米Informaticaの日本法人であるインフォマティカ・ジャパンは8月22日、オンラインで生成AIを活用したデータマネジメントの最新トレンドと、国内の事業戦略について記者説明会を開催した。
クラウドネイティブなデータマネジメントに注力するインフォマティカ
Informaticaは、データ統合・管理のソリューションを提供する企業として1993年に設立し、現在の5600人、パートナーは500社以上、本社を米カルフォルニア州レッドウッドシティに構えている。日本法人のインフォマティカ・ジャパンは2004年に設立、従業員90人で国内パートナーは20社以上となっている。
冒頭、インフォマティカ・ジャパン 代表取締役社長の小澤泰斗氏は「データ専業ベンダーとしてデータにフォーカスしている。創業当初はETL(Extract:抽出、Transform:変換、Load:格納)がメインだったが、データの変遷とともに当社も変遷してきた」と述べた。
-

インフォマティカ・ジャパン 代表取締役社長の小澤泰斗氏

同社における大きな転換点として2015年に上場を廃止し、2021年に再上場した。この間、データでビジネスプロセスをつなぐ時代から統合から、データレイクやDWH(データウェアハウス)といったデータ分析へのニーズが拡大し、単にデータをつなぐだけではなく品質に対するニーズの高まりがあったとのことだ。


小澤氏は「DX(デジタルトランスフォーメーション)が走り始め、さまざまなクラウドシステムが登場し、データ連携だけでなく、データ活用するためのデータカタログやマスタデータマネジメント(MDM)などのニーズも増えてきた」と振り返る。
こうした状況もあり、ETLからデータマネジメントのベンダーに生まれ変わり、プラットフォーム自体もオンプレミス型からアジリティを確保するためクラウドネイティブ型に移行している。
-

Informaticaにおける2015年から現在までの変遷

現在、同社ではデータによる価値創造を目指しており、それを具現するためのフレームワークとしてDIKW(Data、Information、Knowledge、Wisdom、Value)モデルをベースに、データの「整備」「知識」「価値」の3つのフェーズを推し進めていく必要を説いている。
具体的には、意味をなさないデータ(Data)を目的で関連付けられたデータを組み合わせることで意味をなすようなデータ(Information)に変え、論理立てられた情報を組み合わせて知識化(Knowledge)、判断できる(Wisdom)ものとし、同社ではデータを価値に変えていくフェーズとして上述の3つの段階を踏んでいるという。
-

DXの成功に向けてデータマネジメントに必要要素と3つのフェーズ

データ活用においてAIは切っても切り離せない
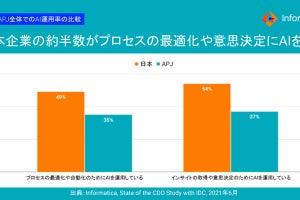
一方、今後のデータ活用の見通しとして小澤氏は「AIは切っても切り離せない。実際に当社の調査によると、45%のCDO(Chief Data Officer)は生成AIが優先事項で導入済みであり、残りの54%は将来的に導入予定と回答している。AIの活用は進んでいるが、ハルシネーションなどの課題も存在している。AI単体が価値を生み出すのではなく、AIとデータが価値を生み出す」と話す。
では、どのようなデータが必要になるのだろうか。同氏は民主化されているほか、ガバナンスが効かされており、品質が担保されているなどの要素がデータには必要だと強調する。こうした要素に加え、IT部門やデータサイエンティスト、DX部門のみならず、ビジネス部門でもデータを使えることが重要との見立てだ。
小澤氏は「このようなことに取り組むことがデータマネジメントであり、当社ではデータ統合プラットフォームとして『Intellegent Data Management Cloud』を提供している」と力を込めた。
次世代のデータマネジメントを実現する「Intellegent Data Management Cloud」
Intellegent Data Management Cloudについては、インフォマティカ・ジャパン グローバル・パートナーテクニカルセールス ソリューションアーキテクト&エバンジェリストの森本卓也氏が解説した。
森本氏は「生成AIによるデータ戦略には次世代のデータマネジメントが必須ではあるものの、データ品質やAI/データガバナンス、組織内の各事業部別で作ってきたドメイン固有のデータによるサイロ化といった課題が挙げられる。事業部横断でデータのつながりを作り、適切なアドバイスができるAIを整備するにはマスタデータのような分析の軸になるようなデータを連携させることが重要になる」と説く。
-

インフォマティカ・ジャパン グローバル・パートナーテクニカルセールス ソリューションアーキテクト&エバンジェリストの森本卓也氏

同氏によると、生成AI時代における高度かつ複数のデータマネジメントを行うには5つ以上のデータ管理が必要になるという。例えば、データカタログやデータ統合、API連携、データ品質、マスタデータ管理、ガバナンス、マーケットプレイスなどだ。
森本氏は「データマネジメントのさまざまなツールが技術的負債に陥っている企業もあり、そのような中で当社は次世代のデータマネジメントを実現するために、当社では単一のプラットフォームであるIntellegent Data Management Cloudを提供している。データマネジメントをしていくために必要なサービスがすべて含まれており、ツール間のオペレーションを自動化するためユーザーが配慮する必要はない。クラウドネイティブなアーキテクチャのためデータ量・種類が増えても容易にスケールできるほか、さまざまなクラウドサービス、オンプレミスシステムに対するコネクタを用意している」と胸を張る。
-

「Intellegent Data Management Cloud」の概要

独自のAIエンジンをプラットフォームに組み込む
そして、Intellegent Data Management Cloudは独自のAIエンジン「CLAIRE」を搭載しており、作業の自動化やレコメンデーションなどを可能としている。森本氏はCLAIREを活用して「AIのためのデータマネジメント」と「データマネジメントのためのAI」の2つのコンセプトをもとにした機能として「CLAIRE copilot」と「CLAIRE GPT」を紹介した。
-

「CLAIRE copilot」と「CLAIRE GPT」

CLAIRE copilotは、AIを活用したデータマネジメント作業の自動化機能となり、データ統合のマッピングのデザインで使用するソース関する推奨事項やデータのフォーマット/標準化に適用される変換とDQ(Data Quality)ルールに関する推奨事項などを提供する。
-

「CLAIRE copilot」におけるデータ統合のレコメンデーションの概要

また、データ品質の洞察としてプロファイリング結果を分析することで潜在的なデータ問題の発見の自動化や、スケーラブルなフレームワークでDQルールを高度なAI/MLアルゴリズムに拡張することなどをサポート。
CLAIRE GPTは生成AIの自然言語のインタフェースをIntellegent Data Management Cloudに横断する形で設けることで、誰もが質問すればデータマネジメントの作業をサポートするものだ。
-

「CLAIRE GPT」の利用イメージ

森本氏は最後に「クラウドネイティブなデータアーキテクチャのデータプロダクトを提供するとともに、包括的なデータマネジメントを行える単一のプラットフォームとしてツールのサイロ化に悩まされることなく、生成AI時代のデータ、ユーザーのスケールに耐えうるものを提供していく。また、マルチクラウド・ベンダーとあらゆるテクノロジーをつなぐ形でデータマネジメントの世界を実現していく」と述べていた。