


データ分析環境として、Databricks(データブリックス)を導入した東芝データ。今回、導入までの経緯や効果について、東芝データ 技術部フェロー 兼 技術第二グループ長 博士(工学)の城田祐介氏と、同 技術部 博士(情報学)の金井達徳氏の話を紹介する。
-

左から金井達徳氏、城田祐介氏

レシートデータの分析基盤構築が急務となっていた東芝データ
東芝データは、2020年2月に設立された。東芝グループのセキュリティ技術とノウハウを基盤に、人々の購買動向をはじめ、健康、人材、行動など実社会で収集したデータを高度なデジタル技術で分析し、活用しやすい情報に加工して実社会に還元することで、豊かな未来を創造するデータ循環型のエコシステムの構築を目的としている。
同社を立ち上げるきっかけとなったのは、東芝のグループ会社である東芝テックが提供する電子レシートサービス「スマートレシート」のデータ活用が急務となっていた。
スマートレシートは、店舗におけるPOSシステムのレシートデータを会員の同意にもとづき、東芝データが統計処理して、企業向けに購買行動の把握や広告効果の検証をはじめとしたデータサービスに活用するとともに、集客などの効果測定の可視化につなげるというもの。
一方、会員はスマートフォンからいつでも購入履歴の確認・管理ができ、買い物における利便性の向上につながる現在の会員数は、190万人と200万人に手が届きそうな位置にあり、東芝データではデータの統計処理に加えて、データを収集・分析する必要があったのだ。


Databricks導入に向けた3つの要件
そのため、東芝データ設立後の2020年9月にDatabricksの日本法人としてデータブリックス・ジャパンが設立されたのを契機として、同12月には東芝データからコンタクトを取り、2021年4月から1カ月半ほどPoC(概念実証)を行い、同7月に本格導入を開始した。
当時、東芝データの代表取締役CEOだった島田太郎氏(現・東芝 代表取締役 社長執行役員CEO)に対して、データブリックス・ジャパン側から2021年に開催したオンラインカンファレンス「Data + AI World Tour Japan」への登壇依頼がきっかけとなり、島田氏がDatabricksに強く興味を持ったという。
Databricksは、分散処理フレームワークの「Apache Spark」「Delta Lake」「MLflow」などのオープンソース技術を活用して、データ統合とデータ分析、AIの活用を可能とし、レイクハウスアーキテクチャを具現化するSaaS(Software as a Service)型統合データ分析基盤を提供。
また、BI(ビジネスインテリジェンス)やリアルタイムデータ処理、データサイエンス&機械学習、DWH(データウェアハウス)、データ編集・加工を単一のプラットフォーム上で、構造化データのみならず、非構造化データとAIを含めた一元的なガバナンスモデルを提供している。
城田氏は「導入に際して、技術的には非常にスムーズに進みました」と話す。また、金井氏は「島田さんは技術に明るく、エンジニアでもあったことから、その目線に加えて米国の勢いのある新興企業が成長し始めているという雰囲気を感じていたのだと思います。私も本人から『なんか面白そうな会社だね』ということは聞いていました」と振り返る。
東芝データにおいて、Databricksの導入に向けて、大きく3つの要件があった。1つ目はビッグデータを高速かつスケーラブルに処理できること、2つ目が自社のシステム環境からデータを動かせないためデータプライバシーとセキュリティを担保できること、3つ目が運用にコストを掛けられないことから少ないリソースで分析環境の構築・運用ができることだった。
なぜ、東芝データはDatabricksの導入を決めたのか?
導入に向けた東芝データの要件に対して、Databricksはどのようなメリットがあったのだろうか。その点について、城田氏は以下のように説明した。
「PoCを通じて、データ処理に関してはDatabricks自体がApache Sparkをベースにしていることから、大量なデータを高速分散処理できるという強みがあります。また、データプライバシーとセキュリティについては、コントールプレーンとデータプレーンが分離しているため、自社システムデータプレーンを置いた状態で管理が可能でした。そして、少ないリソースで運用できるためコストを低減するとともに、運用コストが大幅に削減できると感じました。このような要件を総合的に検討した結果、導入を決めました」(城田氏)
-

城田氏

また、金井氏は「当社の場合は少し特殊な例だったと思います。というのも、他社ではパブリッククラウド上でデータ分析基盤を構築する場合もあるからです。ただ、その場合は個別にサービスを組み上げるため時間とリソースを割かなければならないほか、運用に負荷がかかってしまいます。しかし、Databricksであれば、そもそもパブリッククラウドを使って構築する必要がなく、導入してしまえばやりたいことの大半はできてしまうからです」と、そのメリットを説く。
-

金井氏

導入自体がスムーズに行えたのはDatabricksがSaaS型のマネージドサービスのため、インフラを一から構築せずとも比較的容易に設定が可能だった。また、東芝データの指針としてベンダーロックインを回避することも求められていたことから、DatabricksのコンポーネントがOSS(オープンソース)であることもポイントとなった。
-
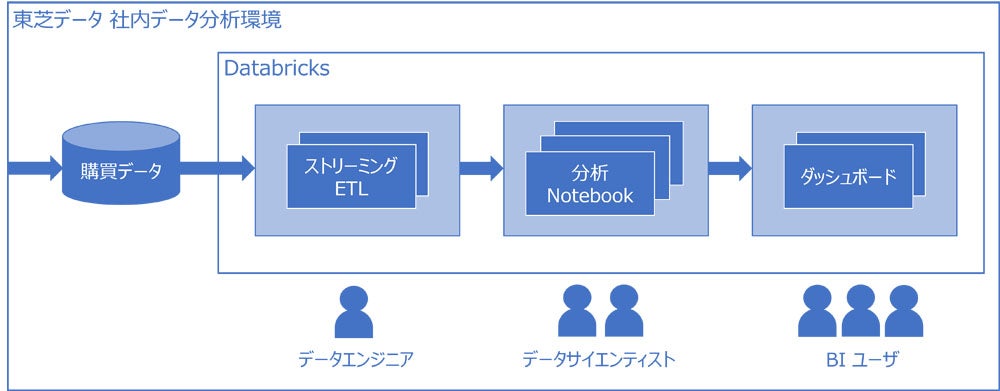
東芝データにおけるデータアーキテクチャのイメージ

こうしてDatabricksで構築したデータ分析基盤により、東芝データでは基盤データのETL(Extract:抽出、Transform:変換・加工、Load:格納)やデータ分析はもちろんのこと、東芝データの全社員がKPIのデータを共有する経営ダッシュボードとしての用途に広がっている。そして、BtoB領域における成果が着実に出始めてきているようだ。
BtoB領域におけるビジネスの成果を生み出す分析基盤
今年4月には、ミツカングループのZENBと共同で購買ビッグデータにもとづく、グルテンフリー食品の市場分析を実施。
東芝の研究開発センターの製造やデータ分析で培った独自のクラスタリングAI技術を用いて、実際の購買ビッグデータから購買パターンが共通する商品を同じ商品グループ(クラスタ)に自動で分類し、隠れた購買トレンドの発見や気づきを得ることを可能としている。
-
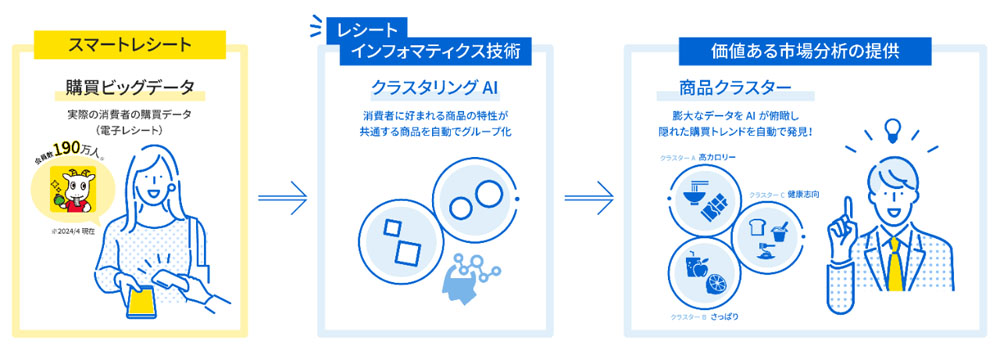
東芝の研究開発センターとクラスタリングAIを用いて商品グループを自動分類し、隠れた購買トレンドの発見などに活かしている

具体的には、handsのオルタナティブデータサービス「PERAGARU」上で各上場企業が公表している売上データと、スマートレシートから得られる購買統計データとの相関関係を分析し、相関関係が高い上場企業の推定売上データを求め、30銘柄1パッケージとしてPERAGARU上で提供。今後は食品製造銘柄だけではなく、トイレタリー関連銘柄や化粧品関連銘柄も追加し、販売銘柄を拡充していくことで2024年度中に100銘柄程度に販売銘柄の拡充を予定している。
さらには、東芝の研究開発センターのAI研究者とともにコラボラティブデータサイエンスのプラットフォームとしてDatabricksを活用しており、社内外でDatabricksの活用が進んでいる状況だ。
東芝データにおけるデータ活用の将来的な展望
城田氏は「研究開発センターとはクラスタリングに加え、自然言語処理やLLM(大規模言語処理)など、AIでデータの価値を最大化する取り組みとしてレシートデータの分析に特化したAI技術『レシート・インフォマティクス技術』の開発を進めており、ZENBさんとの取り組みにも活用しています。今後は、独自の自動分類にもとづいた高度な統計データの提供も目指しています」と展望を語る。
同氏が話すように、同社はDatabricksが新たに掲げる「データインテリジェンスプラットホーム」として、データとAIのプラットフォームとして活用していく方針。レシートデータの価値を高めた形で企業に購買統計データを提供し、例えばメーカーなどにデータを提供する際は、使いやすい形でデータを提供していくことなどに注力する。
金井氏は「データを活用する時代に向けて、当社が設立されたのも東芝グループ内でフラグシップになることを期待されている面がありますね。その中でも、スマートレシートのデータは1つの大きな可能性があるため注力しています。グループがカバーしている産業の範囲は非常に広いので、活用できるデータあるはずです。そうしたところに、われわれの活動が何らかの波及効果があることを期待されており、実際にグループ内で話を進めていたりもしています」と述べており、同社のさらなるデータ活用に注目したいところだ。













