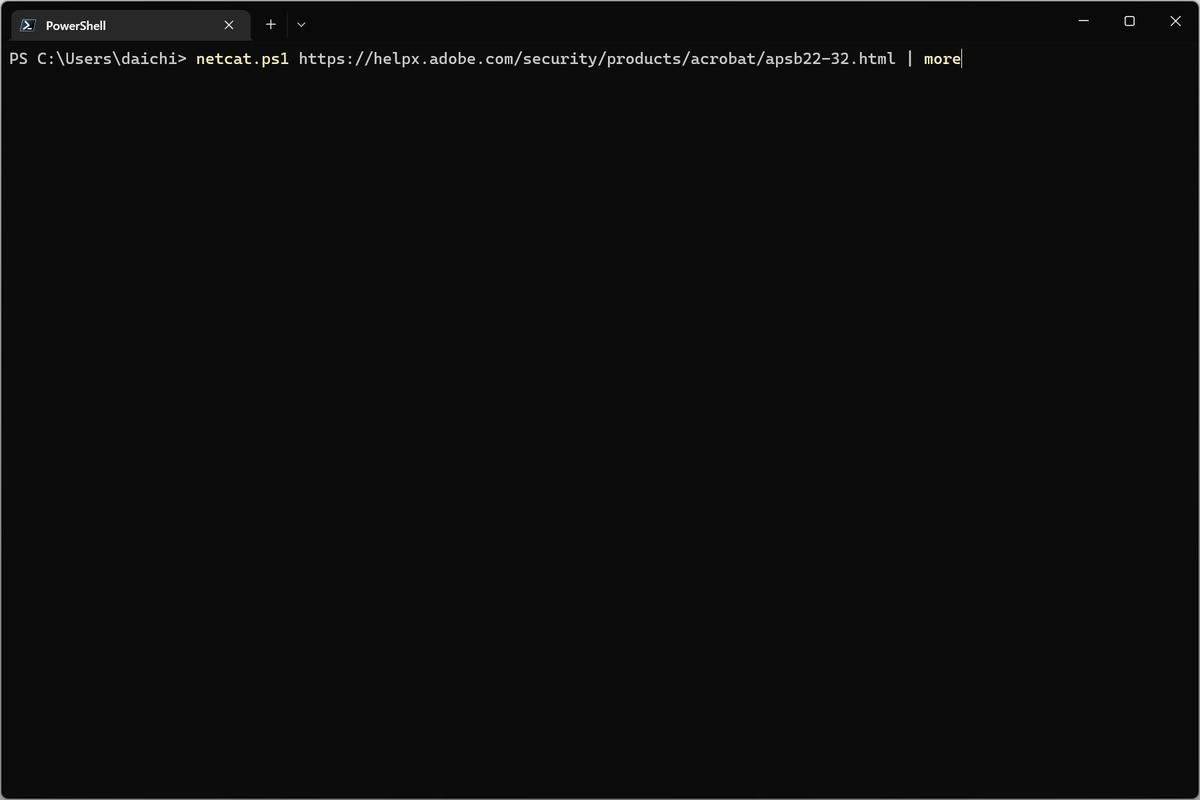
netcat.ps1を実行する

その結果、次のようにmoreで閲覧できる状態になることを期待している。
-
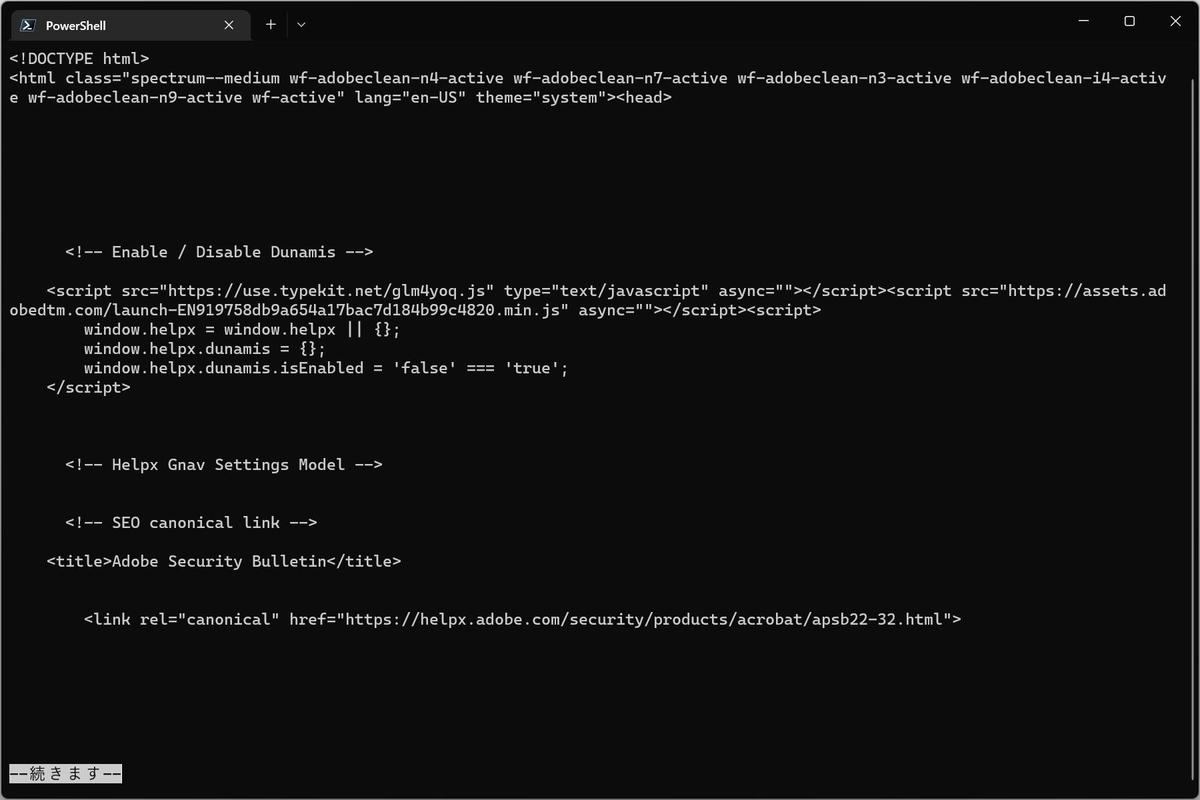
netcat.ps1の出力をmoreで補足して閲覧している

netcat.ps1の動きとしては、これができないと使い物にならないのだ。


なぜページャで補足できないのか
これはPowerShellのStart-Processコマンドレットに理由がある。netcat.ps1では次の処理でStart-Processコマンドレットを使い、Microsoft Edgeをヘッドレスモードで起動している。
Start-Process -FilePath $msedge `
-ArgumentList $o1,$o2,$o3,$o4,$URL `
-Wait
Start-Processコマンドレットは、現在実行されているシェル(つまりPowerShell)とは独立したプロセスを生成する。つまり、起動されたMicrosoft Edgeはnetcat.ps1を実行したシェルとは直接つながっていない。標準出力はWindows Terminalに出力されてはいるものの、シェルとはつながっていないので、パイプライン経由で補足することができないのだ。
MacやLinuxの場合には、同じ方法で起動されたプロセスはシェルと関連付けられるため、そのままでパイプラインにつなげることができる。だが、WindowsのPowerShellの場合にはこの方法は使えないのである。
どうやって解決するか
現在のPowerShellで利用できる機能を使う場合、やり方はいくつか考えられる。最も簡単なのは、出力をファイルにリダイレクトすることと、プロセスが終了するまで待機するStart-Processのパラメータを使うことだ。
Start-Processはシェルとは独立したプロセスを生成する。つまり、Start-Processを実行した時点で、起動したアプリケーションの終了を待つことなく、PowerShellスクリプトの処理は進んでしまう。本来は、ヘッドレスモードのMicrosoft EdgeがWebページの内容を持ってきて出力が完了するまで、次の処理には進んでほしくないわけだが、実際には待つことなく進んでしまうのだ。
ここで利用できるパラメータがある。「-Wait」パラメータだ。このパラメータを指定すると、起動したアプリケーション(プロセス)が終了するまで、Start-Processコマンドレットは待機するようになる。
-Wait
Start-Processコマンドレットは、プロセスをシェルとは独立したものとして起動する。このため、このコマンドレットは起動するアプリケーション(プロセス)の標準入力、標準出力、標準エラー出力をファイルにリダイレクトするパラメータを提供している。そうしないと簡単に通信できなくなってしまうからだが、この機能を使えば、Start-Processで起動したMicrosoft Edgeの出力結果をファイルに保存し、PowerShellスクリプト側から扱えるようになる。
-RedirectStandardOutput ファイルパス
netcat.ps1側では、Microsoft Edgeの処理の完了を待ち、処理が終わったらファイルの内容を出力すればよい。これでnetcat.ps1に接続されたパイプライン経由でデータを流していくことができるというわけだ。
一時ファイルの作成と組み合わせる
いったんファイルに保存するので、一時ファイルを用意し、処理が終わったら削除する処理を加える。次のようにNew-TemporaryFileコマンドレットを使えばよい。
$tmpf=New-TemporaryFile
...略...
Remove-Item $tmpf
Microsoft Edgeの出力結果を上記で作成した一時ファイルに出力させておけば、次のようにGet-Contentコマンドレットで中身を出力することで目的は達成される。
Get-Content $tmpf
ここまでに説明した内容をまとめると、次のようになる。
$tmpf=New-TemporaryFile
Start-Process -FilePath $msedge `
-RedirectStandardOutput $tmpf `
-ArgumentList $o1,$o2,$o3,$o4,$URL `
-Wait
Get-Content $tmpf
Remove-Item $tmpf
これでページャも利用できるし、curl.exeと同じように扱える状態になる。
実行してみよう
今回の成果物をまとめたnetcat.ps1は、次のようになる。
#!/usr/bin/env pwsh
#========================================================================
# URLで指定されたリソースを取得
#========================================================================
#========================================================================
# 引数を処理
# -URL url WebリソースのURL
# -Agent agent リクエストで使うエージェントを指定
#========================================================================
Param(
[Parameter(Mandatory=$true)][String]$URL = "",
[String]$Agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
)
#========================================================================
# Webリソース取得に利用するアプリケーション
#========================================================================
$msedge='C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe'
$curl='C:\Windows\System32\curl.exe'
#========================================================================
# どの方法でWebリソースを取得するかを判断
#========================================================================
if (Test-Path $msedge) {
#================================================================
# Microsoft Edgeを使って取得
#================================================================
$method='msedge'
}
elseif (Test-Path $curl) {
#================================================================
# curl を使って取得
#================================================================
$method='curl'
}
else {
$method='none'
}
#========================================================================
# Webリソースを取得
#========================================================================
switch ($method)
{
#================================================================
# Microsoft Edgeを使って取得
#================================================================
'msedge'
{
$o1='--headless'
$o2='--dump-dom'
$o3='--enable-logging'
$o4='--user-agent="$agent"'
$tmpf=New-TemporaryFile
Start-Process -FilePath $msedge `
-RedirectStandardOutput $tmpf `
-ArgumentList $o1,$o2,$o3,$o4,$URL `
-Wait
Get-Content $tmpf
Remove-Item $tmpf
}
#================================================================
# curl を使って取得
#================================================================
'curl'
{
& $curl --location `
-A $Agent `
-get $URL
}
}
実行結果は次の通りだ。
-
改良したnetcat.ps1を実行

-
ページャで補足できるようになっている

Start-Processコマンドレットは、MacやLinuxといったUNIX系OSでいうところの「バックグラウンドプロセス」の状態でアプリケーションを起動する。そのため、このような対応が必要になる。
今回取り上げた方法は、Microsoft Edgeのヘッドレスモードのみならず、さまざまなアプリケーションで使用できる。特に、PowerShellスクリプトに組み込んで自動的に処理を行わせたい場合は、このテクニックが役に立つことが多い。知っていると便利なので、今すぐ使わなくても覚えておいてもらえれば幸いだ。










