フランクフルトで開催されたISC 2018において、「Upcoming Exascale Computing」と題するセッションが行われた。米国、日本、ヨーロッパ、中国のExascaleプロジェクトのキーマンが登壇して、それぞれの地域のプロジェクトの状況を発表した。
米国の発表者はExascale Computing Project(ECP)のディレクタであるORNL(Oak Ridge National Laboratory)のDouglas Kothe氏である。日本の発表者は理研の計算科学研究センターのソフトウェア研究チームのチームリーダーの石川裕氏、ヨーロッパはBCS(Barcelona Supercomputing Center)のSergi Girona氏である。中国はNUDT(National University of Defense Technology)のKai Lu氏が発表する予定であったが、急病とのことで、NUDTのRuibo Wang氏が代わって登壇した。
なお、写真の下から顔が出ているのは、このセッションのチェアであるNUDT/National Supercomputer Center in GuangzhouのYutong Lu教授である。
-

Upcoming Exascale Computingのセッションの発表者

日本のPost-K開発の状況
理研のCenter for Computational Scienceの石川裕氏が登壇して、日本のPost-Kの状況を説明した。
-

Post-Kの開発状況を発表する石川裕氏

Post-Kプロジェクトのミッションは、次期フラグシップであるPost-Kスパコンを開発し、そして、社会的、科学的な問題を解くPost-Kで走らせるアプリケーションを開発することである。
Post-Kの開発は理研が責任者であり、富士通がベンダパートナーという位置づけになっている。そして、米国や欧州の研究機関とも協力して研究を行っているという。アプリケーションとしては9つの社会的、科学的に重要性の高いアプリケーションと4種の先端的研究分野の研究課題とそれぞれの課題の担当機関を選択している。
現在の開発状況は、富士通において、最初のプロトタイプCPUがパワーオンされ、評価が始まっている。また、ソフトウェアスタックの実装と選択されたアプリケーションのチューニングが行われているという。
図の下側に書かれた工程表では、設計と実装の終了まで、あと1年となっており、ハードウェアの開発としては、順調のようである。
-

Post-Kプロジェクトの概要。日本のフラグシップスパコンとその上で動く広範なアプリケーションを開発する。2021年度Q3に運用を開始する計画である (この連載のすべての図は、ISC 18におけるUpcoming Exascale Computingのセッションでの発表資料のコピーである)

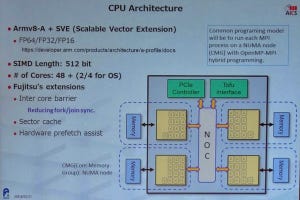
Post-KのCPUアーキテクチャはArm v8-A+SVE(Scalable Vector Extension)である。京コンピュータはSPARCアーキテクチャであるが、SPARCのサポーターが減り、標準ディストリビューションも作られなくなってきている状況である。一方、ARM v8-Aアーキテクチャは標準ディストリビューションがあり、HPC分野でも使われ始めている。標準ディストリビューションに乗っかればソフトの流通も容易になるので、Armアーキテクチャを採用することにしたという。
富士通の実装ではSVEのベクタ長は512bitで、FP64、FP32に加えてAI分野向けのFP16もサポートする。チップ当たりの計算コア数は48で、OSを走らせるサポートコアを2コア、あるいは4コア搭載する。計算コアからOS処理などをオフロードしてOSジッタを減らすのは京コンピュータから採用されている方式である。
CPUチップのメモリバンド幅と演算性能の比であるByte/Flopは0.4程度ということで、0.5であった京コンピュータよりは若干減っているが、最近の大型スパコンとしては圧倒的にメモリバンド幅の大きい設計となっている。
そして、富士通の独自の拡張として、コア間バリア機能、セクタキャッシュ、ハードウェアのプリフェッチアシストなどを持っている。
右下の写真は,下側の2個のコールドプレートがCPUのもので,上側の不規則な形をしたコールドプレートはI/OノードのLSIを冷却するものとのことである。なお、メインメモリにはMicronのHybrid Memory Cube(HMC)を使っており、メモリバンド幅は広いが容量はDIMMほどには大きくは出来ないと言う割り切りになっている。
MicronのデータシートではHMC 1個当たり最大160GB/sのメモリバンド幅となっており、富士通のFX100スパコンと同様に8個のHMCを使っているとすると、CPUチップあたり1280GB/sのメモリバンド幅で2.4PFlops程度の演算性能と思われる。
とすると、コア当たり67GFlopsで、512bit SIMD演算であるので、クロックは4.17GHz程度という計算になる。あるいはHMCのバンド幅はもう少し小さく、それに比例してクロックももう少し低いのかも知れない。
-

Post-KのCPUアーキテクチャはARM v8+SVEで、それにコア間バリアなどの富士通の拡張を追加している。チップあたり48個の計算コアと2個あるいは4個のOS用コアを持つ。右下の写真は、2CPUを搭載する水冷のボード

Post-KではCompute NodeとCompute Node + IO Nodeというものがあり、IO Nodeからは1st Storageという箱が繋がっている。この部分のノードは6次元のメッシュ/トーラス構造のTofuネットワークで接続される。
1st Storageはグローバルファイルのキャッシュやシステムのテンポラリファイルなどに用いられる。そして、I/Oネットワークを介してLustreのグローバルファイルシステムとアーカイブ用のストレージが接続される。
-

計算ノードだけのノードと計算+IOノードがあり、これらを6次元メッシュトーラスのTofuインタコネクトで接続する。ストレージは3階層になっている。

ソフトウェアスタックの最下層は、LinuxとMcKernelと呼ぶ軽量カーネルを使う。その上に低レベルの通信やファイルIOなどの層がありXMPやFDPSなどの並列プログラミング環境、通信用のMPIやアプリケーション向きのファイルI/Oが載る。
その上でFortran、C/C++などのコンパイラ、数値計算ライブラリ、チューニングやデバグツール、バッチジョブシステム、階層的ファイルシステム、並列ファイルシステムが動く。
Post-Kのソフトウェアスタックでは、いわゆる性能だけでなく、使い易さも我々のシステムのカギとなる性能指標であるという。
-

Post-Kシステムのソフトウェアスタックの概要。計算ノードはMcKernelという軽量カーネルを使い、I/OノードではLinuxカーネルを使う。それらの上に各種ライブラリやツールなどが載っている

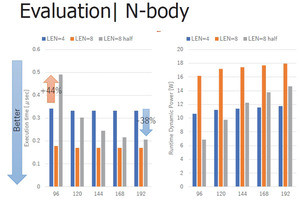
米国のCORALシステムで使ったminiFEというベンチマークの性能のスケーリングを測定したのが次の図である。棒グラフの右側の棒が軽量のMcKernel、左の棒はLinuxカーネルで同じバイナリを走行させた場合のMFlopsを表す。なお、このデータはOakforest-PACSで測定されたものである。
この図に見られるように、Linuxでも32Kコアまでは性能が向上しているが、Linuxを使った場合は、64Kコアでは逆に性能が下がっている。一方、McKernelでは64Kコアでも性能は伸びており、McKernelでの性能はLinux Kernelの場合と比較して3.5倍の性能が得られている。
-

miniFEというベンチマークを1024コアから64Kコアまで並列に動作させた場合の性能。左の棒グラフはLinuxカーネル、右の棒はMcKernelで動作させた場合で、McKernelはCPUコア数が多くなっても性能がスケールしている

ソフト開発や移植のサポートという点では、秋口からハードウェアの詳細情報の開示を始める。最適化のガイドブックはすでに一部が公開されているが、2019年にかけて充実していく。
また、FX100を使った性能推定や評価環境として使われるRIKENシミュレータの開発も継続して実施する。
そして、2020年度の第2四半期にアーリーアクセスを開始し、2021年度の第1/第2四半期に正式稼働を開始する予定であるという。
-

ソフトウェアの開発/移植工程。2020年度Q2からアーリーアクセスを開始する予定となっている

(次回は7月25日に掲載します)