ThousandEyesは3月7日(米国時間)、「Unpacking the Slack Outage & Other Backend Issues」において、過去2週間(2月24日から3月2日)にインターネット全体で発生した障害と傾向の分析レポートを公開した。
レポート全文は「Unpacking the Slack Outage & Other Backend Issues in The Internet Report」から視聴することができる。
-

Unpacking the Slack Outage & Other Backend Issues

主な通信障害とその傾向
ThousandEyesはこの2週間に発生したオンラインサービスの主な障害を解説している。その概要は次のとおり。


Slackの停止
2月26日午後3時頃(協定世界時)、Slackの一部または全機能が停止した。ネットワークは安定していたがタイムアウトによる障害を検出したことから、バックエンドシステムの不具合が示唆された。
不具合が発生した当初、影響は分散していた。しかしながら徐々に拡大し、最終的に世界中のユーザーに影響を及ぼした。サービス停止は9時間以上続き、メッセージの送受信、ワークフローの利用、チャンネルおよびスレッドの読み込み、ログインなど多くの機能に障害が発生した。
-

ネットワークは安定しているが、Web応答の停止を観察したグラフ 引用:ThousandEyes

Slackは不具合を修正したあと、2月28日に「Status Site」においてインシデントの概要と修正完了までのタイムラインを公開した。データベースシステムのメンテナンス作業が原因としている。キャッシュシステムに遅延の欠陥が存在したこともあり、データベースが大量のトラフィックをさばききれず、過負荷になったことでサービスが停止した。
Slackは過負荷の原因を修正、翌日午前0時13分(協定世界時)までに問題を解決した。問題解決後もイベントAPIの不具合(カスタムアプリ、ボットなどの機能不全)が発生したが、この問題もすでに解決されている。
Microsoft 365 の停止
3月1日、Outlookを含むMicrosoft 365サービスに障害が発生した(参考:「Microsoft 365に障害発生、原因は認証システムの更新 | TECH+(テックプラス)」)。
フロントエンドサーバのネットワークは正常だったが、サービス間の認証プロセスに障害の発生が観察された。Microsoft 365認証システムのアップデートに原因があり、そのコードに不具合があったとされる。
Grafana Cloudのパフォーマンス低下
オブザーバビリティプラットフォームの「Grafana Cloud」は、2月24日から数日間、パフォーマンスの低下を経験した。Amazon Web Services(AWS)上でホストされる環境のみが影響を受け、新しいインスタンスを開始すると読み込みに長い時間を要したとされる(参考:「Grafana Cloud Status - Longer than expected load times in multiple AWS regions」)。
Otter.aiに障害
2月24日および26日の両日、AI会議アシスタント「Otter.ai」のWebサイトとサービスに障害が発生した。障害の影響を受けたユーザーは、HTTP 502 Bad GatewayまたはHTTP 500 Internal Server Errorに遭遇した。インシデントレポートは次のとおり。
障害の原因は公開されていないが、両障害ともに40分から1時間ほどで解決されている。ThousandEyesは障害の内容、その時間経過などから、メンテナンス作業に原因があったのではないかと推測している。
ネットワーク障害の傾向
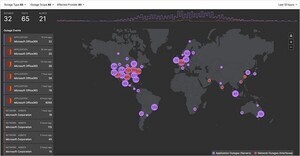
ThousandEyesは同期間におけるインターネットサービスプロバイダー(ISP: Internet Service Provider)、クラウドサービスプロバイダーネットワーク、コラボレーションアプリネットワーク、エッジネットワークにて観測された障害の傾向について報告している。その概要は次のとおり。
- 世界的なネットワーク障害は2月初旬から継続して増加傾向にある
- 米国のネットワーク障害も一旦増加したが、その後減少に転じ、世界とは対照的な結果となった
- 米国のネットワーク障害が世界の約40%以上を占める状況が続いている
- 月ごとの統計では、2月は1月と比較して障害が増加した。世界の総数で約15%増、米国のみで約23%増となった。過去数年間、1月および2月は継続して同じパターンを観測している
-

過去8週間にわたる世界および米国のネットワーク障害の傾向 引用:ThousandEyes