


日本IBMは2月27日、オンラインで記者説明会を開き、AIとデータのプラットフォームである「IBM watsonx」で生成タスク用に設計された同社独自の基盤モデル「Granite」シリーズの1つとして、日本語性能を向上した「Granite日本語版モデル(granite-8b-japanese)」を、同29日(米国時間)から提供を開始することを発表した。
今後3年間における生成AIの経済効果は500兆円
説明会の冒頭、日本IBM 理事 テクノロジー事業本部 watsonx事業部長の竹田千恵氏は、昨今における生成AIの概況について「2023年は生成AIの話題が多く、当社ではAIファーストを打ち出した。今後3年間で生成AIがもたらすインパクトとして、経済効果は500兆円、80%の生産性改善が見込まれている。また、企業の80%がビジネスプロセスにAIを組み込み、70%のソフトウェアベンダーが自社のアプリケーションにAIを組み込むと予測されている」と述べた。
-

日本IBM 理事 テクノロジー事業本部 watsonx事業部長の竹田千恵氏

すでに提供している同社のwatsonxは、AIモデルのトレーニング、検証、チューニング、導入を行う「watsonx.ai」、あらゆる場所のさまざまなデータに対応してAIワークロードを拡大する「watsonx.data」、責任と透明性があり、説明可能なデータとAIのワークロードを実現する「watsonx.governance」の3つのコンポーネントで構成し、「Red Hat OpenShift」によりクラウド、オンプレミス、エッジ環境でも動かせるというものだ。
-
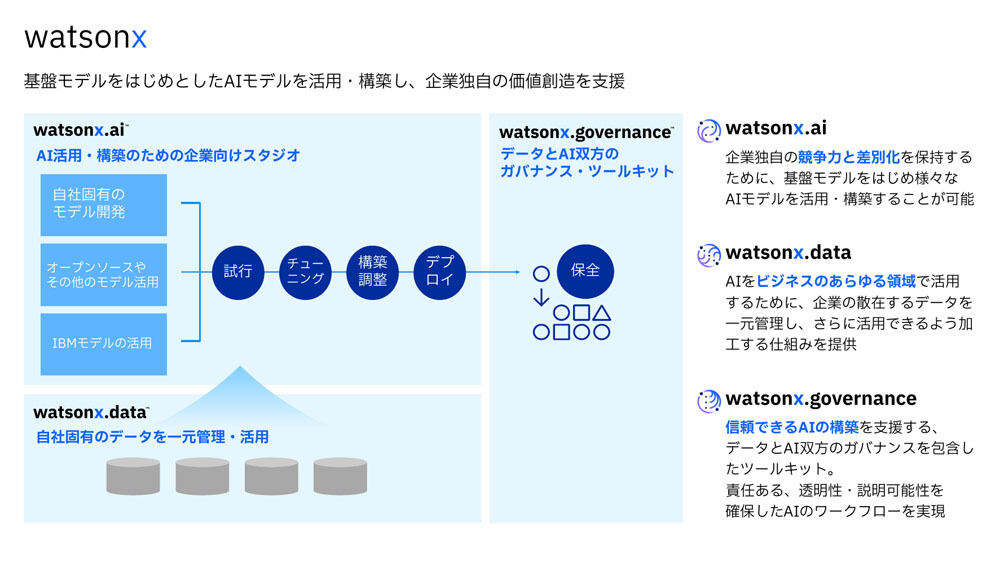
「IBM watsonx」の概要

ユースケースのトレンドとしては、営業領域における自然減でのやり取り、製造領域でのナレッジ活用、システム構築モダナイゼーションやIT運用を自動化するソフトウェア開発支援の3つの領域を一例として挙げている。
80億パラメータと軽量な「Granite日本語版モデル」
Graniteモデルは、生成タスク用に設計されたモデル。インターネット、学術、コード、法務、財務の5つの領域から得たビジネスに関連するデータセットで学習を行い、IBMがビジネス用途向けにキュレーションしている。
また、好ましくないコンテンツを除去するための検査、社内外のモデルとのベンチマーク評価も行っており、watsonx.dataとwatsonx.governanceとの連携により、リスクを軽減し、モデル出力が責任ある形で展開できるように設計されている。
今回、すでに提供開始している英語版Graniteモデルと同じ設計思想で、IBM Researchが新たに日本語、英語、コードのデータセットで学習し、日本語能力を備えた日本市場向けGraniteモデルを開発。
-

「Granite日本語版モデル(granite-8b-japanese)」の概要

日本語に特化した言語処理を導入することで、長い日本語の文章を効率的に処理するほか、高速な推論を実現するという。また、Granite日本語版モデルは80億のパラメーターモデルであり、高い精度を低いインフラストラクチャ要件で実現することを可能としている。
-

日本語学習データの前処理工程

Granite日本語版モデルについて、日本IBM 技術理事 東京基礎研究所AI Technologies担当シニア・マネージャーの倉田岳人氏は「1.6兆トークンの英語(1兆トークン)、日本語(5000億トークン)、コードデータ(1000億トークン)から学習し、日本語トークナイザーを導入しているため、バイト単位に分割されずに一般的な日本語文字、文字列は語彙に含まれる」と説く。
-

日本IBM 技術理事 東京基礎研究所AI Technologies担当シニア・マネージャーの倉田岳人氏

-

日本語トークナイザーを導入した

さらに、チューニングでさまざまなビジネスユースケースで利用を可能としており、技術仕様や学習データなどを公開し、透明性と責任あるAIを担保。日本語モデルについても学習データを含め公開し、提供開始後もフィードバックをもとに、さらなる改善を予定している。
-

日本語モデルでも学習データなど技術仕様を公開する

導入促進に向けた共創プログラムを用意
watsonx.aiでは、ビジネスに特化した同社独自の基盤モデルに加え、ユーザーのユースケースを想定したオープンソースモデルも用意。今年1月からは、日本市場向けに、ELYZAが公開した日本語LLMモデル「ELYZA-japanese-Llama-2-7b」も利用が可能となっている。
日本IBM テクノロジー事業本部 Data and AI エバンジェリストの田中孝氏は「現在、watsonx.aiはSaaS(Software as a Service)とソフトウェアで提供し、SaaSについては先日に東京リージョンでの提供を開始した。生成AIのユースケースを本番展開していくことに踏み出すのが2024年。パフォーマンスとコストはもちろん、日本語での利用や社外に公開していくためには顧客保護が必要になる。当社としては、手を打ちつつ料金体制の見直しをモデルの追加を引き続き行っていく」と説明していた。
-

日本IBM テクノロジー事業本部 Data and AI エバンジェリストの田中孝氏

なお、watsonxを活用してビジネスニーズに対応した生成AIソリューションを共同で策定し、迅速に実証するためIBMの複数分野にまたがるチームと専門知識を無償で提供。具体的には、アセスメントからブリーフィング、ワークショップ、PoV(Proof of Value:価値実証)までの共創プログラムを用意している。
-

共創プログラムの概要















