日本電信電話(NTT)は6月2日、どのような条件で取得されたデータであるかがまったくわからない寄せ集めの学習データからであっても、認識モデルを学習可能な深層学習技術を実現したと発表した。
さまざまな取得条件が混在し、また、その条件が完全に未知な学習データに対し、データごとの取得条件の違いを教師なし学習によって推定することで、その影響を受けずに高精度な認識モデルを学習可能な深層学習技術を実現したという。
これまでは、各取得条件に特化した認識モデルを学習し、それらを組み合わせる技術や、取得条件の違いによるデータの分布の差を小さくするように学習することで、取得条件の影響を受けない認識モデルを学習する技術などが検討されてきたが、これらの既存技術はいずれも、事前に各データの取得条件がわかっている場合にしか利用できないものだったという。
-

学習データとテストデータの"ずれ"による認識精度の低下

一方、今回の技術では、データごとの取得条件の違いを明らかにする新たなデータ拡張技術(元のデータに対して単純な改変(拡大縮小や一部領域の切り出しなど)を施すことで、新しいデータを生成する技術)を考案し、このデータ拡張技術を用いると、データを取得条件の違いによって教師なしで分類できるようになり、取得条件が完全に未知な寄せ集めのデータからでも、高精度な認識モデルを学習することが可能だという。
-
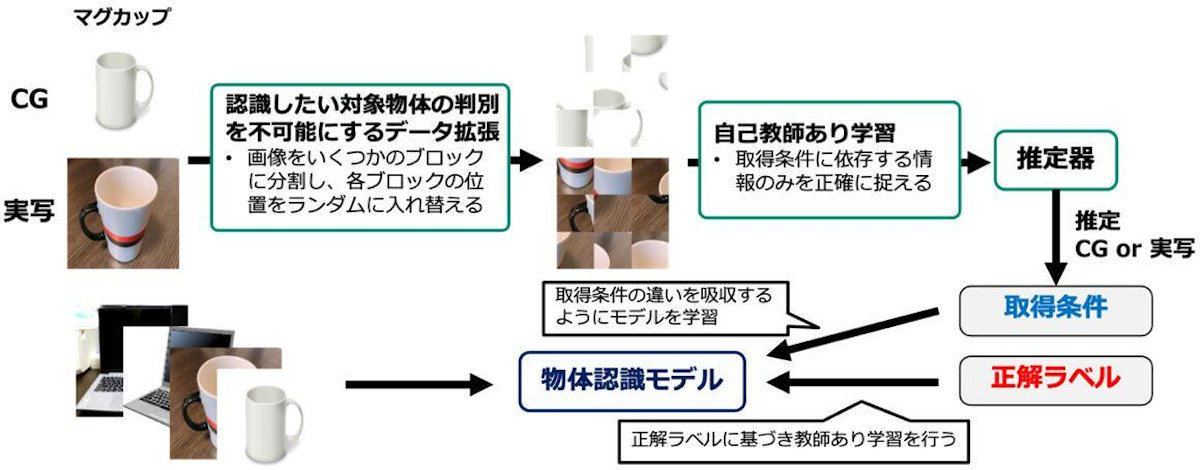
本成果によるデータ拡張技術と提案技術による学習の流れ

同社では、実際に、異なる取得条件が混在する特定のデータを用いて評価した場合、従来技術が3.6%の認識精度であったところ、本技術は77.4%と、大幅に上回る認識精度を達成するなど、取得条件の影響を受けない認識モデルを学習できることを複数のデータで確認しているという。
今後は、本成果で創出した、認識したい対象物体を判別不可能にするデータ拡張によって、取得条件の違いを分類する技術は、多くの映像情報メディアで有効であることが期待できるという。