



6月12日~14日に米サンフランシスコで年次カンファレンス「Data + AI Summit 2024」を開催したDatabricks(データブリックス)。初日の基調講演では「Unity Catalog」のOSS(オープンソースソフトウェア)化が発表された。そもそも、なぜOSS化に踏み切ったのだろうか。その真意について2日目の基調講演で語られた、Databricks Chief Technology Officer and Co-Founder(最高技術責任者兼共同創業者)のMatei Zaharia(マテイ・ザハリア)氏の話をお伝えする。
-

Databricks Chief Technology Officer and Co-Founder(最高技術責任者兼共同創業者)のMatei Zaharia(マテイ・ザハリア)氏

ザハリア氏は、Databricksのチーフテクノロジスト兼共同設立者であると同時に、米スタンフォード大学コンピュータサイエンス学部助教授を務めている。2009年にカリフォルニア大学バークレー校で博士号を取得した際にApache Sparkプロジェクトを開始し、MLflow、Delta Lake、Apache Mesosなど、広く使われているそのほかのデータ、機械学習ソフトウェアのプロジェクトなどに取り組んできた。
Unity Catalogがオープンソースにとって、何を意味するのか?
まずは、Unity Catalogのおさらいから。そもそもUnity Catalogは、データとAIのためのガバナンスレイヤを提供し、データブリックスのプラットフォーム内で、構造化データ、非構造化データ、ML(機械学習)モデル、ノートブック、ダッシュボードなど、さまざまなデータやデータアセットをシームレスに管理することを可能としている。現在は10TB以上のデータを扱い、ユーザーは1万以上、アクティブユーザーは1500人となっている。
一方、Unity Catalog OSSはDelta Lake、Apache Iceberg、Apache Hudiのクライアントを6月中に提供予定の「Delta Lake UniForm」を介して読み取ることが可能。さらにIceberg REST CatalogとHive Metastore(HMS)のインタフェース標準もサポートし、表形式・非表形式のデータ、MLモデル、生成的AIツールなどのAIアセットを横断的にガバナンスできるため、組織は管理の効率化が図れるというものだ。
Unity Catalogが持つ“ガバナンス”がオープンソースにとって、何を意味するのか?このような問いからザハリア氏は説明を始めた。


同氏によると、データとAIを複合的に利用するには、どのようなアプリケーションでもガバナンス、セキュリティ、クオリティ、コンプライアンスが障壁になっていると指摘。実際に、AIの規制については各国政府間レベルで議論されている。そのため、正当であるか否かといったデータの出自を判断してモデルを構築し、アプリケーションをデプロイしなければならないという。
また、AIを使いたいがガバナンスに問題があって使えない、常に変わりつつあるルールを守るために使えないということがあるため、最初から理想的なガバナンスを具備したソリューションを作る必要があるとの見解だ。
Unity Catalogができた経緯、理想的なガバナンスソリューションのニーズとは?
そこで、同社は理想的なガバナンスソリューションのニーズが「Open Connectivity(オープンな接続性)」「Unified Governance(統一されたガバナンス)」「Open Access(オープンなアクセス)」の3点であると判断。ザハリア氏は以下のように語った。
-

理想的なガバナンスソリューションのニーズに対応した「Unity Catalog」

「どのようなデータやソース、フォーマットでもガバナンスのソリューションにプラグインすれば、すぐに使えるものを生み出したいと考えていました。大半の企業はさまざまなサービスやツールを使っているため、われわれではデータの所在にかかわらず1カ所でガバナンスを効かせられることを実現したいと考えたのです。そして、データとAIに対して統一された一元管理できるガバナンスを作る必要があることに加え、ユーザーはオープンなアクセスを求めていました。そのため、Unity Catalogができました」(ザハリア氏)
しかし、なぜUnity CatalogをOSS化したのだろうか。同氏はクラウドデータプラットフォームのプライヤーでオープンなクラウドと謳う企業があるものの、真の意味でのオープン性をサポートしているのかは疑わしいとの認識を示している。
また、そのほかのクラウドDWH(データウェアハウス)は大半が独自のテーブルを持っており、データがロックインする可能性があるほか、オープンフォーマットのものもあるが、コンピュートされていないため追加の料金を払う可能性もあると指摘。
ザハリア氏は「そのため、データはユーザーのみが所有するオープンなレイクハウスアーキテクチャをわれわれはサポートするとともに、オープンなフォーマットで取り組んでいる。独自のテーブルはありません」と説明する。
鍵となる「Delta Lake Uniform」
その中でも、Delta Lake Uniformが鍵となるようだ。UniFormはUni=Universal(ユニバーサル)、Form=Format(フォーマット)の造語であり、Delta LakeとIcebergの両方がApache Parquetのデータファイル、メタデータレイヤで構成されていることを利用している。現在、Linux Foundationの傘下財団であるLF AI & Dataでホストされている。
このため、データを書き換えずにIcebergのメタデータを非同期的かつ自動的に生成し、IcebergクライアントはDeltaテーブルをIcebergテーブルであるように読み取ることを可能としており、データファイルの1つのコピーが両方の形式に対応するという。
ザハリア氏は「データブリックスは、すべてのデータがオープンフォーマットである唯一のデータプラットフォームです。Uniformによるクロスフォーマットの互換性についてもパイオニアであり、IcebergとHudiのエコシステムにDeltaテーブルをオープンにしています。私たちはUnity CatalogをOSS化することで、さらに前進しようとしています」と力を込めた。
つまり、オープンを謳うのではなく、いかにデータブリックスが実際にオープンソースに対して大きくコミットしているか、だからこそのOSS化なのだろう。
今後もUnity Catalogの機能拡張に注力
ザハリア氏は、Unity Catalog OSSのローンチ時期について「Maybe in 90 days?(90日以内か?)」というアイロニック(競合のSnowflakeは6月第一週に開催した年次カンファレンスで「Polaris Catalog」を90日以内にオープンソース化すると発表)なスライドを示した。
-

ローンチ時期について「Maybe in 90 days?(90日以内か?)」というスライドが示されたが……

そして、突如デモブースでPCの操作を開始。すると、GitHubのページを開き、その場でローンチするというサプライズ演出により、会場が大きな拍手で包まれた。
-
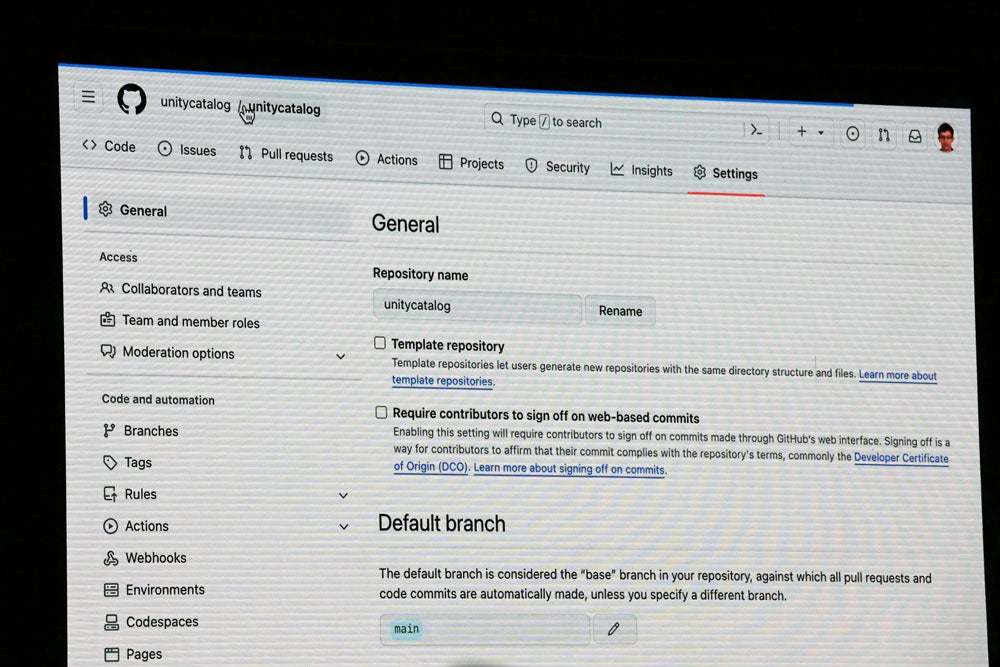
その場でUnity Catalog OSSをローンチしていた

-

Unity Catalog OSSの概要

また、Unity Catalogの新機能として「Metrics」を発表。ビジネスメトリクスの定義・管理し、データブリックスや外部ツールからアクセス可能としており、サードパーティのメトリクスプロバイダーと連携もできるという。
-
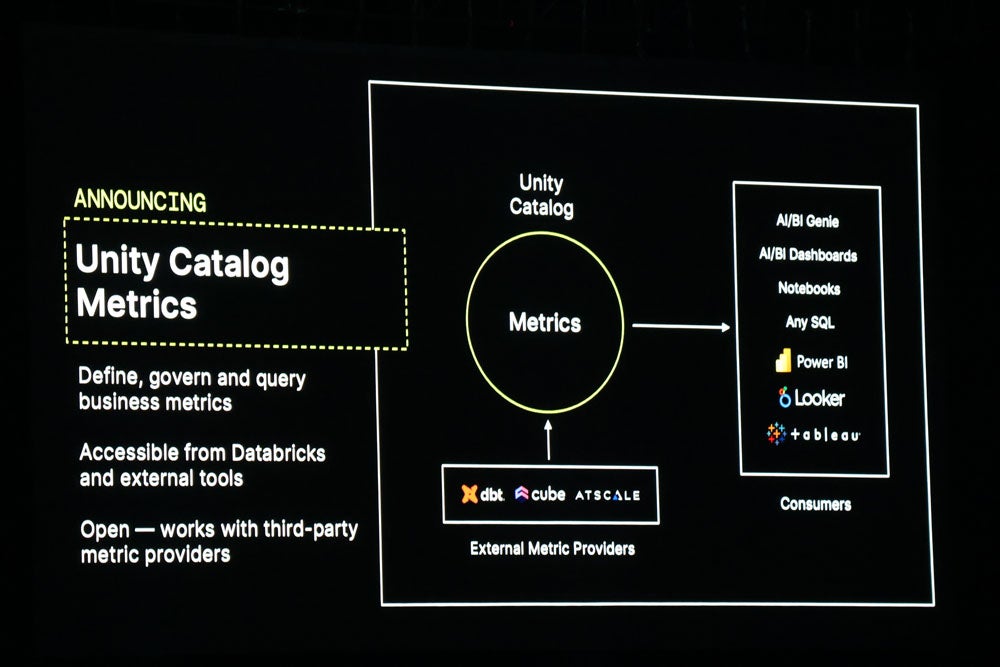
Unity Catalogの新機能「Metrics」の概要

現在、Unity Catalog OSSのパートナーはMicrosoft Azure、AWS(Amazon Web Services)、Google Cloud、Salesforce、NVIDIA、スタートアップなどだ。
ザハリア氏は「AIのリーディングカンパニーであるMicrosoft、Google Cloudとは緊密に連携し、Icebergに寄与してもらうとともに相互運用性を高める取り組みを実施しています」と、今後も引き続きUnity Catalogの機能拡張に注力していく姿勢を見せていた。













