具体的には、FeFET物理リザバー・コンピューティングの基礎的性能を向上させるため、従来方法のドレイン電流の時間応答による学習・推論に対して、FeFETのドレイン電流、ソース電流、基板電流という3つの電流の時間応答を組み合わせて学習・推論する方式が提案され、その有効性が実験的に示された。
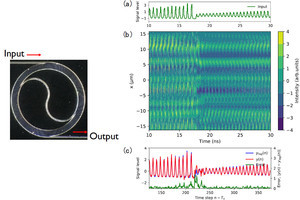
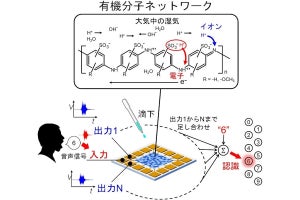
音声認識を例として、0から9までの数字の英語での音声発話に対して、数字を正しく認識することがタスクとされ、発話の音声データが複数の周波数に分割された時系列データとして扱われた。各周波数チャネルの時系列データをゲート電圧として、各々別のFeFETのゲート電極に入力して並列処理が行われ、各FeFETでの推論結果の多数決を取ることで推論を行う方式が提案された。音声発話を特徴的な周波数に分割し並列処理を行うことにより、高速の推論を可能にしたという。
-

音声数字認識タスクのためのFeFET物理リザバー・コンピューティングと、認識精度向上のためのアプローチの概念図 (出所:プレスリリースPDF)

また、この並列処理による音声認識の推論性能を高めるために、時系列データに対する電流応答を読み出す時間刻みの最適化を行うと共に、ゲート電極への入力として従来のデジタル入力からアナログ入力へ変更することで、認識精度が高まることが示されたとする。
さらに、異なる周波数チャネルから得られる電流応答の組み合わせ方を工夫することで、認識精度が向上することが見出され、周波数チャネルの組み合わせ方法の最適化が進められたほか、FeFETのドレイン電流、ソース電流、基板電流の電流の時間応答を用いる方法を組み合わせることによって、結果として、音声認識率の実験値として95.9%を達成したという。この認識率は、ソフトウェアを使ったリザバー・コンピューティングに匹敵する数値だという。
-

FeFET物理リザバー・コンピューティング方式の改良に伴う認識精度の向上と、直接線形回帰およびソフトウェアリザバーの結果との比較 (出所:プレスリリースPDF)

なお、今回の方式について研究チームでは、これまでのAI計算方式やAI計算のためのハードウェアと比べて、極低消費電力性やリアルタイム処理などの点で、高水準な性能を期待できるとしているほか、今回の方式を組み込んだAIチップは、今後の人工知能活用社会を支えるAIハードウェア技術や、AIシステム技術の革新へ向けた有力な選択肢となることが考えられるとしている。