今回は、「正規分布」の基本的な考え方を解説していこう。一般的な統計処理では、データのばらつき具合が正規分布になっていると仮定して作業を進めていく。そのためには、まず「正規分布とはどのような分布なのか?」について学んでおく必要がある。なるべく簡単に説明するので、その概要だけでも把握しておくとよいだろう。
正規分布とは?
正規分布とは、データの分布を示すヒストグラムが以下の数式(確率密度関数)で示される分布のことを指す。
-
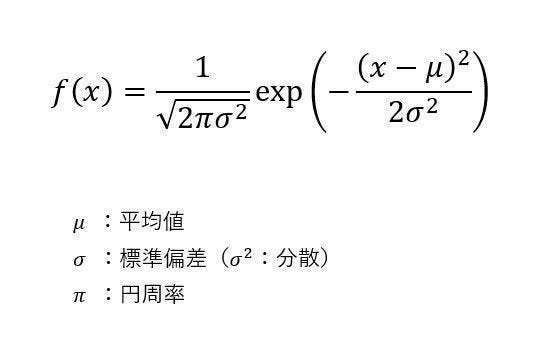
正規分布の確率密度関数

ただし、この数式を見ても「さっぱり内容を理解できない・・・」という方が大半を占めるであろう。でも、心配する必要はない。この数式の厳密な意味を理解できなくても、統計処理を進めていくことは可能である。それよりも「正規分布の特徴」を知っておくことが大切だ。
そこで、今度は、先ほどの数式をグラフ化してみよう。
-
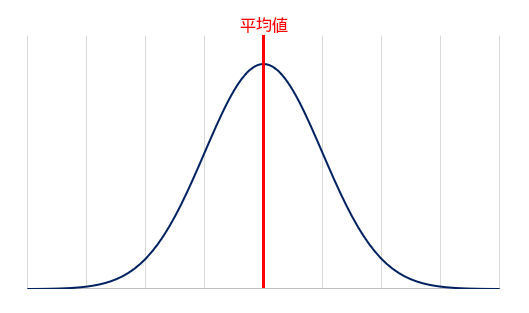
正規分布のグラフ

これで正規分布の特徴をある程度はイメージしやすくなったと思う。正規分布の主な特徴は、以下の2つとなる。
(1)平均値を中心に、データが左右対称に分布している
(2)平均値から離れるほどデータの頻度は低くなっていく
統計処理を行う際は、この2つの特徴を理解しておくことが重要だ。逆に考えると、最初に示した数式の意味を理解できなくても、上記の2つの特徴さえ理解していれば、統計学的に正しい処理を行えることになる。
通常、調査や実験などから得られるデータは、その多くが上に示したような「正規分布」になると考えられる。たとえば、成人男性の身長は170cm付近の人が最も多く、170cmから離れるほど、その頻度は小さくなっていくと考えられる。同様に、体重や50m走のタイムなども、平均値付近のデータが最も多く、平均から離れるほど頻度は小さくなっていくと考えられる。よって、これらは「正規分布になると考えられる事例」といえる。
正規分布の形状と標準偏差
正規分布は、「標準偏差」の値に応じて「尖った形状」や「平たい形状」に変化する。とはいえ、前回の連載で紹介した法則は常に成立する仕組みになっている。その法則とは、
◆(平均値)±(標準偏差×1)・・・約68%のデータが含まれる(※1)
◆(平均値)±(標準偏差×2)・・・約95%のデータが含まれる(※2)
◆(平均値)±(標準偏差×3)・・・約100%のデータが含まれる(※3)
というものだ。
※厳密には、(※1)約68.27%、(※2)約95.45%、(※3)約99.73%。
たとえば、平均値が150、標準偏差が5の正規分布は、以下の図のような「尖った形状」になる。
-
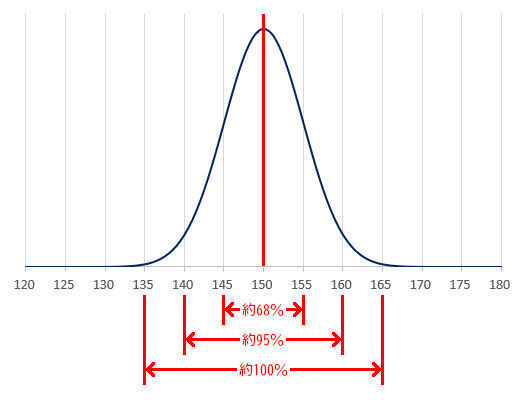
平均値150、標準偏差5のグラフ

この場合、145~155の範囲に約68%のデータ、140~160の範囲に約95%のデータ、135~165の範囲に約100%のデータが含まれることになる。
一方、平均値が150、標準偏差が10の正規分布は、以下の図のような「平たい形状」になる。
-
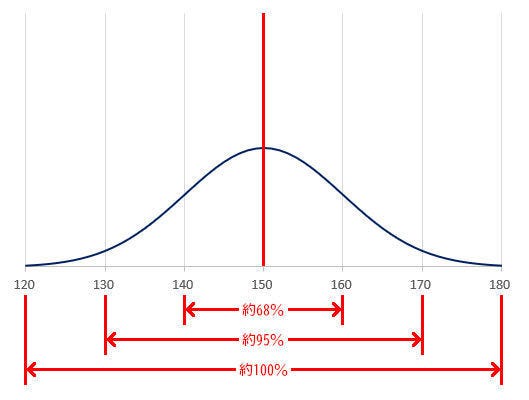
平均値150、標準偏差10のグラフ

この場合、140~160の範囲に約68%のデータ、130~170の範囲に約95%のデータ、120~180の範囲に約100%のデータが含まれることになる。
こういった法則を覚えてしまえば、標準偏差を「意味のある数値」として捉えることができるようになる。
より具体的な例で見ていこう。スポーツ庁が公表している「体力・運動能力調査(平成29年度版)」によると、12歳男子の50m走のタイムは、平均値8.42秒、標準偏差0.75秒という調査結果が報告されている。これを正規分布のグラフで示すと、以下の図のようになる。
-
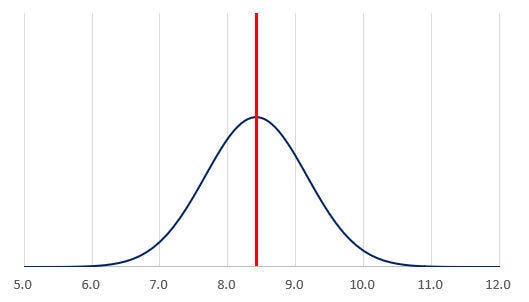
平均値8.42(秒)、標準偏差0.75(秒)のグラフ

このグラフを見ると、平均値を中心に6~11秒くらいの範囲に幅広くデータが分布していることが理解できる。先ほど示した法則に従うと、7.67~9.17秒の範囲に約68%、6.92~9.92秒の範囲に約95%のデータが含まれる、と予測することもできる。
今度は、18歳男子の50m走のタイムを示してみよう。こちらは平均値7.33秒、標準偏差0.48秒と報告されているので、その正規分布のグラフは以下の図のようになる。
-
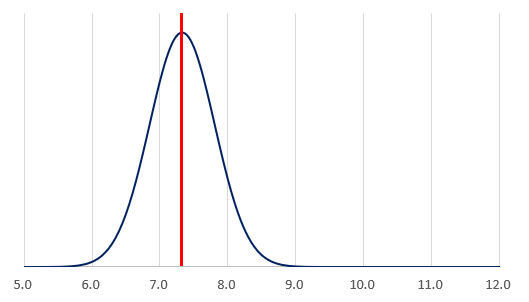
平均値7.33(秒)、標準偏差0.48(秒)のグラフ

12歳男子のデータと比べて全体的にタイムが速くなっているのは当然として、データの「ばらつき具合」が小さくなっいることも傾向の一つとして挙げられるだろう。こちらは、6.85~7.81秒の範囲に約68%、6.37~8.29秒の範囲に約95%のデータが含まれる、と予測できる。
このように、正規分布の特徴と法則について学んでおくと、平均値と標準偏差から「データのばらつき具合」を予測することが可能となる。公開されている統計データを読み取ったり、自分でデータを分析したりするときに役立つので、この機会にぜひ、覚えておくとよいだろう。
正規分布にならない事例
実験や調査から得られるデータの中には、「正規分布にならない事例」も存在する。このような場合、標準偏差などの指標は意味をなさない数値となることに注意しなければならない。
たとえば、サイコロを数百回ほど振って、その出目について集計してみたとしよう。この結果(ヒストグラム)は以下のようなイメージになる。
-
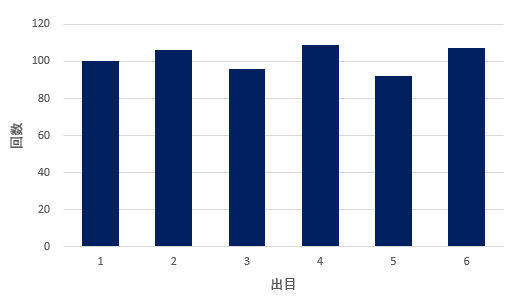
サイコロの出目と回数

サイコロが正しく製作されていた場合、1~6の目が出る確率はそれぞれ1/6となる。正規分布のように、3や4の目はよく出るが、1や6の目は滅多に出ない、というようなサイコロは不良品といえる。よって、サイコロの出目は正規分布にならないと考えられる。
もうひとつ例を紹介しておこう。以下の図は、ある音楽サービスの会員数を年齢別に調べた結果のヒストグラムとなる。ちなみに、このデータの平均値は約33.2歳であった。
-
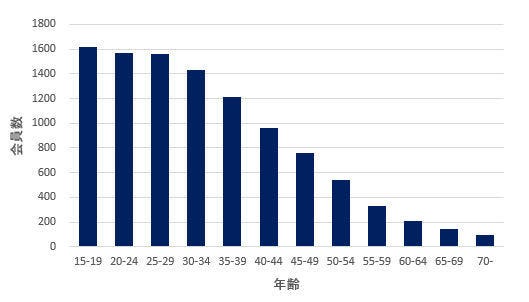
会員の年齢分布

この場合、「最も頻度が多い15~19歳のデータ」と「平均値の約33.2歳」の位置が大きくズレているため、正規分布になるとは言い難い。よって、前述した法則は当てはまらない。
そのほか、複数の事例が混在している場合も注意が必要だ。たとえば、成人の身長について調査を行い、その結果をヒストグラムにすると、以下の図のようなイメージになる。
-
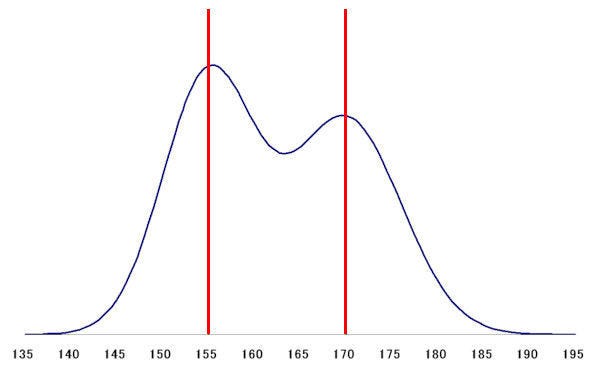
成人の伸長

男性の平均身長は170cm前後、女性の平均身長は155cm前後になるため、上図のように2カ所か凸型になったグラフになる。これも正規分布とは言えない。このような場合は、男性と女性を切り分けて統計処理を行わなければならない。
このように、一般的な統計理論に従って処理を行うときは、「そのデータが正規分布になると考えられるか?」を事前に調べておく必要がある。厳密に調べるのは難しいので、少なくとも、
・平均値付近の頻度が最も高く
・平均値から離れるほど頻度が小さくなる
の2点については考慮しておく必要があるだろう。それほど厳密に考える必要はないが、統計処理の基本ともいえる内容なので、頭の片隅にでも覚えておくとよいだろう。