Intel日本法人のインテルは9月25日、エンタープライズ向け製品の記者発表会を開催。AIの開発・導入加速に貢献する新製品として、「P-core」を採用した「Xeon 6 プロセッサ 6900Pシリーズ」、およびAIアクセラレータ「Gaudi 3」を正式に発表した。
-

インテルが発表したAIアクセラレータ「Gaudi 3」

「AIはまだ初期の段階」とするインテルが最新製品を正式発表
昨今では、各企業によるAI開発競争が激化している。生成AIの普及、および企業でのAI導入拡大が成長ドライバとなっているAI市場は、2028年には6300億ドルという国家予算レベルの市場規模にまで急成長を遂げるとも推測される。こうした市場拡大の中では、コストの問題やAIシステムの拡張性、電力効率、セキュリティの問題などさまざまな課題が存在するといい、開発投資に伴うAI支出が増加する中で、よりコスト効率の高い開発環境の整備が求められるとする。
「現在のAIはまだ初期の段階」と捉えているというインテルは、トータルコストで見た場合の優位性や優れた電力効率など、AIの進化に要するコスト効率を高めるための製品開発を続けてきたとのこと。特に電力効率については、ハードウェア面での改善に限らず、オープンモデルを最適化することで演算能力を高め、電力あたりの性能を高めてきたという。またAIを使う企業にとってのユースケースを広げるため、オープンなエコシステムの構築にも重要な戦略的分野として取り組んできたとした。
-

インテルが掲げる重要な戦略的分野

そして今般同社は、高いパフォーマンスが求められる演算に最適化されたXeon 6 プロセッサ 6900Pシリーズを正式発表。電力効率の最適化によりEコマースなどの用途に適したE-coreを採用した製品として発表済みのXeon 6 プロセッサ 6700Eシリーズに続き、負荷の高い演算におけるコアあたりのパフォーマンスを最適化したP-coreを採用したプロセッサとしてリリースされた。また同時に、大規模生成AI向けに最適化されたGaudi 3 AIアクセラレータも登場。より高度な演算処理を実現する同製品を用いることで、AIのトレーニングや推論を効率的かつ集中的に処理することを実現するとし、企業におけるAI開発ワークロードのパフォーマンスを最大限引き出すとしている。
128コアを搭載した性能特化型のXeon 6 6900Pシリーズ
Xeon 6 6900Pシリーズの機能強化点や強みなどについては、インテル 技術本部 技術部長の渡邉恭助氏より説明された。
-

インテル 技術本部 技術部長の渡邉恭助氏

渡邉氏は、最大500W(CPUあたり)にまで対応した6900Pシリーズの特徴として最大128のパフォーマンスコア数を挙げ、前世代では64コアだったのに対し倍増している点を強調した。またUPI(Ultra Path Interconnect)の面ではリンク数を6つに増やし、各リンクの転送レートもアップデート。メモリチャネル数も拡張された。加えて新製品では、サーバCPUとして初めてMRDIMMを採用し、使用時の転送レートは最大8800MT/sまで向上したとしている。
これらの機能強化により、AIの推論性能やHPC演算性能が大幅に向上したといい、他社製品とコア数をそろえて比較した場合にも性能有意性を誇るとする。また電力効率の改善にも大きく力を注いだとのことで、P-coreおよびE-coreをそれぞれ採用した製品どちらも新しいパワーモードを導入。その結果として、40%のサーバ利用率における電力効率を約1.9倍向上させたとしている。なお渡邉氏は、「さまざまなしきい値はそれぞれ調整できるようになっており、顧客側での変更により最適化するとさらに高い性能が出る可能性もあるため、ぜひとも評価をしていただきたい」と話した。
そして製品群の今後については、P-core・E-coreをそれぞれ採用した製品をそれぞれリリースしていく予定とのことで、6900Eシリーズおよび6700Pシリーズ以下の製品群を、2025年第1四半期に発表される予定だとしている。
大規模演算の並列化で高効率を実現したGaudi 3
一方のGaudi 3アクセラレータに関する説明は、インテル 技術本部 シニア・アプリケーション・エンジニアの小林弘樹氏より行われた。
-

インテル 技術本部 シニア・アプリケーション・エンジニアの小林弘樹氏

小林氏は、多くの企業がAIを自社サービスとして運用しマネタイズを行うには、AIの学習能力ではなく、特定領域に特化した小サイズモデルによる推論をどれだけ効率よく運用できるかが重要になっていくと語る。そしてインテルとしては、GPT-4やGPT-5に代表される大規模パラメータを持つ最先端モデルに加え、特定の領域やタスクに特化した“ファインチューニング”を行うモデルや、オープンソースのエンタープライズ向けモデルをGaudiの注力分野として掲げているとする。
そしてこれらの分野に向けて同社は、Gaudiの製品ラインナップとしてOAM仕様に準拠したアクセラレータ・カード、ユニバーサル・ベースボードを提供してきた。さらに今回発表されたGaudi 3からは、CEM仕様に対応したPCIeアドインカードもラインナップに追加された。このタイプの製品でも、ピーク性能やメモリサイズはOAM準拠タイプと変わらないものの、TDP(熱設計電力)は600Wに抑えられる(OAM準拠タイプでは900W)ことから、電力面に懸念がある顧客でも効率的なAI導入を可能にする選択肢になるとした。
-
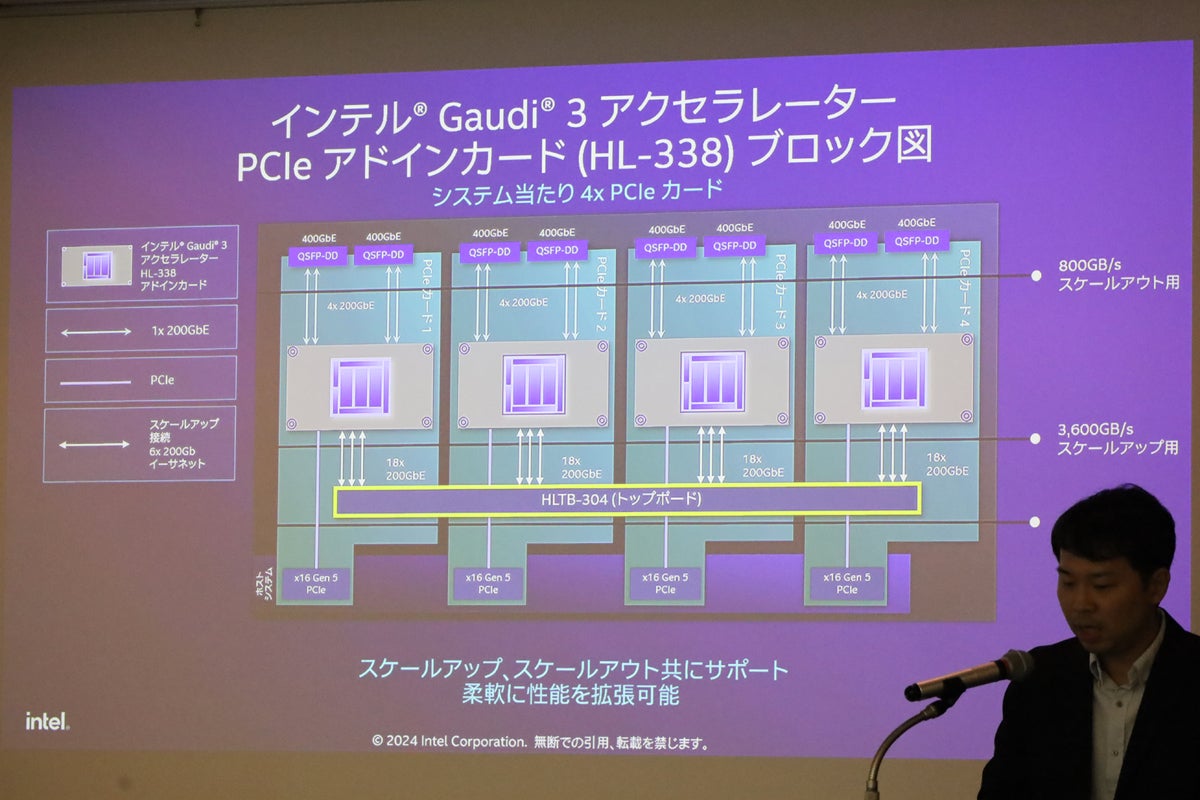
Gaudi 3 PCIeアドインカードのブロック図

なお小林氏は、Gaudi 3が強みとする点として推論スループットの高さとコストパフォーマンスを挙げており、その大きな要因には、行列乗算エンジン(MME)とTensorプロセシングコア(TPC)の存在があるとする。MMEについては、256×256という大規模なシストリック・アレイを内蔵する点が最大の特徴とし、AIワークロードで必要となる巨大サイズの行列演算を1度で行えるため、従来は演算を分割していたために生じていたデータ転送が削減され、計算効率が向上したという。またベクトル演算を実行するTPCは4つ独立して配置されており、並列して演算を行うためさらなる効率化が実現されたとしている。
加えてGaudiによる演算の特徴として、パイプラインを使用した演算の並列化も挙げられた。通常は大規模な演算を行う場合、MMEが行った行列演算の結果がキャッシュに書き込まれるが、容量の関係で書き込み切れなかったデータはHBMに記録されるため、データの伝送が生じてレイテンシが大きくなるという問題が生じる。これを避けるためGaudiでは、「グラフ・コンパイラ」により演算処理を小規模なスライスに分割し、キャッシュの空き容量に収まるサイズでそれぞれ並列して処理を実行。これによりレイテンシが低減されるとともに、演算スループットも向上するといい、これがGaudiの演算性能が高い主要因だと説明された。
-

Gaudi 3が特徴とする演算方法について説明する小林氏

小林氏によれば、LlaMAをはじめとするさまざまなモデルとフレームワークに対応。またクラウド上でGaudiプラットフォームを体験可能な「インテル Tiber デベロッパー・クラウド」についても言及し、2024年第4四半期には顧客を限定してGaudi 3の機能を提供開始するとのことで、一般提供の開始は2025年を予定していると語った。さらに、Gaudi 3を搭載したシステムについては、DELL・HPE・SuperMicroより2024年第4四半期に一般提供が開始されるとした。
-

Gaudi 3を搭載したSuperMicroの「Supermicro X14」

両製品の融合で企業のAIパフォーマンス最大化に貢献
インテル 執行役員 技術本部長の町田奈穂氏は、Xeon 6を「エンタープライズワークロードおよびAIワークロードに適した汎用CPUであり、AIアクセラレータを束ねるホストCPUとしても最適な製品」、Gaudi 3を「エンタープライズ環境においてAIワークロードのパフォーマンスを最大限に引き出すAIアクセラレータ」と表現。そして両者を組み合わせることで、「顧客のインフラストラクチャに対して強力なAIソリューションをシームレスに統合させることを可能にする」と語った。
-

インテル 執行役員 技術本部長の町田奈穂氏

またこれらのエンタープライズ向け製品ラインナップについては、今後もパートナー企業との協業を重視していくとしたうえで、「オープンソースのフレームワークやライブラリ、ツールを最適化することで、顧客がAIを合理的かつ効率的に導入できるよう支援を続けていく」としている。