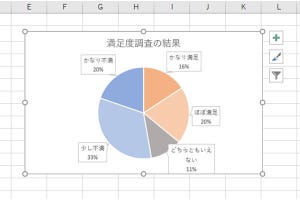
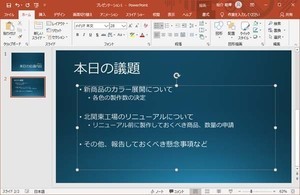
第13回と第14回の連載で「値の置換」や「列の分割」、「列のマージ」といったコマンドの使い方を紹介した。これらのコマンドを使って、「住所」のデータから「都道府県」を分離する処理を実現することも可能だ。各コマンドの使い方を学んでいくだけでは面白みに欠けるので、今回は少し実践的なパワークエリの活用例を紹介してみよう。
住所から都道府県を取得する
今回は、「住所」のデータから「都道府県」を分離する処理をパワークエリで実現してみよう。これまでの連載で解説した「値の置換」や「列の分割」、「列のマージ」といった3種類のコマンドを組み合わせるだけでも「少し複雑な処理を実現できる」ということを実感できるだろう。
-

住所から都道府県を分離する

なお、同様の処理をExcel関数で行うことも可能だ。その具体的な手順は、「定時で上がろう! Excel関数の底力」の第38回と第39回で紹介している。
Excel関数を使った文字列操作に慣れている方なら「わざわざパワークエリに頼るまでもない」と思うかもしれない。しかし、関数が苦手であったり、処理方法のアルゴリズムを思いつかなかったりするケースもあるだろう。このような場合にパワークエリを活用すると、各ステップの結果を見て試行錯誤しながら、少しずつデータを“目的の形”に近づけていくことが可能となる。
ということで、さっそく具体的な手順を紹介していこう。以下の図は、名簿のデータ表を「Power Query エディター」に取得した例だ。このデータ表の「住所」の列から「都道府県」だけを抜き出してみよう。
-

「Power Query エディター」に取得した住所のデータ

都道府県は全部で47個あるが、その大半は「★★県」という形になる。そこで、まずは「県」の文字を区切り記号に指定して「住所」の列を分割してみよう。「住所」の列を選択し、「列の分割」→「区切り記号による分割」を選択する。続いて、以下の図のように分割方法を指定する。
-

「県」の文字で列を分割する処理を指定

この結果は以下の図のようになった。「岐阜県各務原市…‥」や「和歌山県和歌山市……」のように「県」の文字が含まれている住所は、いちおう「都道府県」を分離できているようだ。しかし、「東京都……」や「北海道……」などの住所には対応できていない。「県」の文字で分割しているのだから、これは当然の結果といえる。
-

列を分割した結果

このまま処理を進めても上手くいきそうにないので、別の方法を試してみよう。先ほど指定した「列を分割するステップ」を削除して最初の状態に戻す。このとき、「データ型を判別するステップ」も自動追加されていることに注意しなければならない。先ほどの処理を取り消すには、「変更された型1」と「区切り記号による列の分割」の2つのステップを削除する必要がある。
-

ステップの削除

「住所」の列が分割前の状態に戻る。今度は「大半の都道府県名は3文字になる」という理論に基づいて、住所の列を「先頭から3文字」で分割する方法を試してみよう。「住所」の列を選択し、「列の分割」→「文字数による分割」を選択する。続いて、以下の図のように分割方法を指定する。
-

「左から3文字」で列を分割する処理を指定

今回は、以下の図のような結果が得られた。先ほどよりも期待の持てる結果といえるが、神奈川県/和歌山県/鹿児島県の3つは県名が「4文字」になるため、最後の「県」の文字が不足した状態になっている。この問題に対処しなければならない。
-

列を分割した結果

この問題は、データの置換により対処することが可能だ。分割後の「住所.1」の列を選択し、「値の置換」をクリックする。続いて、「神奈川」→「神奈川県」の置換を行うように指定する。
-

「神奈川」→「神奈川県」に置換する処理を指定

「住所.1」の列にある「神奈川」のデータが、すべて「神奈川県」に置換される。これで「神奈川県」が4文字になる問題に対処できたことになる。
-

データを置換した結果

同様の手順で、「和歌山」を「和歌山県」に置換する処理、「鹿児島」を「鹿児島県」に置換する処理を追加すると、すべての都道府県名を正しく表記できる。
-

「和歌山」→「和歌山県」、「鹿児島」→「鹿児島県」に置換

以上で「住所」から「都道府県」を抜き出す処理は完了だ。「住所.1」の列名を「都道府県」に変更しておこう。データ加工の目的が「都道府県で分類すること」であれば、それ以降の住所は特に必要ないはずだ。よって、この時点で「住所.2」の列を削除してしまっても構わない。
-

「列名の変更」と「列の削除」

このように、とりあえず適当な処理を行ってみて、上手くいきそうなら問題点に対処していく、という進め方でデータを加工していくことも可能だ。各ステップの結果を見て、その場で対処方法を考えながら次の処理を進めていく。こういった使い方ができるのもパワークエリの大きな利点といえるだろう。
住所を「都道府県」と「それ以降」に分離する
「都道府県で分類すること」が最終目的ではなく、「都道府県」と「それ以降の住所」に分割したい……、といった場合は、さらに処理を追加しなければならない。列名が「住所.2」のままでは紛らわしいので、列名を「住所」に変更した状態で解説を進めていこう。
先ほど示した手順で「都道府県」を抜き出した場合、県名が4文字になる住所の先頭に「県」の文字が残っているはずだ。今度は、この問題に対処していく必要がある。
-

先頭に「県」の文字が残っている住所

この対処方法を普通に考えると、データが「県」で始まる場合は、先頭の「県」を削除する、という処理を行うことになる。ただし、そのためにはif文などを使って条件分岐を行わなければならない。本連載では、まだ条件分岐の使い方を解説していないので、もっとベタで、強引な進め方で問題に対処してみよう。
まずは、「住所」の列を「1文字目」と「それ以降」に分割する。「住所」の列を選択し、「列の分割」→「文字数による分割」を選択する。続いて、以下の図のように分割方法を指定する。
-

「左から1文字」で列を分割する処理を指定

これで「住所の1文字目」だけを“独立した列”として扱えるようになる。
-

列を分割した結果

続いて、住所の1文字目が「県」であった場合は「県」の文字を削除する、という処理を行っていこう。この処理はデータの置換で実現できる。「住所.1」の列を選択し、「値の置換」をクリックする。続いて、「県」→(文字なし)の置換を行うように指定する。
-

「県」→(文字なし)に置換する処理を指定

「県」→(文字なし)の置換が行われ、「住所.1」の列から「県」のデータが削除される。
-

データを置換した結果

あとは、「住所.1」と「住所.2」の列を結合して元の状態に戻すだけ。「住所.1」と「住所.2」の列を同時に選択し、「変換」タブにある「列のマージ」をクリックする。結合方法は、区切り記号に「なし」、新しい列名に「住所」を指定すればよい。
-

「列のマージ」で列を結合する処理を指定

-

「列のマージ」により結合された列

以上で、すべての処理が完了となる。あとは「閉じて読み込む」をクリックして、加工したデータ表をExcelに出力するだけだ。
このように、(1)適切な位置で列を分割する、(2)置換機能を使って不要な文字を削除する、(3)列を結合して元の状態に戻す、という手順で条件分岐と同等の処理を実現できるケースもある。ベタな手法ではあるが、「各ステップの状況を目で追えるため、逆に理解しやすい」という方もいるだろう。
多少強引であっても、目的の形にデータ表を加工できるのであれば、特に問題はないはずだ。各自のスキルに応じた使い方ができるのもパワークエリの特長といえる。
「都道府県」の列を活用する
念のため、先ほど加工したデータ表をExcelに出力した結果を示しておこう。今回の例には、ID/氏名/都道府県/住所のデータしか記録されていないが、「実際には他のデータも記録されている」と考えてもらえれば幸いだ。
-

Excelに出力したデータ表

今回の連載で紹介した手法で住所を「都道府県」と「それ以降」に分割しておくと、都道府県別のデータ抽出やデータ分析などを容易に行えるようになる。たとえば、住所が「沖縄県」のデータだけを表示したい場合は、フィルター機能を使って以下の図のように操作すればよい。
-

フィルターで「沖縄県」のデータだけを抽出

-

抽出されたデータ

そのほか、都道府県別にデータを集計するなど、さまざまな用途に対応することが可能だ。そのためには、あらかじめ住所を「都道府県」と「それ以降」に分割しておく必要がある。もちろん、「住所」以外の文字列データにも応用できるだろう。
こういった文字列データの分割を「関数」で処理するのか、それとも「パワークエリ」で処理するのか、どちらを採用するかは各自の自由だ。もちろん、両方とも使えた方が有利であることは間違いない。状況に応じて使い分けられるように、パワークエリの使い方も学んでおくと、きっと役に立つだろう。