



情報通信研究機構(NICT)は7月4日、独自に収集した高品質な350GBの日本語Webテキストのみを用いて、400億パラメータの生成系の大規模言語モデル(生成AI)を開発したことを発表した。
同成果は、NICT ユニバーサルコミュニケーション研究所データ駆動知能システム研究センターの研究チームによるもの。
「ChatGPT」の登場以降、生成系言語モデルの有効性に大きな注目が集まっている。その開発力が他分野にも影響されると指摘されるほどにまで急速に変化してきているが、生成系言語モデルは、同時にハルシネーション(もっともらしいウソ)などの偽情報やバイアス、各種悪用のリスクも指摘されている。
NICTではこれまで、生成系言語モデルの研究開発を基礎研究と位置付け、大規模には実施してこなかったという。しかし日本における開発力強化が喫緊の課題となっていることから、本格的な開発に取り組むことにしたという。そこで今回の研究では、これまでNICTで構築してきた識別系言語モデルの学習に用いていた、ノイズに相当するテキストが少ない350GBの高品質な独自の日本語Webテキストを用いて、400億パラメータの生成系の大規模言語モデルを事前学習させ、その動作の検証を開始したとする。
-
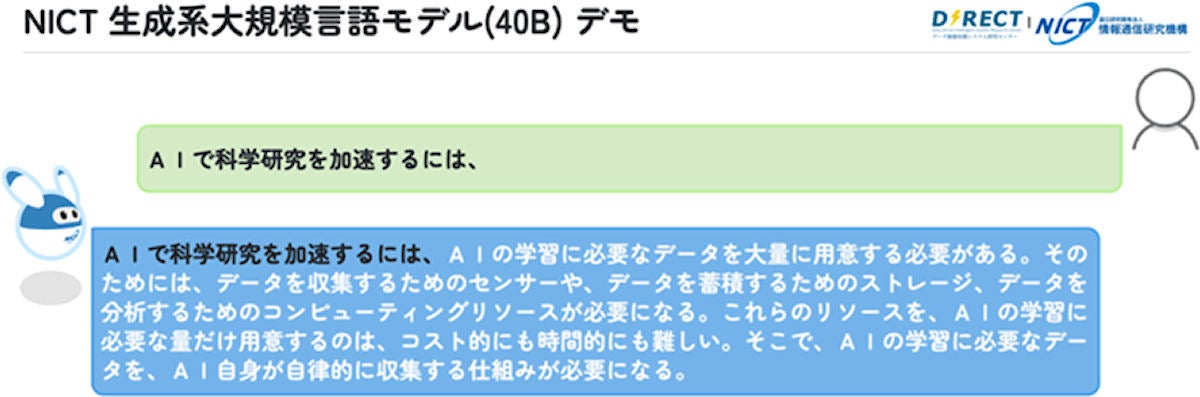
今回開発された大規模言語モデルプロトタイプの動作例。ユーザアイコンからの質問(入力)が緑の吹き出しに、日本語大規模言語モデルからの出力は、NICTのキャラクターである「人工知能“N”」からの青色の吹き出しに表示されている。なお、入力は内容が質問文として整っていないが、今後より整った形の質問文にも対応できるようにしていくという。(出所:NICT Webサイト)

今回の開発は、これまでのノウハウの蓄積もあり、ユーザインタフェースを含め4か月程度で完了したという。また今回は、学習の完了を優先させて事前学習を実施。ファインチューニングや強化学習は未実施であるため、短めの入出力、洗練されていない日本語表現など、性能面ではChatGPTなどと比較できるレベルではないものの、日本語でのやり取りが可能な水準に到達したとする。
具体的には、まだ要領を得ないテキストが出力されるケースが多々あるものの、各種質問への回答、要約、論文要旨の生成、翻訳などが可能なレベルになったという。加えて、存在しない映画の簡単なあらすじを生成するといった一種の創作ができる可能性も示されたとしている。
一方で、生成テキストの悪用の可能性を示唆する結果も得られており、今後、ポジティブ・ネガティブの両方の要素に関して改善を図っていく予定とした。












