今回は「抽出」コマンドの使い方を紹介していこう。このコマンドを使うと、既存のデータから“指定した部分”だけを抜き出すことが可能となる。第14回の連載で紹介した「列の分割」と似ている部分も多いので、あわせて覚えておくと、より柔軟にパワークエリを活用できるようになるだろう。
文字列の一部を抜き出して「新しい列」を作成
今回は「抽出」というコマンドの使い方を紹介していこう。「列の分割」が“指定した位置で列を分割する機能”であるのに対して、「抽出」は“指定した部分だけを抜き出す機能”と考えると理解しやすいだろう。
-

既存の列からデータを抽出

具体的な例で見ていこう。以下の図は、「Source.Name」(ファイル名)のデータから「X月X日」の部分だけを抽出した例だ。このように“既存の列”から“必要な部分”だけを抜き出したいときに活用できる機能が「抽出」となる。
-
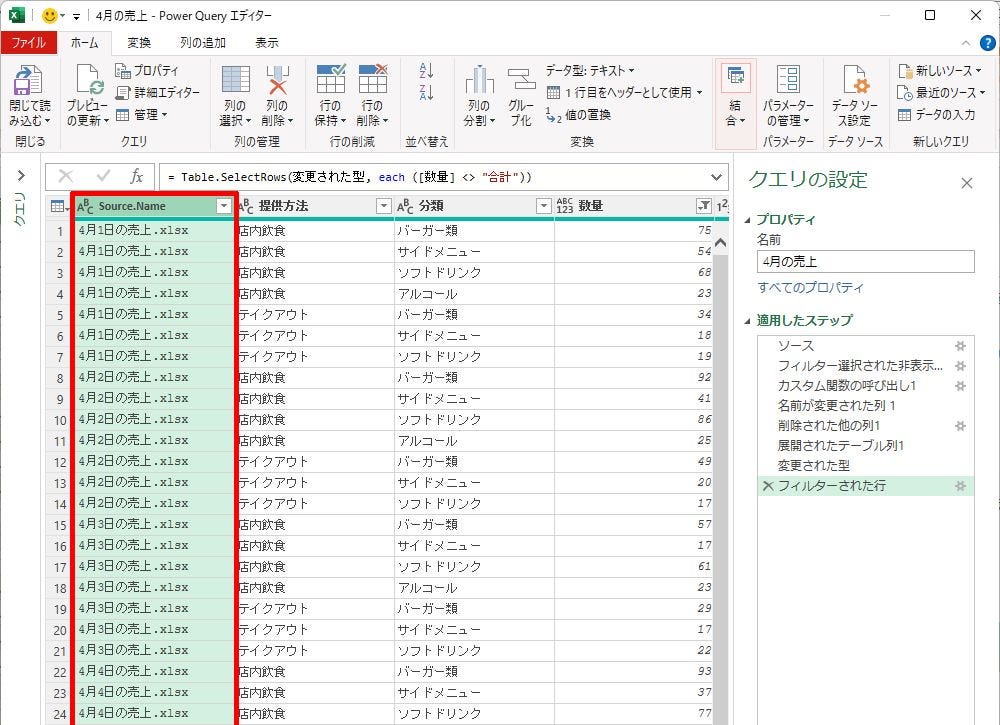
既存の列

-
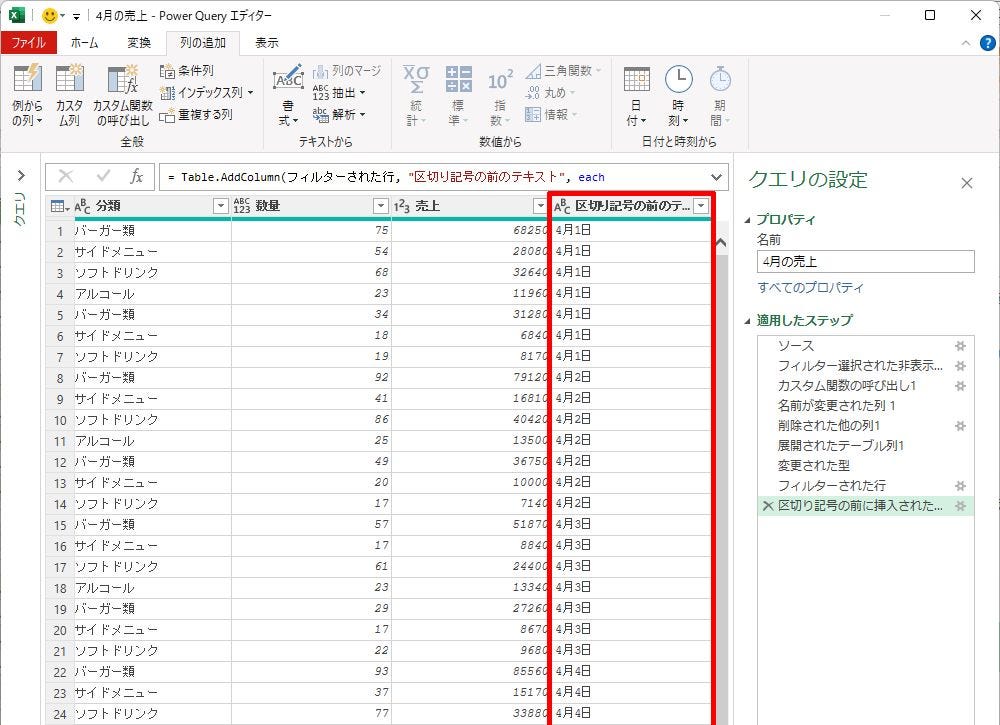
「X月X日」の部分だけを抽出した列

ちなみに、「抽出」コマンドは「変換」タブと「列の追加」タブの両方に用意されている。パワークエリを上手に活用していくには、両者の違いについても理解しておく必要がある。
「区切り記号」を指定してデータを抽出する
それでは、「抽出」コマンドの具体的な使い方を紹介していこう。まずは、特定の文字を「区切り記号」に指定してデータを抽出する方法だ。
データの抽出元となる列を選択し、「列の追加」タブを選択する。続いて、「抽出」コマンドをクリックして抽出方法を選択する。「区切り記号」を基準にデータを抽出するときは、以下の図に示した3項目の中から抽出方法を選択すればよい。
-
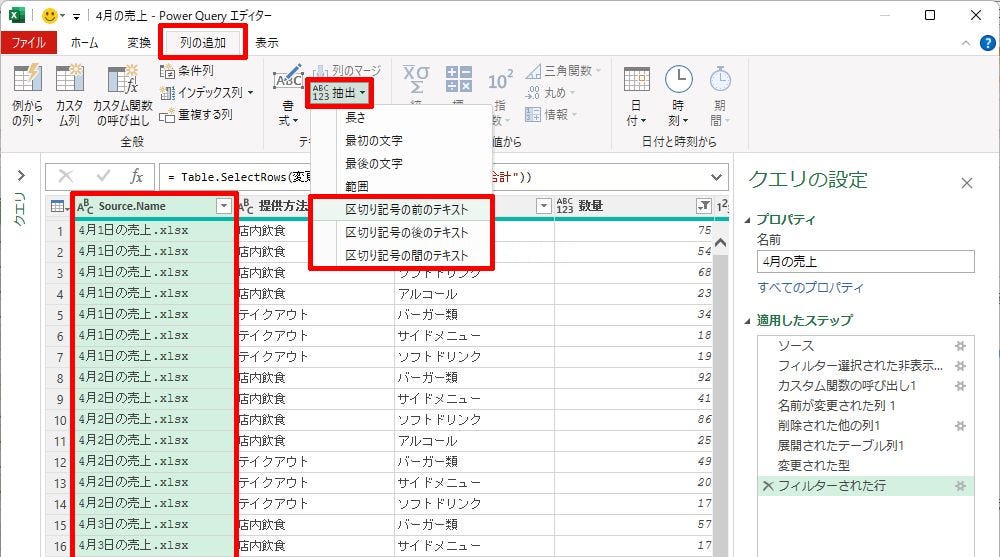
「列の選択」と「抽出方法の指定」

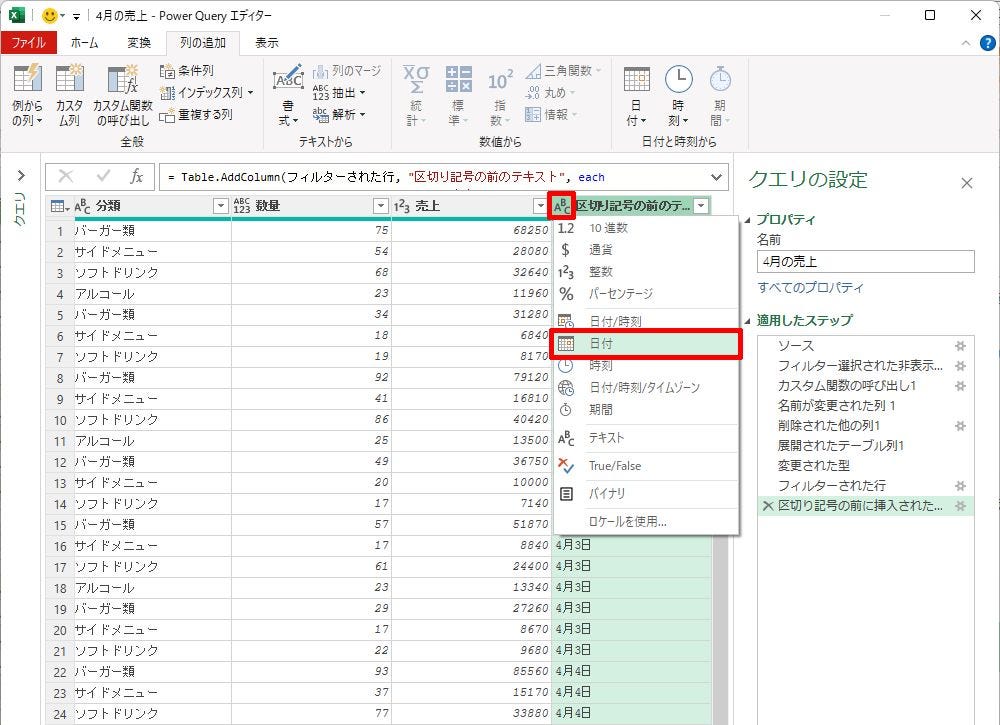
ここでは「区切り記号の前のテキスト」を選択した場合を例に操作手順を紹介していこう。抽出方法を選択すると、「区切り記号」を指定する画面が表示される。今回は「X月X日」の部分だけを抽出したいので、「の」より前のデータを抽出すればよい。よって、「の」と入力して「OK」ボタンをクリックする。
-
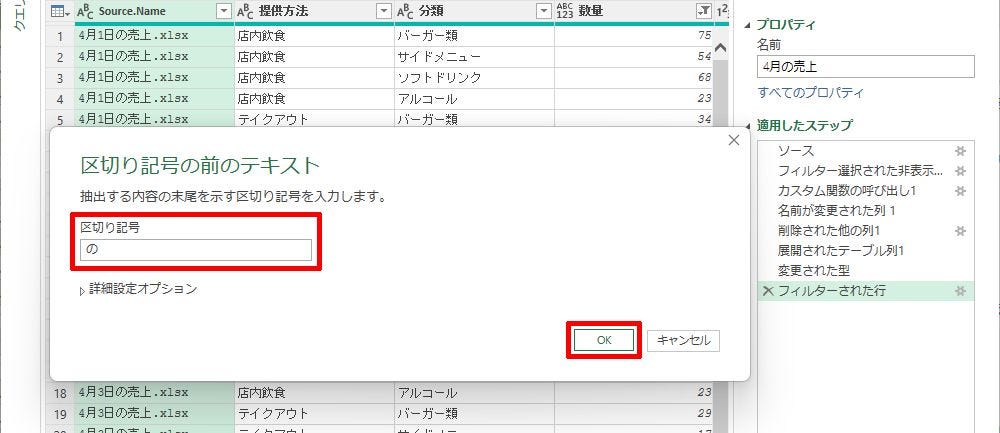
区切り記号の指定(1)

このとき、区切り記号に“複数の文字”を指定することも可能だ。今回の例の場合、区切り記号に「の売上」を指定しても同様の結果を得ることができる。
-
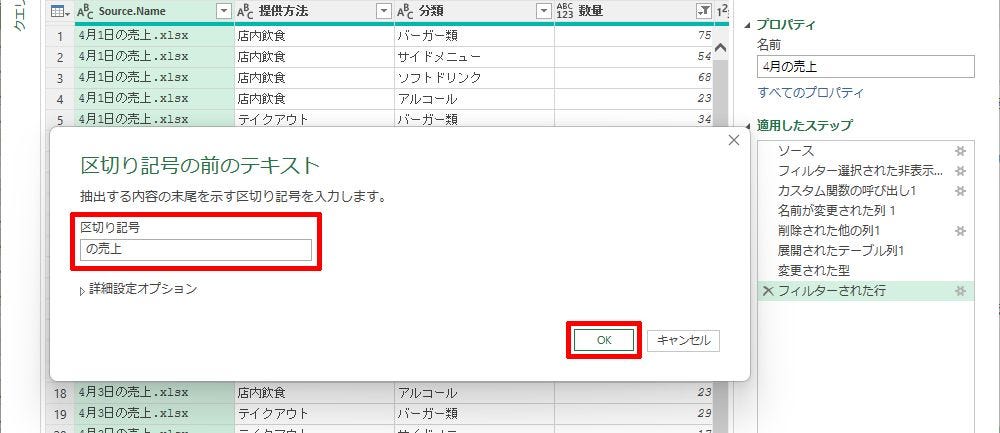
区切り記号の指定(2)

「OK」ボタンをクリックして処理を実行すると、データ表の右端に「新しい列」が追加され、そこに“抽出したデータ”が表示される。
-
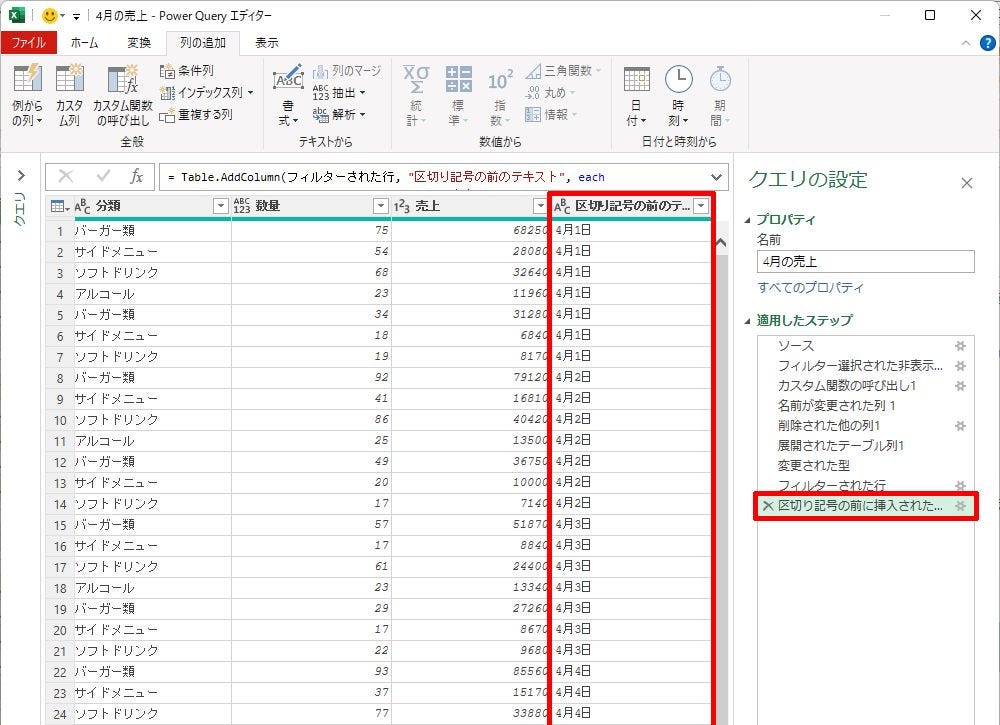
抽出されたデータ(新しく追加された列)

以上が「抽出」コマンドの基本的な使い方となる。難しい話は特にないので、すぐに使い方を覚えられるだろう。
ただし、抽出したデータは「テキスト型」のデータとして扱われることに注意しなければならない。抽出したデータを日付データとして扱いたい場合などは、自分でデータ型を指定しなおす必要がある。
-
データ型の変更

前述した例とは逆に、“特定の文字”より後にある文字だけを抽出することも可能だ。この場合は、抽出方法に「区切り記号の後のテキスト」を選択して操作を進めていけばよい。
抽出方法に「区切り記号の間のテキスト」を選択した場合は、以下の図のように2つの「区切り記号」を指定する設定画面が表示される。
-
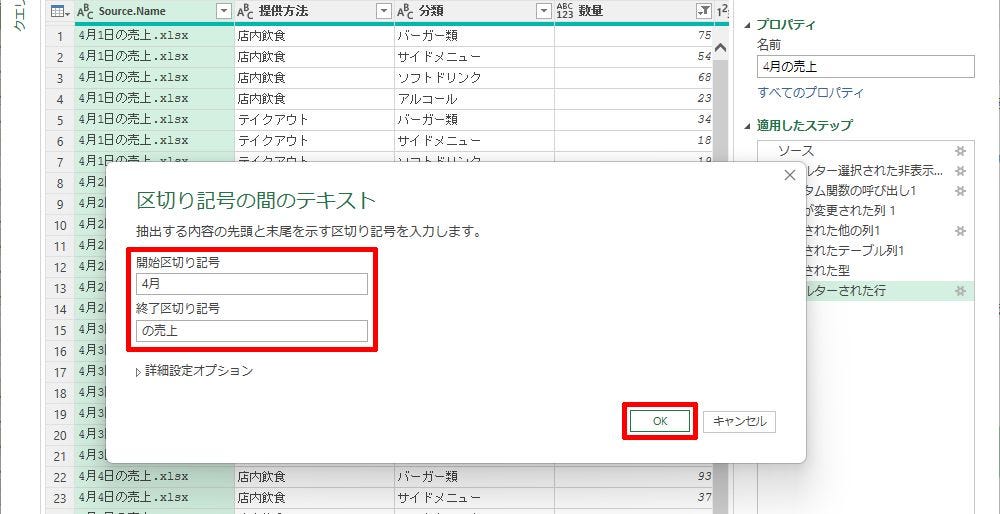
「区切り記号の間のテキスト」の設定画面

たとえば、「4月」と「の売上」を区切り記号に指定すると、「4月」と「の売上」の間にある文字だけを抽出することが可能となる。結果として、「X日」の部分だけを「新しい列」に抽出できることになる。
-
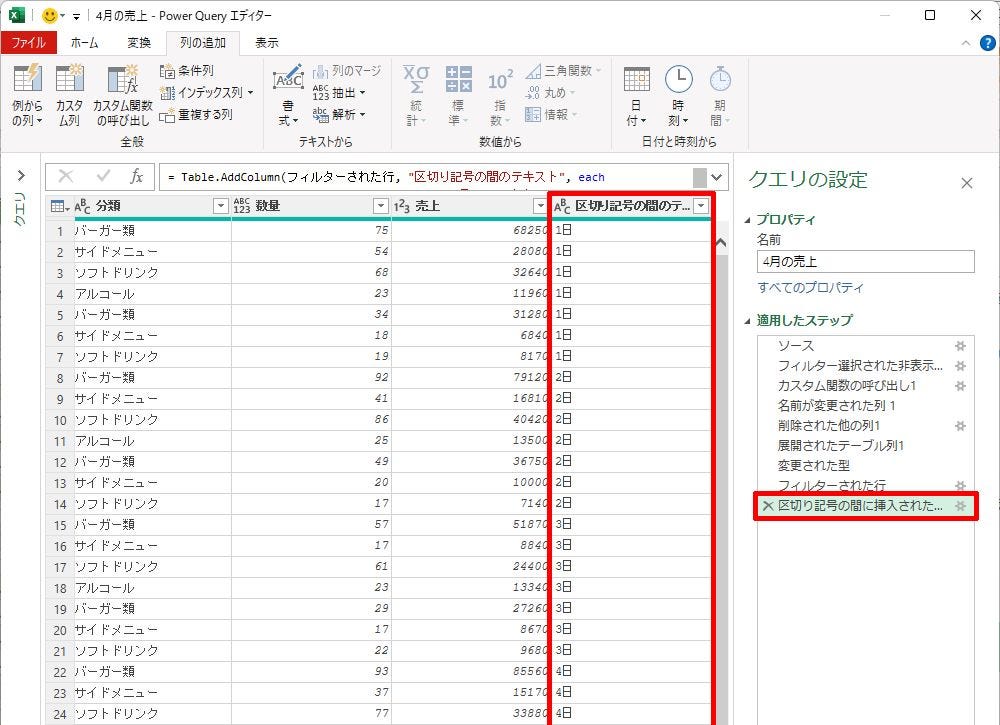
抽出されたデータ(新しく追加された列)

「文字数」を指定してデータを抽出する
“特定の文字”ではなく、“文字数”を基準にデータを抽出する方法も用意されている。この場合は、以下の図に示した3項目の中から抽出方法を選択すればよい。
-
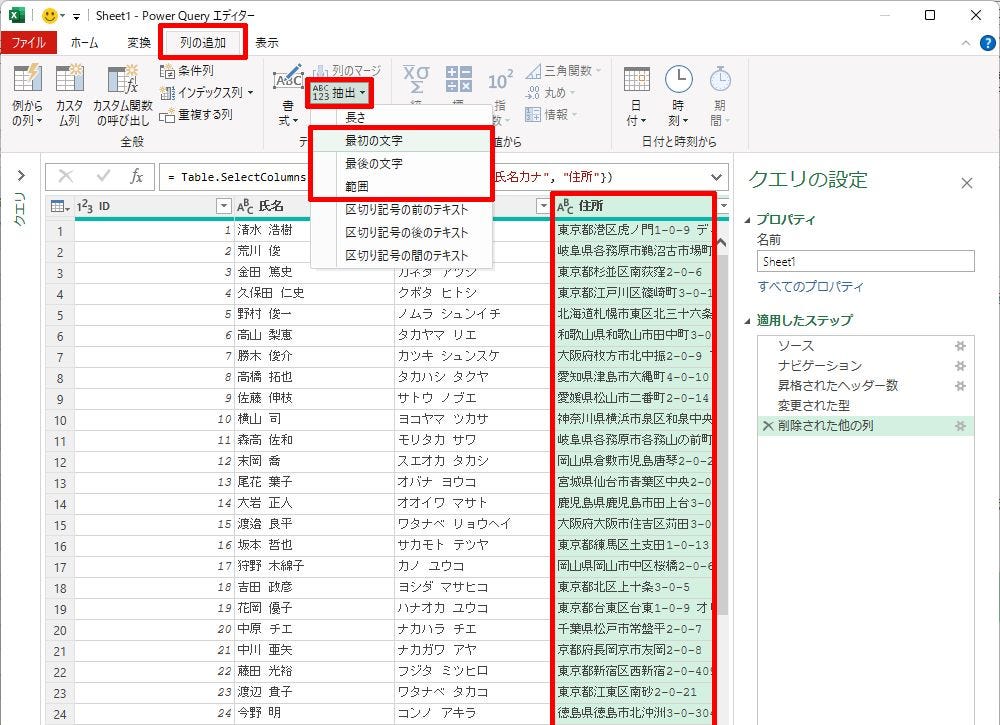
「列の選択」と「抽出方法の指定」

ここでは、「住所」の列から「都道府県」だけを抜き出す場合を例に操作手順を解説していこう。“先頭からN文字”のデータを抽出するときは「最初の文字」を選択し、抽出方法の設定画面で「文字数」を指定すればよい。今回の例では「3」を指定して、「OK」ボタンをクリックする。
-
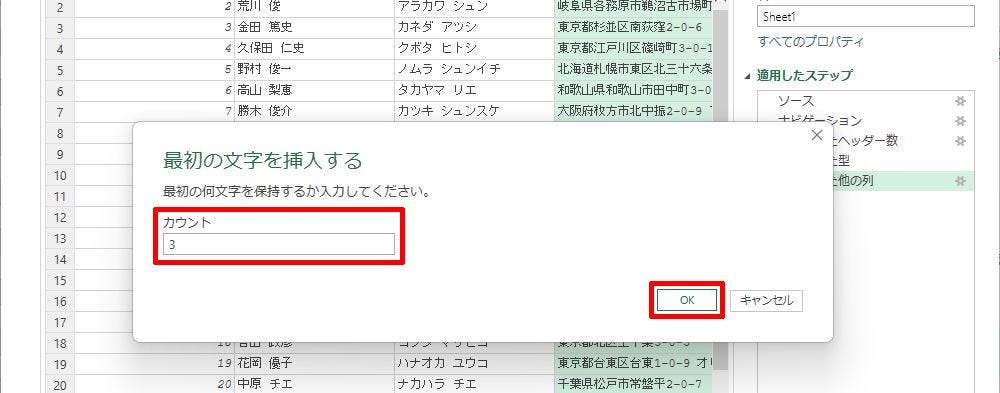
抽出する文字数の指定

すると、「先頭から3文字」を抽出したデータで「新しい列」を追加することができる。
-
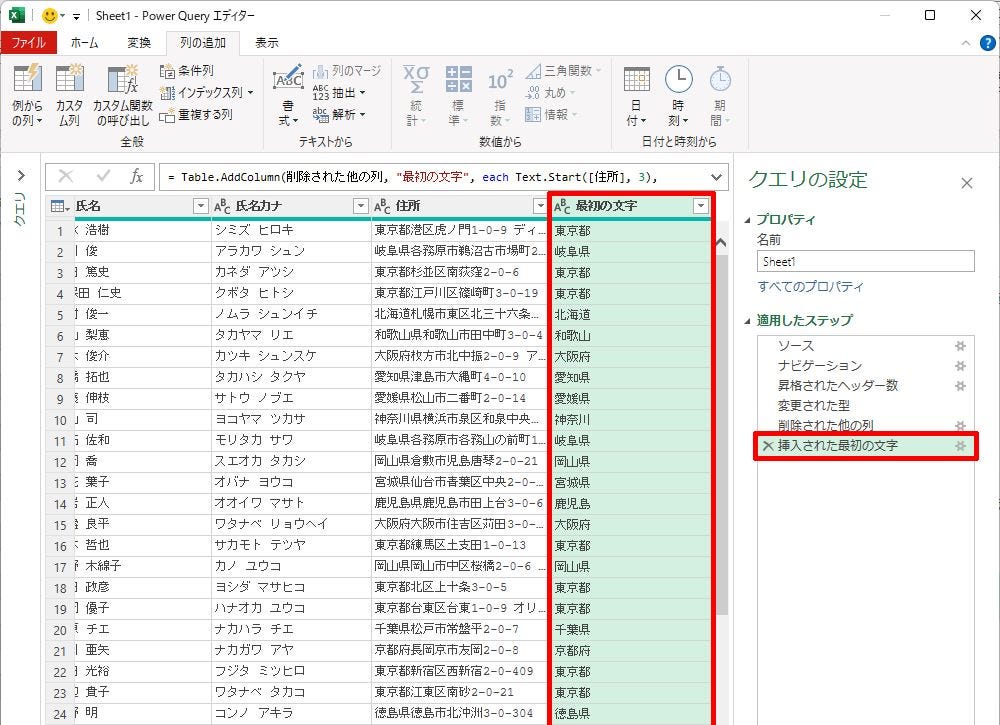
抽出されたデータ(新しく追加された列)

以降の操作手順は、第15回の連載で紹介した内容と同じだ。「値の置換」コマンドを使って、県名が4文字になる都道府県に「県」の文字を追加してあげればよい。具体的には、「神奈川」→「神奈川県」、「和歌山」→「和歌山県」、「鹿児島」→「鹿児島県」といった3つの置換を行えばよい。
-
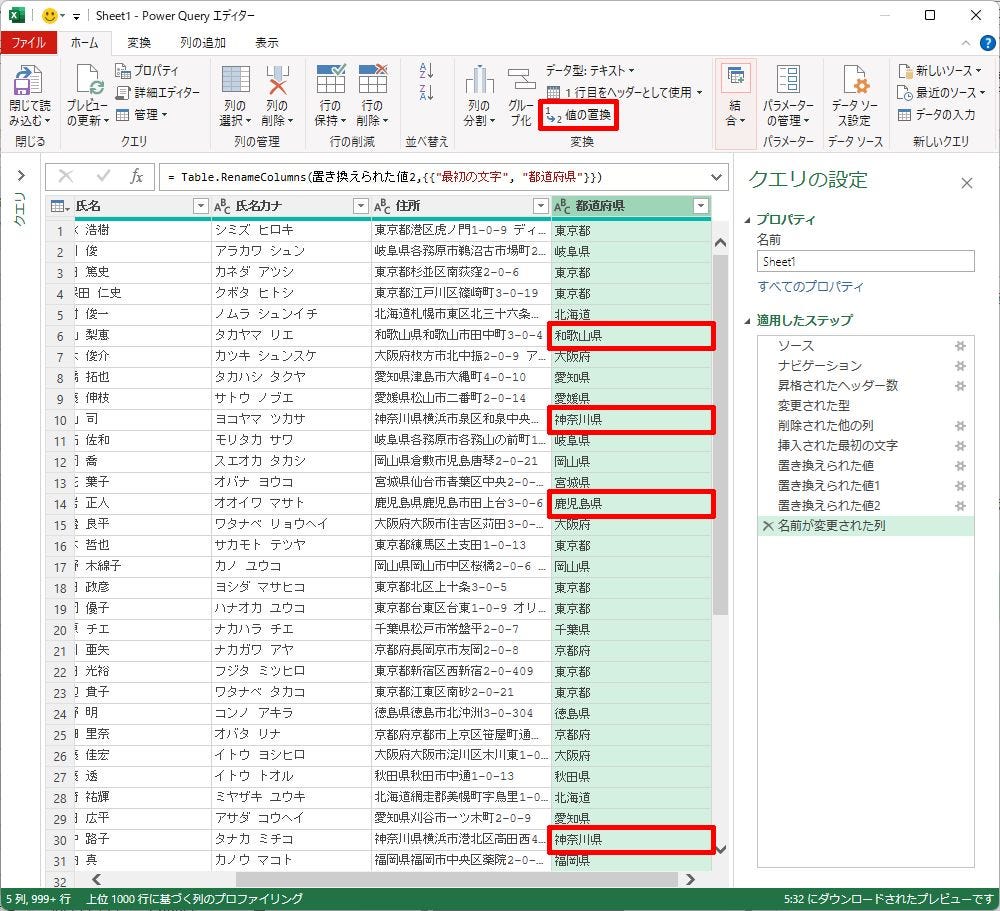
「値の置換」を使って「県」を追加した例

同様に、データの“末尾からN文字”を抽出することも可能だ。この場合は、抽出方法に「最後の文字」を選択し、抽出する「文字数」を指定する。
抽出方法に「範囲」を指定した場合は、「先頭のN文字を除いてM文字分」のデータを抽出できるようになる。たとえば、「先頭の3文字を除いて50文字分」のデータを抽出するときは、以下の図のように数値を入力すればよい。
-
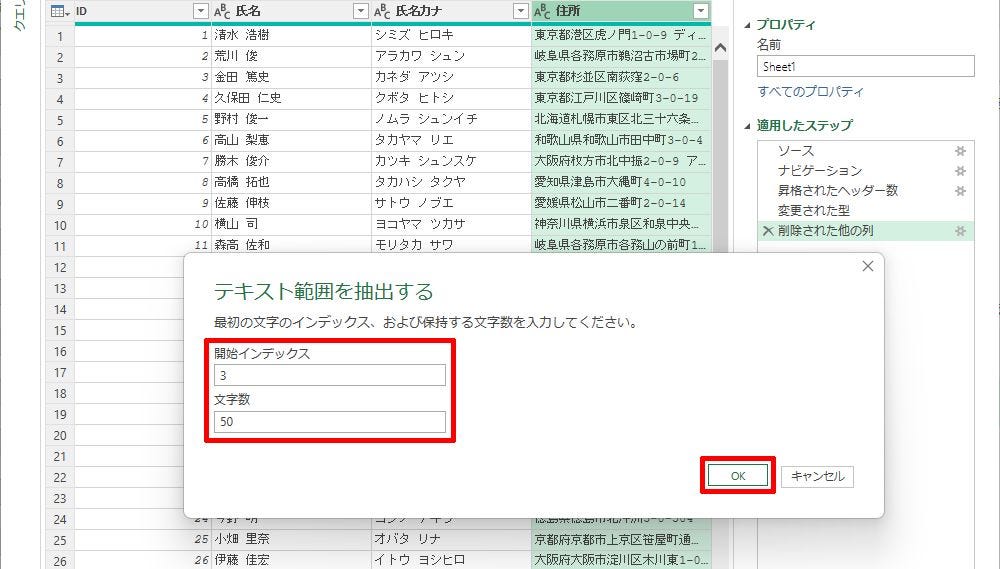
「範囲」の設定画面

すると、「4文字目から50文字分」を抽出したデータで「新しい列」を追加することができる。抽出するデータが50文字に満たない場合は、「4文字目から最後まで」のデータが抽出されることになる。
-
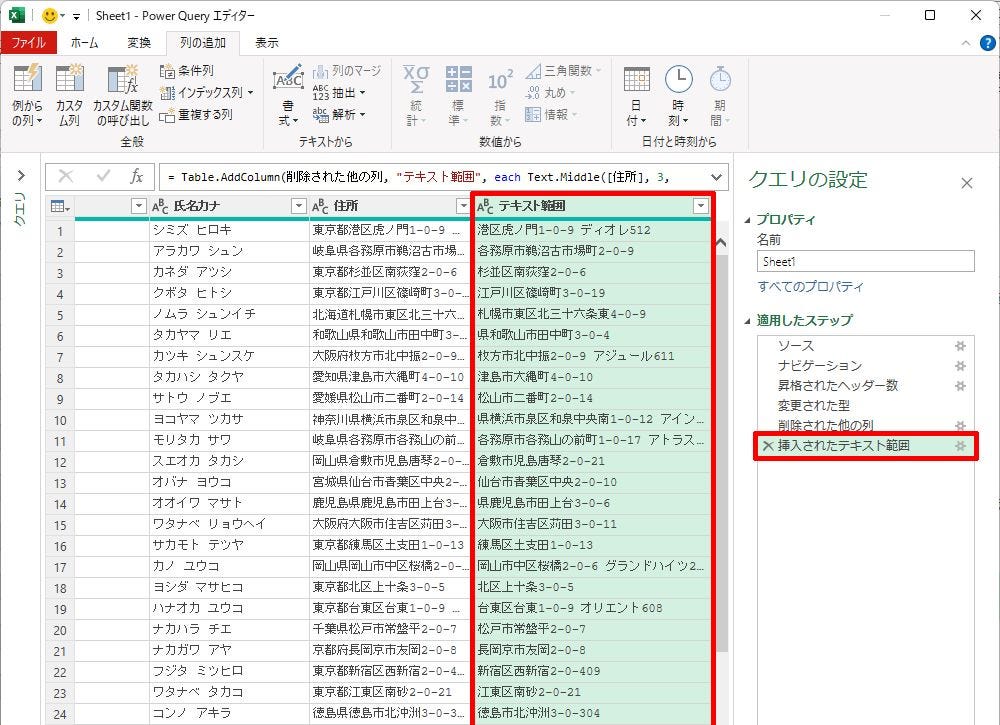
抽出されたデータ(新しく追加された列)

この抽出結果は、その大半が「都道府県以降の住所」になる。ただし、県名が4文字になる住所は、最初に「県」の文字が残ってしまう。この「県」の文字を削除すると、全データを「都道府県以降の住所」として扱えるようになる。
先頭にある「県」を削除する手順は第15回の連載で詳しく解説しているので、よく分からない方はあわせて参照しておくとよいだろう。これで、以下の図のような結果を得ることができる。
-
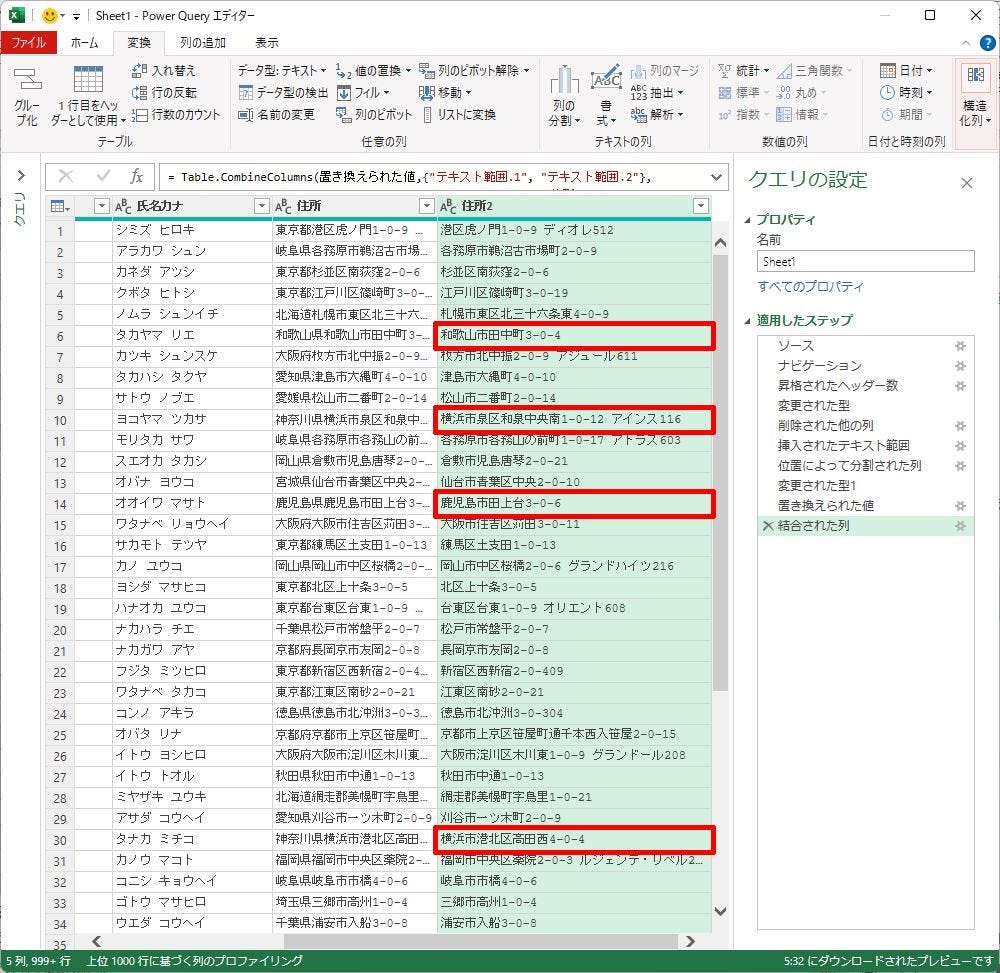
先頭の「県」を削除した例

このように、「抽出」コマンドを使って「住所」から「都道府県」や「それ以降の住所」だけを抜き出す方法もある。関数を使用する方法よりも「手軽で理解しやすい」と感じる方が多いのではないだろうか? 文字列データを処理するときの参考にして頂ければ幸いだ。
「変換」タブにある「抽出」コマンド
これまでは「列の追加」タブにある「抽出」コマンドの使い方を解説してきたが、「変換」タブにも「抽出」コマンドが用意されている。続いては、「列の追加」タブと「変換」タブの違いについて補足しておこう。
-
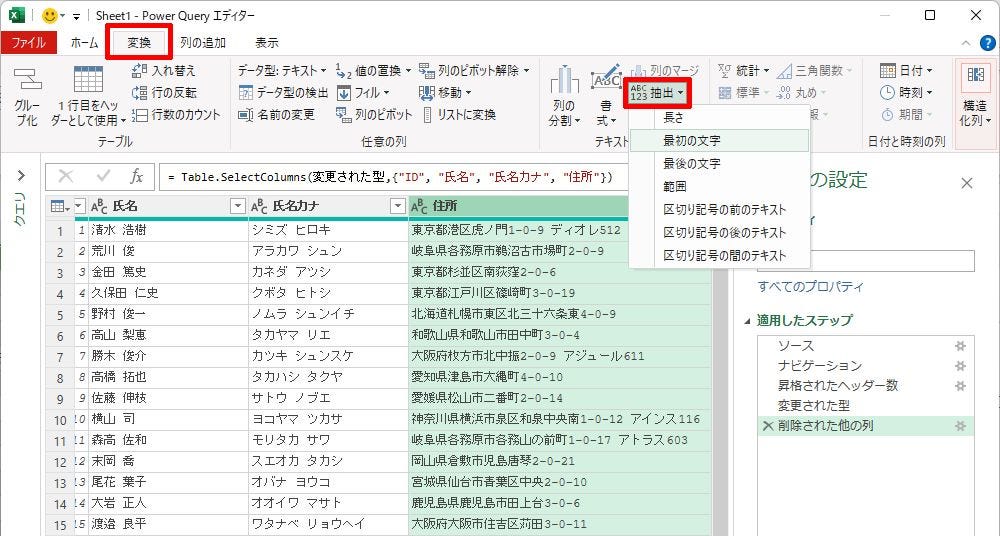
抽出方法の指定

「変換」タブにある「抽出」コマンドも基本的に同じ操作手順で使用できる。ここでは、抽出方法に「最初の文字」を選択し、「先頭から3文字」のデータを抜き出した例を紹介しておこう。
-
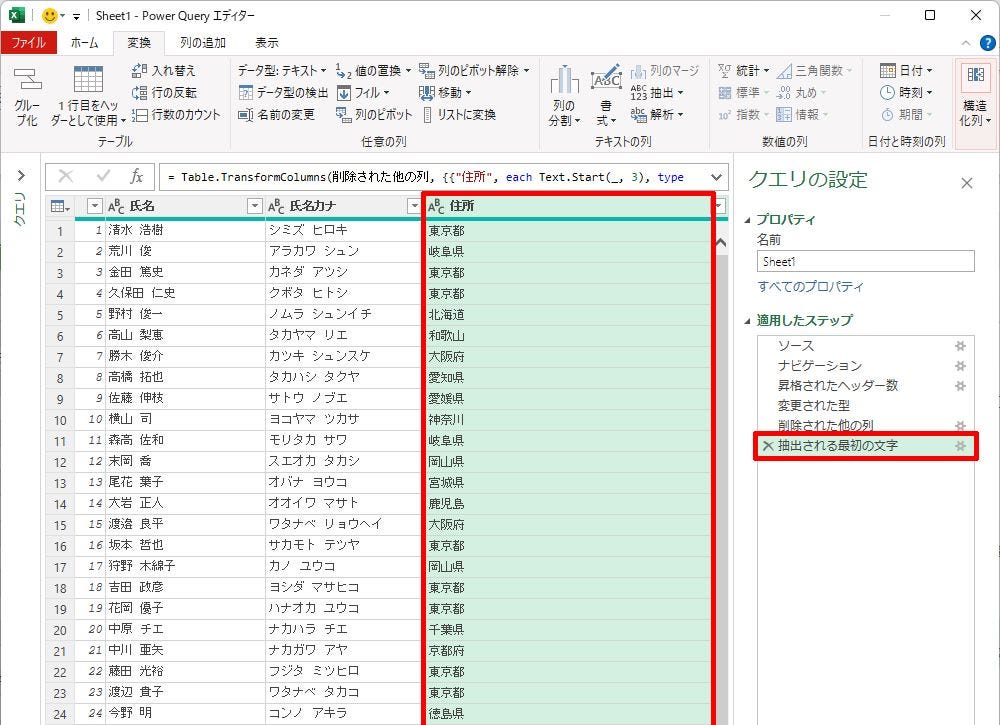
抽出されたデータ(既存の列の置き換え)

「変換」タブの場合は、「新しい列」が追加されるのではなく、抽出元の列が「抽出後のデータ」に置き換わる仕組みになっている。上図の場合、「住所」のデータが「最初の3文字」のデータに置き換えられることになる。
データ表を加工する目的が「都道府県で分類すること」であった場合、「都道府県」のデータを抽出できたら「住所」の列は不要になるはずだ。これを「列の追加」タブにある「抽出」コマンドで処理すると、
(1)「住所」の列から「都道府県」のデータを抽出する(新しい列が作成される)
(2)作成された列の列名を「都道府県」などに変更する
(3)神奈川、和歌山、鹿児島のデータに「県」の文字を追加する
(4)列の並び順を変更する
(5)「住所」の列を削除する
といった手順を踏まなければならない。一方、「変換」タブにある「抽出」タブを使った場合は、(4)と(5)の手順を省略することが可能となり、より少ない工数で処理を完了できるようになる。
このように、「変換」タブを使用した方が少ない工数で処理を完了できるケースも少なくない。目的や状況に応じて「変換」タブと「列の追加」タブを使い分けられるように、両者の違いをよく理解しておく必要があるだろう。
「抽出」コマンドで文字数をカウントする
最後に、抽出方法に「長さ」を選択したときの動作を紹介しておこう。この場合は“データの抽出”ではなく、“文字数のカウント”が行われる仕組みになっている。
-
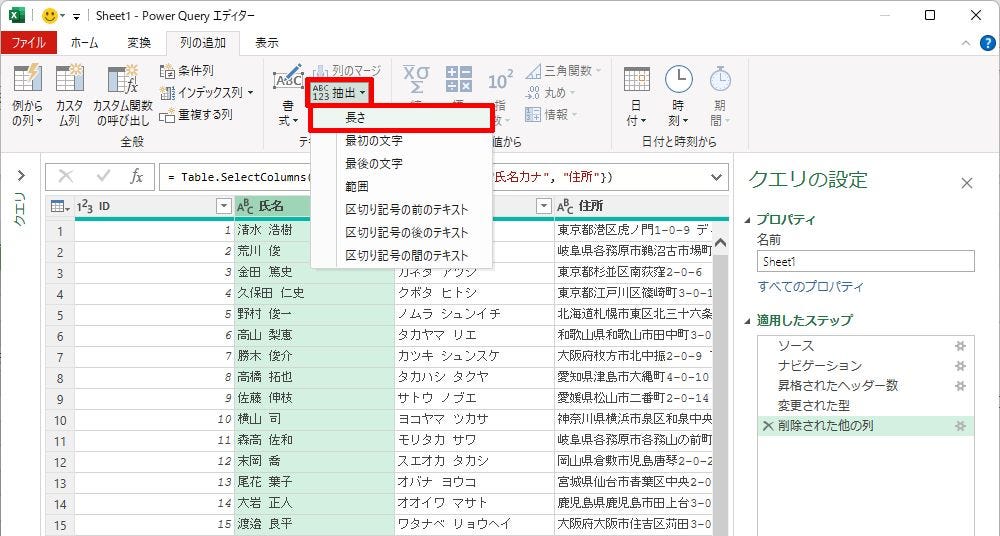
「長さ」で抽出する場合

上図のように操作した場合、「氏名」の列にあるデータの“文字数”をカウントした結果が抽出される。結果を比較しやすいように、「抽出元の列」を「抽出後の列」の並べて配置した例を紹介しておこう。
-
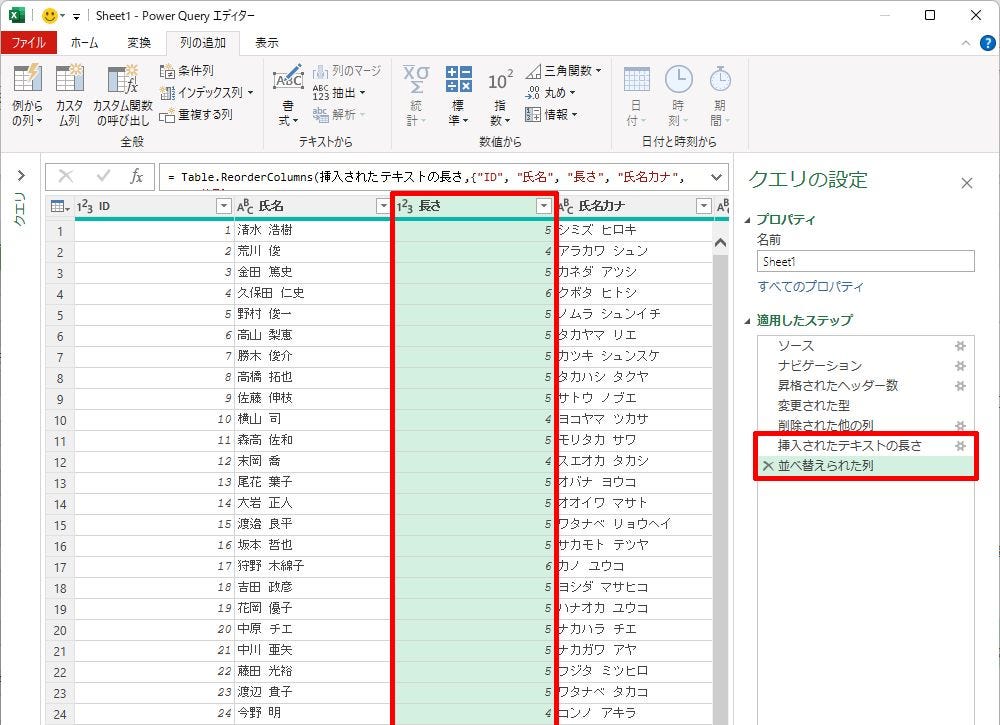
抽出されたデータ(新しく追加された列)

今回の例では、姓と名の間に「半角スペース」が挿入されている。この場合、「半角スペース」も1文字としてカウントされる。よって、「清水 浩樹」は5文字、「荒川 俊」は4文字、……という結果になる。「長さ」の列には、これらの数値が「整数型」のデータとして抽出される。
このように、「長さ」はデータを抽出する機能ではなく、スペースを含む“文字数”をカウントする機能となる。なぜ「抽出」コマンドに含まれているのかは不明であるが、文字数をカウントしたい場合に便利に活用できるので、この機会にあわせて覚えておくとよいだろう。