A64FXのPEは512bit幅のSIMD演算パイプラインを2本持ち、A64FXチップは48個のコアを集積している。したがって、64bitの倍精度浮動小数点で2.7TFlops以上の演算性能となっている。
そして、32bitの単精度浮動小数点数、16bitの半精度浮動小数点数と整数、8bitの整数のSIMD演算も実行でき、単精度浮動小数点では5.4TFlops以上、16bitの半精度浮動小数点と16bit整数では10.8TOPs以上、8bit整数では21.6TOPs以上という性能となる。
なお、右側の絵はINT8の内積計算を示すもので、各要素同士の積を計算し、それらすべての総和を求めるという演算を行う。ただし、この図ではスペースの関係で4要素しか書かれていない。
-

FP64では2.7TFlops以上の性能を持ち、FP32では5.4TFlops以上、INT16では10.8TOPs以上、INT8では21.6TOPs以上という高い性能を持つ

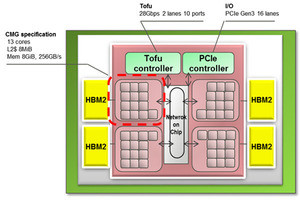
A64FX CPUでは13コアとキャッシュとHBM2メモリコントローラをまとめたCMGが基本単位である。CMGの中の13コアとL2キャッシュは、左の図のようにクロスバで接続されている。そして、4つのCMGは、右の図のようにリングバスで接続されている。なお、すべてのコアのキャッシュはキャッシュコヒーレントになっている。
-

13コアとL2キャッシュはクロスバでの接続。4つのCMGとTofuコントローラ、PCIeなどはリングバスで接続されている

次の図はA64FXのメモリ系のバンド幅を示すものである。各コアは64KBのL1データキャッシュを持ち、L1データキャッシュは、230GB/s以上のバンド幅でSIMD演算器にデータを供給し、115GB/s以上の速度で演算結果をL1データキャッシュに格納する。2.7TFlopsの計算に合計345GB×4×48=66.24TB/sのデータ入出力であるので24.5B/Flopsという計算になる。このため、2つの8バイトオペランドの読み出しと、1つの8バイトの結果オペランドの書き出しをすべてL1データキャッシュで賄うことができるバンド幅になっている。
L2キャッシュは13コアに共通で、容量は8MBで16wayになっている。そして、各コアに対するデータバンド幅は、L1データキャッシュの半分となっている。
CMGの間の接続は各CMGのL2キャッシュ間を接続する115GB/sのリングバス2本で行われている。そして、L2キャッシュはCMGごとにHBM2メモリに接続されている。HBM2メモリのバンド幅は256GB/sであり、A64FX全体のメモリバンド幅は1024GB/sとなっている。
-

コアごとにL1データキャッシュは存在し、読み出しバンド幅は230GB/s以上、書き込みバンド幅は115GB/s以上となっている。L2キャッシュはCMGに含まれる全コアで共用となっている。4つのCMGは、>115GB/s×2のリングバスで接続されている

L2キャッシュとリングバスとの接続は、次の図のようになっている。
-

リングバスはL2キャッシュにつながっており、HBM2にもつながっている

A64FXでは1つのCMGがローカルにタグを持ち各キャッシュラインの状態を管理している。そして、CMG外に持ち出されたキャッシュラインは、 TagDと呼ぶ輸出ディレクトリを使ってccNUMA(cache coherent Non Uniform Memory Architecture)として管理している。
IntelのCPUなどではHome Agentと呼ばれるブロックがあり、それがメインメモリなどに置かれたディレクトリにキャッシュラインの他のチップへの輸出状況を記録して管理を行っているが、A64FXではL2キャッシュ上に置かれた輸出用のTagDディレクトリを使う。このやり方で、Home Agentを使う場合と比べてハードウェアが30%減らせ、電力が減るという。さらに、TagとTagDのパイプラインを連結したことで、キャッシュヒットの場合のレーテンシも短縮できたという。
-

CMG外に持ち出されたキャッシュラインはTagDと呼ぶ輸出ディレクトリで管理する。この方法はHome Agentを使うのに比べて30%ハードウェアが少なくて済むという

次の図の左側の黒の矢印は、CMG0のコアがCMG0のメモリからロードを行った場合を示し、メモリが読まれたCMGのL2キャッシュに入ると同時にTagなどの附属情報はローカルのL2キャッシュTagに記憶される。
赤線の矢印は、CMG1のコアが、CMG0のメモリをアクセスした場合で、データはCMG1のL2キャッシュに送られる。そして、そのデータがCMG1に輸出されているという情報がCMG0のTagDには記憶される。同時にCMG1のL2キャッシュに記憶されたデータのTagなどの情報はCMG1のローカルTagにも記憶される。
-

他のCMGに輸出されたキャッシュラインの情報はTagDに記憶して管理する。この方法はHome Agentを使う方法に比べて必要なハードウェアが30%少なくて済む

通常のCPUでは、左の図のようにメモリアクセスはHome Agentに送られ、HAがセントラルディレクトリを見て、データがどこにあるかを見つけてメモリアクセスを行い、読まれたデータのリード要求を出したCMGに送る。これに対してA64FXでは、リード要求を出したCMGのTagとTagDを読めばデータの在りかがわかるので、(2)のステップを省くことができる。
-

通常のHome Agentを使う方式ではキャッシュタグを読んだ後に(3)でメモリ上にあるセントラルディレクトリを読む必要があるが、A64FXでは(1)で輸出したキャッシュラインを管理するTagDも読み込んでしまうので、(2)のステップを省ける

(次回は5月9日に掲載します)