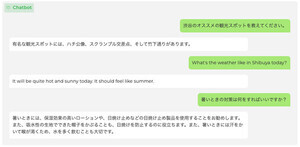
rinnaは12月21日、アリババが公開したQwen 7Bおよび14Bを用いた日本語継続事前学習モデル「Nekomata」シリーズを開発し、Tongyi Qianwen LICENSE AGREEMENTで公開したことを発表した。
Nekomata 7Bおよび14Bは、70億パラメータのQwen 7Bと140億パラメータのQwen 14Bに対して、日本語と英語の学習データを用いてそれぞれ300億または660億トークンで継続事前学習したモデル。
Qwenのパフォーマンスは日本語でも引き継いでおり、日本語のタスクにおいて高い性能を確認しているという。日本語言語モデルの性能を評価するためのベンチマークの一つである「Stability-AI / lm-evaluation-harness」の9タスク平均スコアは、Nekomata 7Bが58.69、Nekomata 14Bが67.38だった。
日本語テキストの1byteに対するトークン数はLlama2およびYouriが0.40であるのに対し、QwenおよびNekomataでは0.24であり、推論効率が高い。なお、モデル名の由来は妖怪の「猫又(ねこまた)」。
-
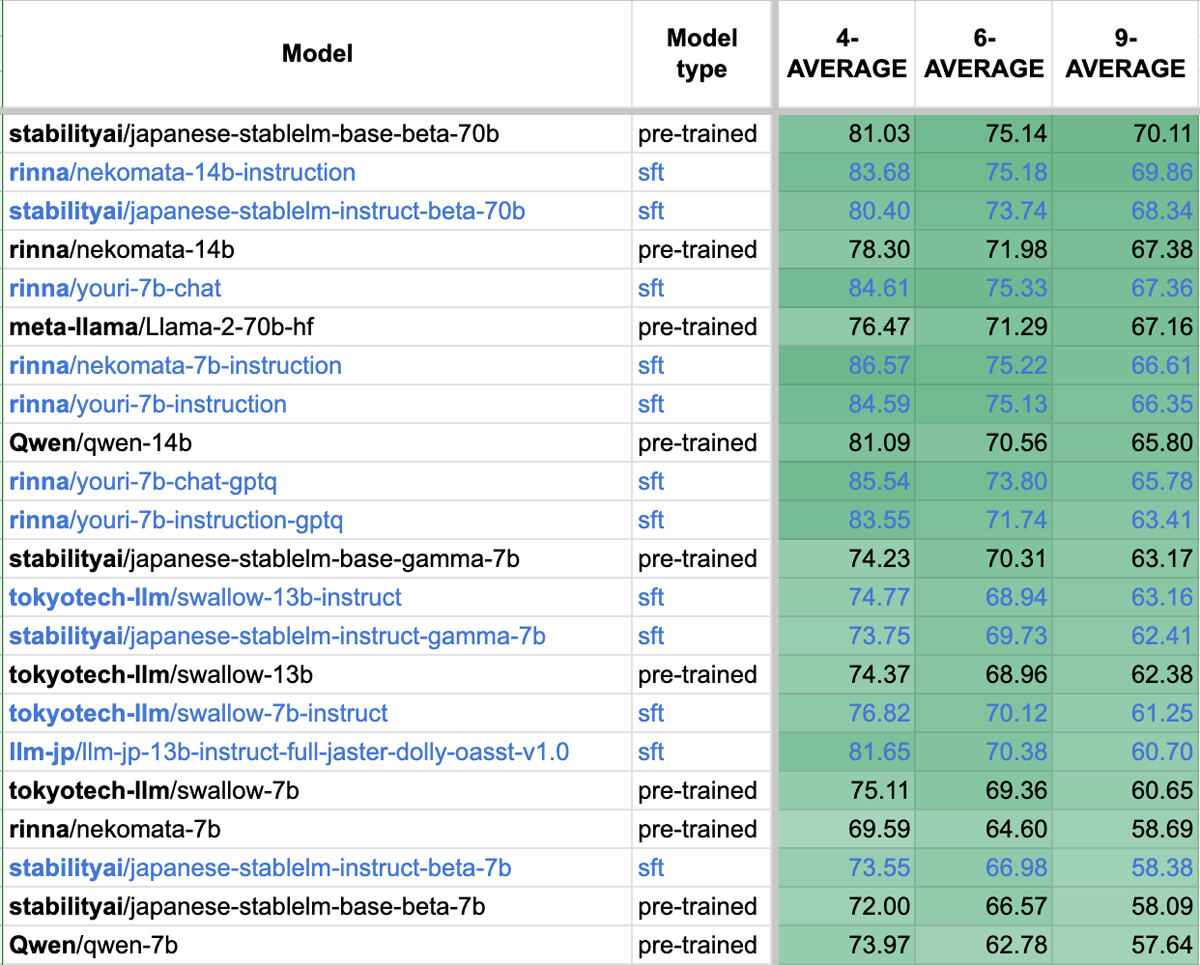
ベンチマークStability-AI/lm-evaluation-harnessのスコア