



データレイクとデータウェアハウスの利点を組み合わせたデータ管理アーキテクチャであるレイクハウス。これを提唱したのが、Databricksだ。DatabricksはSpark、Delta Lake、MLflowなどのオープンソース技術を活用し、レイクハウスアーキテクチャを具現化する統合プラットフォームを提供する。最近はこのレイクハウスを使いAIの機能を取り込んで、「データ・インテリジェントプラットフォーム」を目指している。
レイクハウスでデータサイロを解消し、インテリジェントプラットフォームでデータ民主化を
従来のデータ活用では、データウェアハウスへのデータ蓄積とBI(ビジネスインテリジェンス)ツールによる可視化、レポーティングが主流だった。昨今はAIの技術要素が入ったことで、自動化や予測、さらに何かを生成するためにデータが使われる。AIのためにデータを扱うには、さまざまな要素技術が必要だ。
従来のデータウェアハウスやETLなどの仕組みはもちろん、非構造化データも使うのでデータレイクが必要となり、IoTのデータを使いたければストリーミングデータを扱う仕組みも欲しい。
「これらさまざまな技術要素を組み合わせることとなり、それに苦労することになります」と指摘するのは、データブリックス・ジャパン 代表取締役社長の笹俊文氏だ。
-

データブリックス・ジャパン 代表取締役社長の笹俊文氏

多くの企業では、技術要素がバラバラなのでデータがサイロ化してしまう。その状況では、BIによるデータ活用はできたとしてもなかなかAIまで辿り着けない。仮にAIの取り組みができても、需要予測などデータガバナンスが厳しく求められないものは良いが、顧客の満足度を向上するような取り組みは難しい。
顧客にAIで何らか価値を提供するとなれば、責任あるAIが求められるからだ。AIの学習などに利用したデータはどのようなもので、その利用権限や来歴などを明らかにするデータのガバナンスが求められるのだ。データがサイロ化している状況では、データガバナンスを確保するのは難しいと笹氏は指摘する。


Databricksのレイクハウスは、非構造化、半構造化データを1つに集めるデータレイクとしても、構造化データを蓄積するデータウェアハウスとしても機能する。あらゆるデータを一元的に集められるので、データのサイロ化は解消できる。
この際、Databricksは物理データをクラウドオブジェクトストレージに、メタデータをメタストアにそれぞれ格納して管理する独自のDelta Lakeの仕組みを採用している。これによりデータのサイロ化を解消し、データのガバナンスも確保しやすくなる。
その上でDatabricksには、生成AIを用いたデータインテリジェンスエンジンが組み込まれた。従来レイクハウスにはBIツールでアクセスしてデータを活用するか、SQLを用いてデータを抽出し、別のツールやアプリケーションで活用していた。
データインテリジェンスエンジンは、レイクハウスにあるデータのセマンティクス(意味)を理解するエンジンで、自然言語で問い合わせればSQLに変換され必要なデータが取り出せる。
これにより「データの民主化を実現し、誰でもデータを扱えるようになった」と笹氏は言う。たとえば、今年度の第一四半期の製品別売上を、昨年度と比較したグラフで出力して欲しいとDatabricksのプラットフォームで打ち込めば、裏側で適切なSQLを生成し必要なデータを取り出し、グラフまで出力できる。
BIツールなどを使わずとも、インテリジェンスエンジンを用い自然言語の問い合わせで、コードなどを書くことなく蓄積したデータに対するダッシュボード画面が簡単に作れる。このダッシュボードは「レイクビュー」と呼ばれる。
-

Databricksのインテリジェントプラットフォーム

レイクハウスと「Mosaic AI」で企業のAI導入を支援
さらに、プラットフォーム上にAI機能を構築、展開するMosaic AIもある。Mosaic AIは、2023年7月に買収したMosaicMLのLLM(大規模言語モデル)技術などを取り込み、予測モデルの構築、最新の生成AI、LLMなどのAIとMLソリューションを構築、デプロイ、監視するための統合ツールだ。
これまではMLOpsが実現できたが、LLMOpsも新たに可能となった。これによりDatabricksの上で、格納されているデータを用いてLLMのファインチューニングなどが可能となる。「企業独自の情報を用いて、さらに生成AIのLLMを育てていくことが可能です」と笹氏は述べている。
レイクハウスのデータからプロンプトに関連するデータをLLMに渡し生成AIの結果精度を高める、RAG(Retrieval Augmented Generation)の仕組みも実現できる。そのためにDatabricksは、新たにベクターデータも扱えるよう拡張されている。
また、Metaの「LlaMa 3」など、既存のLLMが利用できるだけでなく、2024年3月にはオープンソースの独自LLM「DBRX」も発表している。DBRXはMosaic AIから利用でき、すでに日本のいくつかの企業で性能の評価が始まっている。他のLLMよりも「費用対効果の高いLLMを作りました」と笹氏は、Databricksが独自LLMを構築する意味を説明する。
DBRXを構築するのにも、Mosaic AIの仕組みであるMosaic AI Trainingを使い、モデル学習の効率化を図っている。学習では大量のGPUリソースを使うが、確保したGPUを効率的に利用できるようにする分散トレーニング、オーケストレーション機能がMosaic AI Trainingにはある。
さらに、一般的なGPUエラーを検出でき、学習が中断した際にも速やかに自動再開できるようにするなど、学習のフォルトレランス機能もGPUリソースの効率的な利用に寄与する。
現状、Mosaic AI Trainingのサービスの裏側でAWS、Azure、Google Cloud、Oracle Cloud Infrastructureが提供するGPUのサービスからリソースを確保しており、それらを同時に使い分けて活用している。この時にユーザー側でどのクラウドサービスのGPUリソースを使っているかなどを意識する必要はない。ユーザーはDatabricksだけを見てLLMの学習が行える。Mosaic AI Trainingは2024年6月から提供する。
-
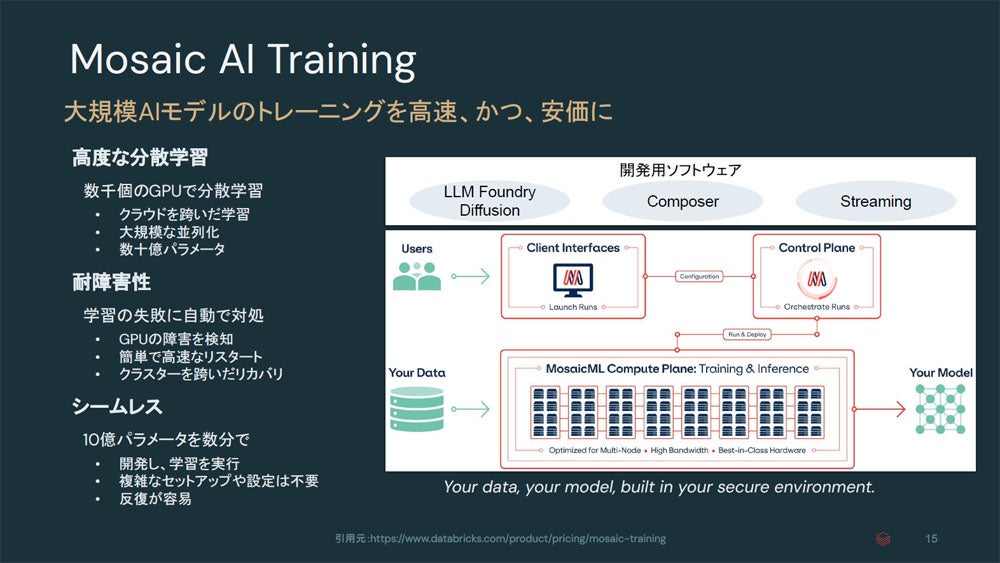
Mosaic AI Trainingの概要

グローバルで1万社を超えるDatabricksのユーザー企業は、日本でも着実に増えている。国内の売り上げなどの数字は公表していないが、昨年度にビジネス目標として掲げた数値は達成しており、顧客数、パートナー数も前年と比べ倍増しているという。
顧客がDatabricksを選ぶ理由は、リクルートのようにデータ活用でリアルタイム性を求めため、あるいはコニカミノルタのようにBIだけでなくAIも実践できるプラットフォームを求めたことが挙げられていた。1つのプラットフォームで従来のBIから、今後のAIまで実現できる点はDatabricksの優位性といえそうだ。
レイクハウスと生成AIは相性が良いだろう。実際に独自のLLMを構築して活用したいと考えるユーザー企業は、コストと手間の観点からそれほど多くはないかもしれない。
一方で必要な社内ドキュメントのデータなどをレイクハウスに格納しておき、RAGを使い既存のLLMで高精度の生成AIの結果を得てビジネスに活用する。あるいは特定の領域、特定の課題の解決に特化した形にDBRXなどをファインチューニングして、得られた結果を使い自社独自のビジネスプロセスの自動化や効率化を進めるなどの用途は十分に考えられる。
特にRAGを用いるアプローチは、これからの生成AIの企業における活用では主流になると予測される。その際にさまざまなAIの技術要素を組み合わせるのではなく、Databricksのプラットフォーム1つに集約できるのは、大きなメリットとなりそうだ。














